Download presentation
Presentation is loading. Please wait.

1
Multimedia Database Systems Relevance Feedback Department of Informatics Aristotle University of Thessaloniki Fall 2008

2
Outline Motivation for Relevance Feedback (RF) Introduction to RF RF techniques in Image Databases (5 techniques are studied) Other RF techniques Conclusions Bibliography
 Introduction to RF RF techniques in Image Databases (5 techniques are studied) Other RF techniques Conclusions Bibliography")
3
Motivation Initial work on content-based retrieval focused on using low-level features like color and texture for image representation. After each image is associated with a feature vector, similarity between images is measured by computing distances between feature vectors in the feature space. It is generally assumed that the features are able to locate visually similar images close to each other in the feature space so that non-parametric approaches, like the k-nearest neighbor search, can be used for retrieval.

4
Motivation There are cases where the user is not satisfied by the answers returned. Several relevant objects may not be retrieved or in addition to the relevant objects there are a lot of non-relevant ones. Possible solutions: –Request more answers (e.g., next 10) –Rephrase and reexecute the query –Relevance feedback
 –Rephrase and reexecute the query –Relevance feedback.")
5
A Possible Solution: RF Take advantage of user relevance judgments in the retrieval process: –User issues a query and gets back an initial hit list –User marks hits as relevant or non-relevant –The system computes a better representation of the information need based on this feedback –This process can be repeated more than once. Idea: you may not know what you’re looking for, but you’ll know when you see it.

6
Forms of RF Explicit feedback: users explicitly mark relevant and irrelevant documents Implicit feedback: system attempts to infer user intentions based on observable behavior Blind feedback (also known as pseudofeedback): feedback in absence of any evidence, explicit or otherwise
: feedback in absence of any evidence, explicit or otherwise")
7
The Goal of RF x x x x o o o Revised query x non-relevant objects o relevant objects o o o x x x x x x x x x x x x x x Initial query x

8
RF in Text Retrieval RF was originally proposed for text-based information retrieval. The goal is to improve the quality of the returned documents. Fundamental work: Rocchio

9
Rocchio Method Used in practice: New query –Moves toward relevant objects –Away from irrelevant objects q m = modified query vector; q 0 = original query vector; α,β,γ: weights (hand-chosen or set empirically); D r = set of known relevant doc vectors; D nr = set of known irrelevant doc vectors
; D r = set of known relevant doc vectors; D nr = set of known irrelevant doc vectors")
10
Rocchio Example 040800 124001 201104 6370-3 040800 248002 8044016 Original query Positive Feedback Negative feedback (+) (-) New query Typically, <
 (-) New query Typically, < ")
11
RF Example

12
RF Example: initial results

13
RF Example: user selection

14
RF Example: revised results

15
RF Example: alternative interface

16
Some RF Techniques 1.Yong Rui, Thomas S. Huang and Sharad Mehrotra. “Content-Based Image Retrieval with Relevance Feedback in MARS”, International Conference on Image Processing (ICIP), 1997. 2.Selim Aksoy, Robert M. Haralick, Faouzi A. Cheikh, Moncef Gabbouj. “A Weighted Distance Approach to Relevance Feedback”, International Conference on Pattern Recognition (ICPR), 2000. 3.Zhong Su, Hongjiang Zhang, Stan Li, and Shaoping Ma. “Relevance Feedback in Content-Based Image Retrieval: Bayesian Framework, Feature Subspaces, and Progressive Learning”, IEEE Transactions on Image Processing, 2003. 4.DeokHwan Kim, ChinWan Chung. “Qcluster: Relevance Feedback Using Adaptive Clustering for ContentBased Image Retrieval”, SIGMOD, 2003. 5.Junqi Zhang Xiangdong Zhou Wei Wang Baile Shi1 Jian Pei. “Using High Dimensional Indexes to Support Relevance Feedback Based Interactive Images Retrieval”, VLDB, 2006.
, Selim Aksoy, Robert M. Haralick, Faouzi A. Cheikh, Moncef Gabbouj. A Weighted Distance Approach to Relevance Feedback , International Conference on Pattern Recognition (ICPR), Zhong Su, Hongjiang Zhang, Stan Li, and Shaoping Ma. Relevance Feedback in Content-Based Image Retrieval: Bayesian Framework, Feature Subspaces, and Progressive Learning , IEEE Transactions on Image Processing, DeokHwan Kim, ChinWan Chung. Qcluster: Relevance Feedback Using Adaptive Clustering for ContentBased Image Retrieval , SIGMOD, Junqi Zhang Xiangdong Zhou Wei Wang Baile Shi1 Jian Pei. Using High Dimensional Indexes to Support Relevance Feedback Based Interactive Images Retrieval , VLDB,")
17
CBIR with RF in MARS There is an urgent need to develop integration mechanisms to link the image retrieval model to text retrieval model, such that the well established text retrieval techniques can be utilized. This paper studies approaches of converting image feature vectors (Image Processing domain) to weighted-term vectors (IR domain). Furthermore, the relevance feedback technique from the IR domain is used in content-based image retrieval to demonstrate the effectiveness of this conversion. Experimental results show that the image retrieval precision increases considerably by using the proposed integration approach. The method has been implemented in the MARS prototype system developed at the University of Illinois @ Urbana Campaign.
 to weighted-term vectors (IR domain). Furthermore, the relevance feedback technique from the IR domain is used in content-based image retrieval to demonstrate the effectiveness of this conversion. Experimental results show that the image retrieval precision increases considerably by using the proposed integration approach. The method has been implemented in the MARS prototype system developed at the University of Urbana Campaign..")
18
Weighted Distance Approach Selim Aksoy, Robert M. Haralick, Faouzi A. Cheikh, Moncef Gabbouj. A Weighted Distance Approach to Relevance Feedback, Proceedings of International Conference on Pattern Recognition (ICPR), 2000.
,")
19
Weighted Distance Approach number of iterations number of features in feature vector retrieval set after the k-th iteration set of objects inmarked as relevant values of the j-th feature component of images in

20
Weighted Distance Approach The similarity between images is measured by computing distances between feature vectors in the feature space. Given two feature vectors x and y and the weight vector w, we use the weighted distances L 1 or L 2 :

21
Weighted Distance Approach From the pattern recognition point of view, for a feature to be good, its variance among all the images in the database should be large but its variance among the relevant images should be small. Any one of these is not enough alone but characterizes a good feature when combined with the other.

22
Weighted Distance Approach Let denote the weight of the j-th feature component in the k+1 iteration. This weight is given by the following equation: where:

23
Weighted Distance Approach According to the values of and there are four different cases: best case worst case

24
Weighted Distance Approach Case 1 When is large and is small, becomes large. This means that the feature has a diverse set of values in the database but its values for relevant images are similar. This is a desired situation and shows that this feature is very effective in distinguishing this specific relevant image set, so a large weight assigns more importance to this feature.

25
Weighted Distance Approach Case 2 When both and are large, is close to 1. This means that the feature may have good discrimination characteristics in the database but is not effective for this specific relevant image group. The resulting weight does not give any particular importance to this feature.

26
Weighted Distance Approach Case 3 When both and are small, is again close to 1. This is a similar but slightly worse situation than the previous one. The feature is not generally effective in the database and is not effective for this relevant set either. No importance is given to this feature.

27
Weighted Distance Approach Case 4 When is small and is large, becomes small. This is the worst case among all the possibilities. The feature is not generally effective and even causes the distance between relevant images to increase. A small weight forces the distance measure to ignore the effect of this feature.

28
Weighted Distance Approach Retrieval Algorithm [1] initialize all weights uniformly. [2] compute j = 1, 2, …, Q. [3] for k = 1, k <= K, k++ - search the DB using and retrieve - get feedback from user and populate - compute j = 1, 2, …, Q - normalize j = 1, 2,..., Q
![Weighted Distance Approach Retrieval Algorithm [1] initialize all weights uniformly.](http://images.slideplayer.com/14/4241030/slides/slide_28.jpg "[2] compute j = 1, 2, …, Q. [3] for k = 1, k <= K, k++ - search the DB using and retrieve - get feedback from user and populate - compute j = 1, 2, …, Q - normalize j = 1, 2,..., Q.")
29
Weighted Distance Approach Precision results

30
Weighted Distance Approach Precision results

31
Bayesian Classification: a short tutorial The problem of classification Given a number of classes and an unclassified object x determine the class that x belongs to. Examples: given the age and the income of a person determine if she will buy a laptop or not given the color, type and origin of car determine if it will be stolen given the age, income and job of a person determine if the bank will give a loan or not. In Bayesian Classification we use probabilities to determine the “best” class to assign a new item.

32
Bayesian Classification: a short tutorial Bayes Theorem P(h)prior probability of hypothesis h P(x)evidence of training data x P(h | x)probability of h given x (posterior probability) P(x | h)probability of x given h (likelihood) x data item h hypothesis
prior probability of hypothesis h P(x)evidence of training data x P(h | x)probability of h given x (posterior probability) P(x | h)probability of x given h (likelihood) x data item h hypothesis")
33
Bayesian Classification: a short tutorial Each data item x is composed of several attributes. In our example we are interested in determining if a car with specific characteristics will be stolen or not. Car attributes: color, type and origin. Given a color, type, origin triplet we are interested in determining if the car will be stolen or not. (Thanks to Eric Meisner for this example)
.")
34
Bayesian Classification: a short tutorial Training data

35
Bayesian Classification: a short tutorial Naive Bayesian Classification It is evident that each data item has several attributes (color, type, origin in our example). To calculate P(x | h) we use the independence assumption among different attributes. Therefore:
 we use the independence assumption among different attributes. Therefore:.")
36
Bayesian Classification: a short tutorial The number of available classes are known. For each class ω i a discriminant function g i (x) is defined. Item x is assigned to the k-th class when g k (x) > g j (x) for all j <> k. In Bayesian Classification g i (x) is set to P(ω i | x).
 is defined. Item x is assigned to the k-th class when g k (x) > g j (x) for all j <> k. In Bayesian Classification g i (x) is set to P(ω i | x)..")
37
Bayesian Classification: a short tutorial Since for an item x the value of P(x) does not depend on the class, it can be eliminated without affecting the class ranking. Logarithms may also be used as follows: (e.g., with Gaussian classifiers)
.")
38
Bayesian Classification: a short tutorial h 1 : the car will be stolen (1 st hypothesis) h 2 : the car will NOT be stolen (2 nd hypothesis) x: a red domestic sports car (color=“red”, type=“sports”, origin=“domestic”) Determine if the car will be stolen or not by using a Naive Bayesian Classifier.
 h 2 : the car will NOT be stolen (2 nd hypothesis) x: a red domestic sports car (color= red , type= sports , origin= domestic ) Determine if the car will be stolen or not by using a Naive Bayesian Classifier.")
39
Bayesian Classification: a short tutorial We need to calculate the following quantities: P(h 1 ) : probability that a car will be stolen regardless of color, type and origin (prior probability) P(h 2 ) : probability that a car will not be stolen regardless of color, type and origin (prior probability) P(x) : probability that a car from our set of cars is a red domestic sports car (evidence) P(x | h 1 ) : probability that the car has a red color, it is domestic and it is a sports car, given that it is stolen (likelihood) P(x | h 2 ) : probability that the car has a red color, it is domestic and it is a sports, given that it is not stolen (likelihood) P(h 1 | x): probability that car x will be stolen given that we know its color, type and origin (posterior probability). P(h 2 | x): probability that car x will not be stolen given that we know its color, type and origin (posterior probability).
: probability that car x will not be stolen given that we know its color, type and origin (posterior probability)..")
40
Bayesian Classification: a short tutorial P(h 1 ) = 5/10 = 0.5 P(h 2 ) = 5/10 = 0.5 P(x) = 2/10 = 0.2 P(x | h1) = P(color=“red” | h1) x P(type=“sports” | h1) x P(origin=“domestic” | h1) = = 3/5 x 4/5 x 2/5 = 0.192 P(x | h2) = P(color=“red” | h2) x P(type=“sports” | h2) x P(origin=“domestic” | h2) = = 2/5 x 2/5 x 3/5 = 0.096 We need to calculate P(h 1 | x) and P(h 2 | x)
 = 5/10 = 0.5 P(h 2 ) = 5/10 = 0.5 P(x) = 2/10 = 0.2 P(x | h1) = P(color= red | h1) x P(type= sports | h1) x P(origin= domestic | h1) = = 3/5 x 4/5 x 2/5 = P(x | h2) = P(color= red | h2) x P(type= sports | h2) x P(origin= domestic | h2) = = 2/5 x 2/5 x 3/5 = We need to calculate P(h 1 | x) and P(h 2 | x)")
41
Bayesian Classification: a short tutorial By substitution and calculations we get: Since 0.096 > 0.048 we conclude that probably the car will be stolen.

42
RF with Bayesian Estimation Zhong Su, Hongjiang Zhang, Stan Li, and Shaoping Ma. “Relevance Feedback in Content- Based Image Retrieval: Bayesian Framework, Feature Subspaces, and Progressive Learning”, IEEE Transactions on Image Processing, 2003.

43
RF with Bayesian Estimation In the proposed relevance feedback approach, positive and negative feedback examples are incorporated in the query refinement process with different strategies. To incorporate positive feedback in refining image retrieval, we assume that all of the positive examples in a feedback iteration belong to the same semantic class whose features follow a Gaussian distribution. Features of all positive examples are used to calculate and update the parameters of its corresponding semantic Gaussian class and we use a Bayesian classifier to re- rank the images in the database. To incorporate negative feedback examples, we apply a penalty function in calculating the final ranking of an image to the query image. That is, if an image is similar to a negative example, its rank will be decreased depending on the degree of the similarity to the negative example.

44
RF with Bayesian Estimation Low-level features used

45
Classifier Details The Gaussian density is often used for characterizing probability because of its computational tractability and the fact that it adequately models a large number of cases. The probability density function of the Gaussian distribution is: )()( 2 1 2/1 2/ 1 ||2 1 xx d t ep(x)p(x) 2 1 2 2 1 )( x exp univariate (x assumes single values) multivariate (x is a vector) x: variable μ: mean σ: standard deviation x: variable d: dimensionality μ: mean Σ: d x d cov matrix |Σ|: determinant of Σ
()( 2 1 2/1 2/ 1 ||2 1 xx d t ep(x)p(x) )( x exp univariate (x assumes single values) multivariate (x is a vector) x: variable μ: mean σ: standard deviation x: variable d: dimensionality μ: mean Σ: d x d cov matrix |Σ|: determinant of Σ.")
46
Classifier Details Recall the classifier functions: Assuming the measurements are normally distributed, we have: By substitution we get: )(ln|| 2 1 )()( 2 1 )( 1 iiii t ii Pxxxg
(ln|| 2 1 )()( 2 1 )( 1 iiii t ii Pxxxg ")
47
Positive Feedback D collection of images in the database n number of positive examples Q query image m number of feature types used feature vector for the i-th feature type dimensionality of the i-th feature type An image is represented as a vector

48
Positive Feedback Each feature type is Gaussian distributed. is the n i x n i covariance matrix is the n i dimensional mean vector

49
Positive Feedback It is reasonable to assume that all the positive examples belong to the class of images containing the desired object or semantic meaning and the features of images belonging to the semantic classes obey the Gaussian distribution. The parameters for a semantic Gaussian class can be estimated using the feature vectors of all the positive examples. Hence, the image retrieval becomes a process of estimating the probability of belonging to a semantic class and the query refinement by relevance feedback becomes a process of updating the Gaussian distribution parameters.

50
Positive Feedback U: the set of positive examples in the current iteration |U|: number of positive examples in the current iteration u: an item in U The update of the Gaussian parameters is performed as follows: n, n’: total number of positive examples accumulated before and after the iteration

51
Positive Feedback Algorithm [1] Feature normalization. [2] Initialize: n = 1, = I, = [3] User provides feedback and selects positive examples (set U). [4] Update of retrieval parameters n,, [5] For image X in the database calculate the value of the discriminant function g i (x). [6] A new ranking is returned to the user.
![Positive Feedback Algorithm [1] Feature normalization.](http://images.slideplayer.com/14/4241030/slides/slide_51.jpg "[2] Initialize: n = 1, = I, = [3] User provides feedback and selects positive examples (set U). [4] Update of retrieval parameters n,, [5] For image X in the database calculate the value of the discriminant function g i (x). [6] A new ranking is returned to the user..")
52
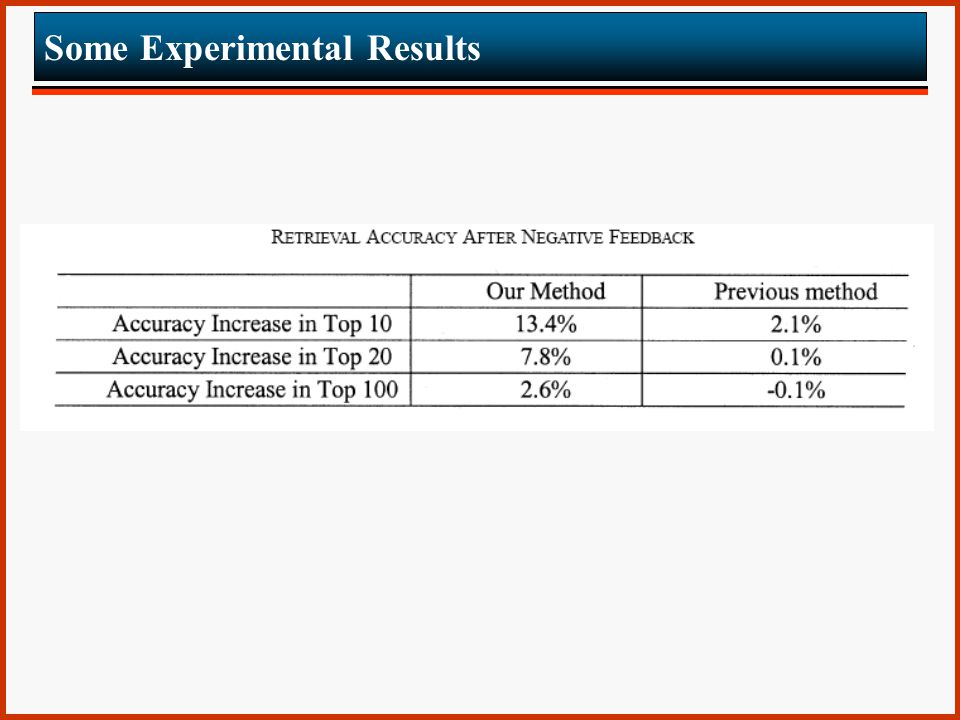
Negative Feedback Negative examples are treated differently than positive ones. Negative examples are often isolated and treated independently. Only images near the negative examples are punished. The rest are not affected. The penalty involves the increase of the distance by a constant factor (details in the paper).
..")
53
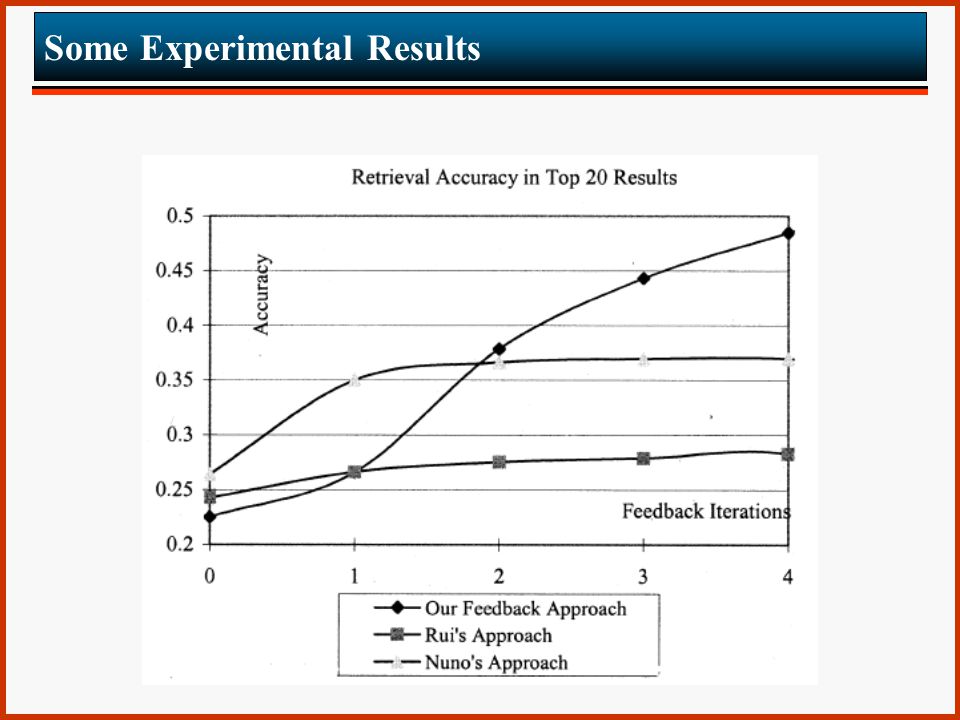
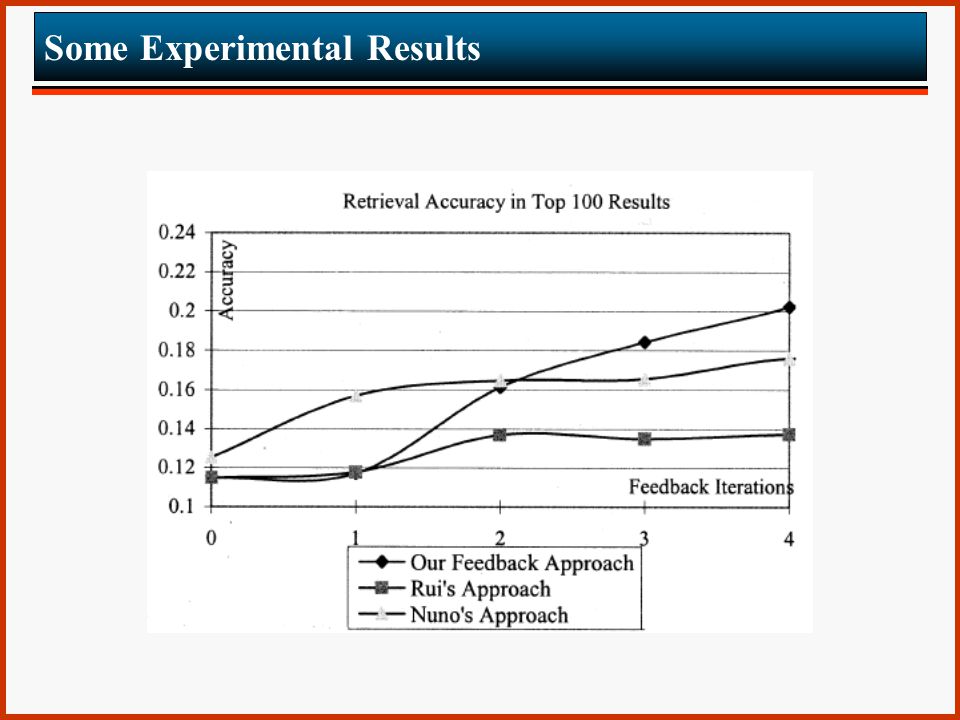
Some Experimental Results Corel image gallery has been used 10,000 images of 79 semantic categories have been selected The proposed techniques has been compared to two previously proposed ones, termed Nuno’s approach and Rui’s approach (see bibliography) The measurement of interest is the accuracy which is defined as follows: accuracy = relevant images in top-k k
 The measurement of interest is the accuracy which is defined as follows: accuracy = relevant images in top-k k")
54
Some Experimental Results

58
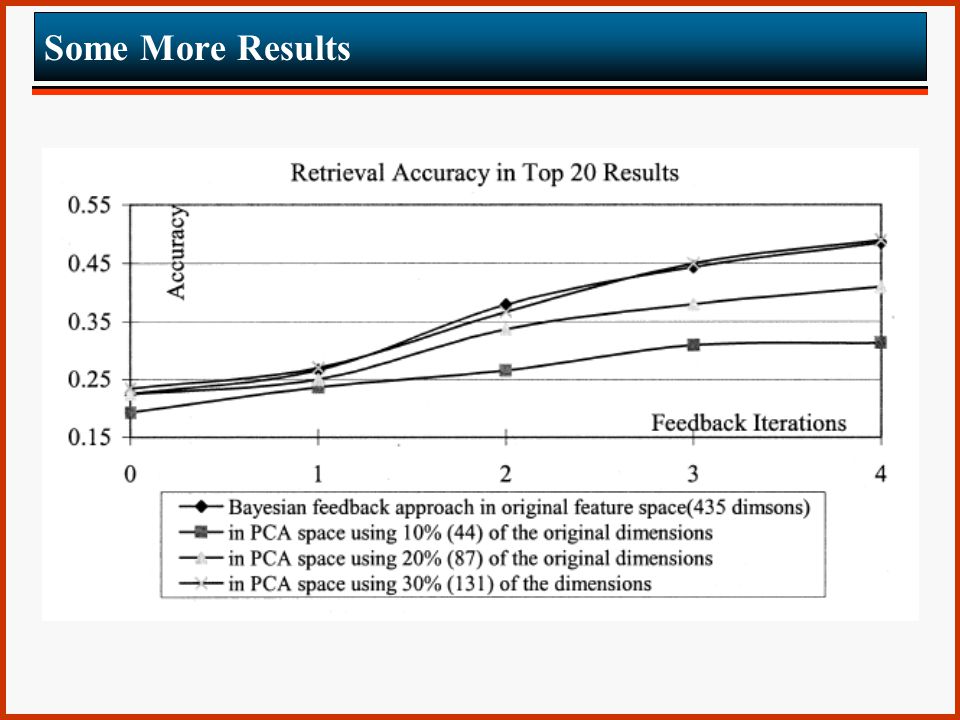
PCA Feature Subspaces The other major contribution in the proposed relevance feedback approach to content-based image retrieval is to apply the principal component analysis (PCA) technique to select and updated a proper feature subspace during the feedback process. This algorithm extracts more effective, lower- dimensional features from the originally given ones, by constructing proper feature subspaces from the original spaces, to improve the retrieval performance in terms of speed, storage requirement and accuracy.

59
Some More Results

Similar presentations





 and the class- conditional probabilities P(x|wi)>")









 by R. O. Duda, P. E. Hart and D. G. Stork, John.>")




