Download presentation
Presentation is loading. Please wait.

1
LIS618 lecture 6 Thomas Krichel 2003-10-26

2
Structure Probabilistic model News from the front line –Open WorldCat Pilot –Amazon Search Inside the book

3
probabilistic model (outline only) starts with the assumption that there is a subset of documents that form the ideal answer set query process specifies properties of the answer set query terms can be used to form a probability that a document is part of the answer then we start an iterative process with the user to gain more characteristics about the answer set
 starts with the assumption that there is a subset of documents that form the ideal answer set query process specifies properties of the answer set query terms can be used to form a probability that a document is part of the answer then we start an iterative process with the user to gain more characteristics about the answer set")
4
recursive method The similarity of the document to the query can be expressed as s=(probability that the document is part of the answer set / probability that it is not part of the answer set). If we assume that the probability that the documents that are relevant among a set of initially retrieved documents is proportional to the appearance of index terms that are part of the query, the probability can further be refined.

5
OpenWorldCat pilot Aims –to increase the visibility of library collections to current and potential patrons –to enhance the image of libraries to administrators and funding agencies –improve the quality of material accessible from the Web Pilot ends June 2004

6
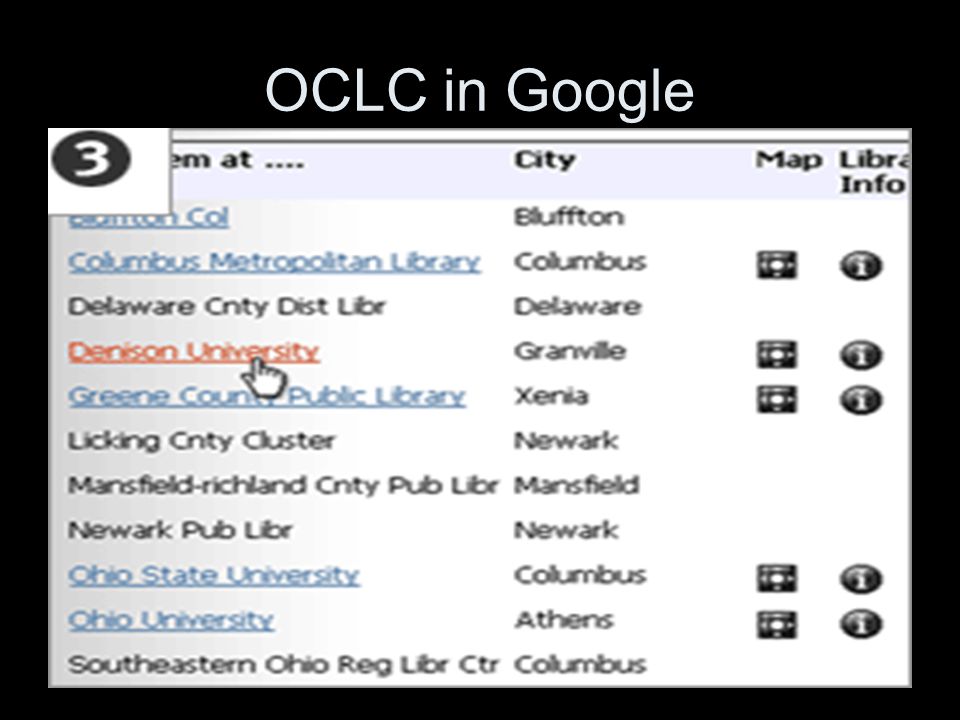
OCLC and Google OCLC have offered 2 Million out of the 53 Million records of wordcat to Google for indexing. Only popular records with a minimum of 100 libraries holding them. Applies only to the 12k academic, public and school libraries that contribute to WorldCat. Others have to ask to participate.

7
OCLC in Google

10
Problem of project Too thin page ranking Too thin contents Too little, much to late? Google is working on a project to allow full-text access to book. Currently they have agreements for 60,000 books.

11
Amazon search inside the book Access via any Amazon search box and enter your search terms. Implied and, phrase searching seems not to work A typical list of titles is returned. However, some titles contain extra information and links. They appear directly below the pricing information and begin with the word "exerpt.“ Click here and you'll see a scanned image of the page with your search term(s) highlighted. You'll need to be registered with Amazon.Com to access the full-text. Amazon is using optical character recognition technology to find words embedded in the scanned images.
 highlighted. You ll need to be registered with Amazon.Com to access the full-text. Amazon is using optical character recognition technology to find words embedded in the scanned images..")
12
Amazon search inside the book Search amazon.com for “radstock coal” Two books with excerpts. You could either get the book from amazon Or you could take the reference and search if can be found in a library near you, with the previous Google service. OpenURL technology may be helpful.

13
OpenURL Example Andy Powell has built an OpenURL based link resolver at http://www.ukoln.ac.uk/distributed- systems/openurl/orlet/ http://www.ukoln.ac.uk/distributed- systems/openurl/orlet/ Click on Go. Put this link onto the link bar. Then open a new amazon query When an interesting book is found, resolve it through the resolver.

14
ISBN in Amazon Resolver works beause amazon URL has isbn encoded… If amazon find that their service is used to find books in a library, they will not be pleased. But removing the ISBN will also remove the chance of others linking to Amazon to say “buy the book there”. Use of the full-text search could also be made via the SOAP API of Amazon, to build an integrated system.

15
Authors to loose out? The authors guild of america has appealed to members to block their works being searchable. They are especially concerned for –reference works –cook and travel books Some publishers say that they will not accept blocking requests.

16
http://openlib.org/home/krichel Thank you for your attention!

Similar presentations











 April 21 st, 2006 UML Reference Forum.>")








