Download presentation
Presentation is loading. Please wait.

1
Structured SVM Chen-Tse Tsai and Siddharth Gupta

2
Outline Introduction to SVM Large Margin Methods for Structured and Interdependent Output Variables (Tsochantaridis et. al., 2005) Max-Margin Markov Networks (Taskar et. al., 2003) Learning Structural SVMs with Latent Variables (Yu and Joachims, 2009) 2
 Max-Margin Markov Networks (Taskar et. al., 2003) Learning Structural SVMs with Latent Variables (Yu and Joachims, 2009) 2.")
3
SVM- The main idea

4
Maximum margin Find w and b such that is maximized and for all (x i, y i ), i=1..n : y i (w T x i + b) ≥ 1 Find w and b such that Φ(w) = ||w|| 2 =w T w is minimized and for all (x i, y i ), i=1..n : y i (w T x i + b) ≥ 1 quadratic optimization problem r ρ
, i=1..n : y i (w T x i + b) ≥ 1 Find w and b such that Φ(w) = ||w|| 2 =w T w is minimized and for all (x i, y i ), i=1..n : y i (w T x i + b) ≥ 1 quadratic optimization problem r ρ")
5
Binary SVM Training examples: Primal form: Dual form:

6
Multiclass SVM

7
Structured Output Approach: view as multi-class classification task Every complex output is one class Problems: Exponentially many classes How to predict efficiently? How to learn efficiently? Potentially huge model Manageable number of features? The dog chased the cat x S VPNP DetNV NP DetN y2y2 S VP DetNV NP VN y1y1 S VP DetNV NP DetN ykyk … 7

8
Multi-Class SVM (Crammer & Singer, 2001) Training Examples: Inference: Training: Find that solve 8
 Training Examples: Inference: Training: Find that solve 8")
9
Multi-Class SVM (Crammer & Singer, 2001) The dog chased the cat x S VPNP DetNV NP DetN y1y1 S VP DetNV NP VN y2y2 S VP NP y 58 S VPNP DetNV NP DetN y 12 S VPNP DetNV NP DetN y 34 S VPNP DetNV NP DetN y4y4 9
 The dog chased the cat x S VPNP DetNV NP DetN y1y1 S VP DetNV NP VN y2y2 S VP NP y 58 S VPNP DetNV NP DetN y 12 S VPNP DetNV NP DetN y 34 S VPNP DetNV NP DetN y4y4 9")
10
Joint Feature Map Problem: exponential number of parameters Feature vector that describes match between x and y Learn single weight vector. Inference The dog chased the cat x S VPNP DetNV NP DetN y1y1 S VP DetNV NP VN y2y2 S VP DetNV NP DetN y 58 S VPNP DetNV NP DetN y 12 S VPNP DetNV NP DetN y 34 S VPNP DetNV NP DetN y4y4 10

11
Joint Feature Map for Trees Weighted Context Free Grammar Each rule has a weight Score of a tree is the sum of its weight Find highest scoring tree Using CKY Parser The dog chased the cat S VPNP DetNV NP DetN Thecatthechaseddog x y 11

12
Structured SVM Hard margin … 12

13
Structured SVM Soft Margin SVM 1 SVM 2 13

14
General Loss Function measures the difference between prediction y, and the true value y i. The y with high loss should be penalized more severely. Slack re-scaling Margin re-scaling 14

15
A Cutting Plane Algorithm Only polynomial number of constraints are needed. 15

16
A Cutting Plane Algorithm Cutting plane algorithm 16

17
Computational problem Prediction: Get the most violated constraint: Approximate inference methods in MRF Training Structural SVMs when Exact Inference is Intractable. T. Finley, T. Joachims, ICML 2008 17

18
Outline Large Margin Methods for Structured and Interdependent Output Variables (Tsochantaridis et. al., 2005) Max-Margin Markov Networks (Taskar et. al., 2003) Learning Structural SVMs with Latent Variables (Yu and Joachims, 2009) 18
 Max-Margin Markov Networks (Taskar et. al., 2003) Learning Structural SVMs with Latent Variables (Yu and Joachims, 2009) 18.")
19
Max-Margin Markov Network Structured SVM entails a large number of constraints So far, handled by adding one constraint a time M 3 network A way to solve SVM 1 with margin re-scaling Use Markov network to encode dependency and generate features Reduce exponential to polynomial number of constraints. 19

20
M 3 Network A way to generate features. Define features on the edges The k-th feature of this instance The loss function 20

21
M 3 Network A way to solve SVM 1 with margin re-scaling Primal: Dual: Only need node and edge marginal probability to compute expectation 21

22
Polynomial-Size Reformulation The key step 22 y0y0 y1y1 y2y2 Δt x (y)α x (y) All possible y 11110.1 1102 1010 1001 0112 01030.2 0011 00020.1 Gold y101 µ x (0)0.60.5 µ x (1)0.40.5
α x (y) All possible y Gold y101 µ x (0) µ x (1)0.40.5")
23
Polynomial-Size Reformulation The key step Marginal dual variables New constraints Tree structure: 23

24
Polynomial-Size Reformulation Factored dual QP #variables and #constraints: N2 M down to N(M 2 +M) N: number of instances, M: the length of y Problem If the structure is not simple, we may need exponential number of new constraints Enforce only local consistency of marginals, get an approximate result 24
 N: number of instances, M: the length of y Problem If the structure is not simple, we may need exponential number of new constraints Enforce only local consistency of marginals, get an approximate result 24")
25
SMO Sequential minimal optimization In binary SVM, we have a linear constraint Working set selection: select the two variables to update M 3 net: 25

26
Experimental Results Max-Margin Parsing (Taskar et. al, 2004) Apply M 3 Net to parsing Discussed how to extract features from a grammar 26
 Apply M 3 Net to parsing Discussed how to extract features from a grammar 26.")
27
Outline Large Margin Methods for Structured and Interdependent Output Variables (Tsochantaridis et. al., 2005) Max-Margin Markov Networks (Taskar et. al., 2003) Learning Structural SVMs with Latent Variables (Yu and Joachims, 2009) 27
 Max-Margin Markov Networks (Taskar et. al., 2003) Learning Structural SVMs with Latent Variables (Yu and Joachims, 2009) 27.")
28
Latent Variable Models Widely used in machine learning and statistics Unobserved quantities/missing data in experiments Dimensionality Reduction Classical examples: Mixture models, PCA, LDA This paper: Latent variables in supervised prediction tasks

29
Latent Variables in S-SVMs How can we extend structural SVM to handle latent variables?

30
Structured SVM

31
Latent S-SVM Formulation

33
CCCP Algorithm

34
aa

35
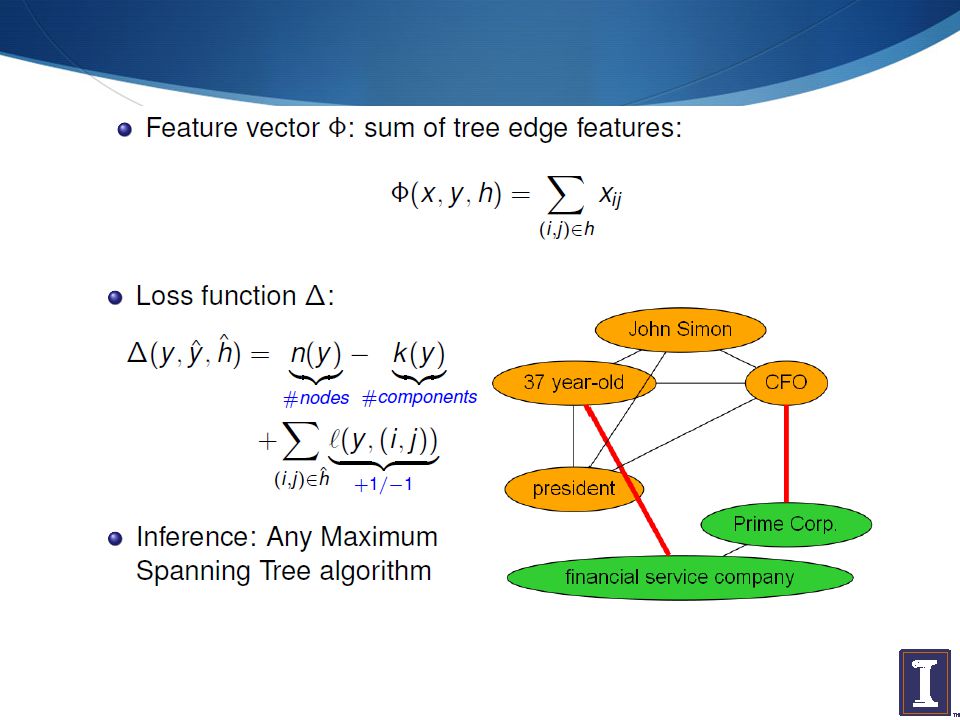
Noun Phrase Co-reference

37
Noun phrase co-reference results

38
38

Similar presentations



>")

>")














