Download presentation
Presentation is loading. Please wait.

1
Solving problems using propositional logic Need to write what you know as propositional formulas Theorem proving will then tell you whether a given new sentence will hold given what you know Three kinds of queries –Is my knowledgebase consistent? (i.e. is there at least one world where everything I know is true?) Satisfiability –Is the sentence S entailed by my knowledge base? (i.e., is it true in every world where my knowledge base is true?) –Is the sentence S consistent/possibly true with my knowledge base? (i.e., is S true in at least one of the worlds where my knowledge base holds?) S is consistent if ~S is not entailed But cannot differentiate between degrees of likelihood among possible sentences
 Satisfiability –Is the sentence S entailed by my knowledge base. (i.e., is it true in every world where my knowledge base is true ) –Is the sentence S consistent/possibly true with my knowledge base. (i.e., is S true in at least one of the worlds where my knowledge base holds ) S is consistent if ~S is not entailed But cannot differentiate between degrees of likelihood among possible sentences.")
2
Example Pearl lives in Los Angeles. It is a high-crime area. Pearl installed a burglar alarm. He asked his neighbors John & Mary to call him if they hear the alarm. This way he can come home if there is a burglary. Los Angeles is also earth-quake prone. Alarm goes off when there is an earth- quake. Burglary => Alarm Earth-Quake => Alarm Alarm => John-calls Alarm => Mary-calls If there is a burglary, will Mary call? Check KB & E |= M If Mary didn’t call, is it possible that Burglary occurred? Check KB & ~M doesn’t entail ~B

3
Assertions; t/f Epistemological commitment Ontological commitment t/f/u Deg belief facts Facts Objects relations Prop logic Prob prop logic FOPCProb FOPC

4
Example (Real) Pearl lives in Los Angeles. It is a high- crime area. Pearl installed a burglar alarm. He asked his neighbors John & Mary to call him if they hear the alarm. This way he can come home if there is a burglary. Los Angeles is also earth- quake prone. Alarm goes off when there is an earth-quake. Pearl lives in real world where (1) burglars can sometimes disable alarms (2) some earthquakes may be too slight to cause alarm (3) Even in Los Angeles, Burglaries are more likely than Earth Quakes (4) John and Mary both have their own lives and may not always call when the alarm goes off (5) Between John and Mary, John is more of a slacker than Mary.(6) John and Mary may call even without alarm going off Burglary => Alarm Earth-Quake => Alarm Alarm => John-calls Alarm => Mary-calls If there is a burglary, will Mary call? Check KB & E |= M If Mary didn’t call, is it possible that Burglary occurred? Check KB & ~M doesn’t entail ~B John already called. If Mary also calls, is it more likely that Burglary occurred? You now also hear on the TV that there was an earthquake. Is Burglary more or less likely now?
 burglars can sometimes disable alarms (2) some earthquakes may be too slight to cause alarm (3) Even in Los Angeles, Burglaries are more likely than Earth Quakes (4) John and Mary both have their own lives and may not always call when the alarm goes off (5) Between John and Mary, John is more of a slacker than Mary.(6) John and Mary may call even without alarm going off Burglary => Alarm Earth-Quake => Alarm Alarm => John-calls Alarm => Mary-calls If there is a burglary, will Mary call. Check KB & E |= M If Mary didn’t call, is it possible that Burglary occurred. Check KB & ~M doesn’t entail ~B John already called. If Mary also calls, is it more likely that Burglary occurred. You now also hear on the TV that there was an earthquake. Is Burglary more or less likely now .")
5
Example (Real) Pearl lives in Los Angeles. It is a high- crime area. Pearl installed a burglar alarm. He asked his neighbors John & Mary to call him if they hear the alarm. This way he can come home if there is a burglary. Los Angeles is also earth- quake prone. Alarm goes off when there is an earth-quake. Pearl lives in real world where (1) burglars can sometimes disable alarms (2) some earthquakes may be too slight to cause alarm (3) Even in Los Angeles, Burglaries are more likely than Earth Quakes (4) John and Mary both have their own lives and may not always call when the alarm goes off (5) Between John and Mary, John is more of a slacker than Mary.(6) John and Mary may call even without alarm going off Burglary => Alarm Earth-Quake => Alarm Alarm => John-calls Alarm => Mary-calls If there is a burglary, will Mary call? Check KB & E |= M If Mary didn’t call, is it possible that Burglary occurred? Check KB & ~M doesn’t entail ~B John already called. If Mary also calls, is it more likely that Burglary occurred? You now also hear on the TV that there was an earthquake. Is Burglary more or less likely now?
 burglars can sometimes disable alarms (2) some earthquakes may be too slight to cause alarm (3) Even in Los Angeles, Burglaries are more likely than Earth Quakes (4) John and Mary both have their own lives and may not always call when the alarm goes off (5) Between John and Mary, John is more of a slacker than Mary.(6) John and Mary may call even without alarm going off Burglary => Alarm Earth-Quake => Alarm Alarm => John-calls Alarm => Mary-calls If there is a burglary, will Mary call. Check KB & E |= M If Mary didn’t call, is it possible that Burglary occurred. Check KB & ~M doesn’t entail ~B John already called. If Mary also calls, is it more likely that Burglary occurred. You now also hear on the TV that there was an earthquake. Is Burglary more or less likely now .")
6
How do we handle Real Pearl? Omniscient & Eager way: – Model everything! –E.g. Model exactly the conditions under which John will call He shouldn’t be listening to loud music, he hasn’t gone on an errand, he didn’t recently have a tiff with Pearl etc etc. A & c1 & c2 & c3 &..cn => J (also the exceptions may have interactions c1&c5 => ~c9 ) Ignorant (non-omniscient) and Lazy (non- omnipotent) way: –Model the likelihood –In 85% of the worlds where there was an alarm, John will actually call –How do we do this? Non-monotonic logics “certainty factors” “fuzzy logic” “probability” theory? Qualification and Ramification problems make this an infeasible enterprise Potato in the tail-pipe
 Ignorant (non-omniscient) and Lazy (non- omnipotent) way: –Model the likelihood –In 85% of the worlds where there was an alarm, John will actually call –How do we do this. Non-monotonic logics certainty factors fuzzy logic probability theory. Qualification and Ramification problems make this an infeasible enterprise Potato in the tail-pipe.")
7
Non-monotonic (default) logic Prop calculus (as well as the first order logic we shall discuss later) are monotonic, in that once you prove a fact F to be true, no amount of additional knowledge can allow us to disprove F. But, in the real world, we jump to conclusions by default, and revise them on additional evidence –Consider the way the truth of the statement “F: Tweety Flies” is revised by us when we are given facts in sequence: 1. Tweety is a bird (F)2. Tweety is an Ostritch (~F) 3. Tweety is a magical Ostritch (F) 4. Tweety was cursed recently (~F) 5. Tweety was able to get rid of the curse (F) How can we make logic show this sort of “defeasible” (aka defeatable) conclusions? –Many ideas, with one being negation as failure –Let the rule about birds be Bird & ~abnormal => Fly The “abnormal” predicate is treated special— if we can’t prove abnormal, we can assume ~abnormal is true (Note that in normal logic, failure to prove a fact F doesn’t allow us to assume that ~F is true since F may be holding in some models and not in other models). –Non-monotonic logic enterprise involves (1) providing clean semantics for this type of reasoning and (2) making defeasible inference efficient
2. Tweety is an Ostritch (~F) 3. Tweety is a magical Ostritch (F) 4. Tweety was cursed recently (~F) 5. Tweety was able to get rid of the curse (F) How can we make logic show this sort of defeasible (aka defeatable) conclusions. –Many ideas, with one being negation as failure –Let the rule about birds be Bird & ~abnormal => Fly The abnormal predicate is treated special— if we can’t prove abnormal, we can assume ~abnormal is true (Note that in normal logic, failure to prove a fact F doesn’t allow us to assume that ~F is true since F may be holding in some models and not in other models). –Non-monotonic logic enterprise involves (1) providing clean semantics for this type of reasoning and (2) making defeasible inference efficient.")
8
Certainty Factors Associate numbers to each of the facts/axioms When you do derivations, compute c.f. of the results in terms of the c.f. of the constituents (“truth functional”) Problem: Circular reasoning because of mixed causal/diagnostic directions –Raining => Grass-wet 0.9 –Grass-wet => raining 0.7 If you know grass-wet with 0.4, then we know raining which makes grass more wet, which….
 Problem: Circular reasoning because of mixed causal/diagnostic directions –Raining => Grass-wet 0.9 –Grass-wet => raining 0.7 If you know grass-wet with 0.4, then we know raining which makes grass more wet, which…..")
9
Fuzzy Logic vs. Prob. Prop. Logic Fuzzy Logic assumes that the word is made of statements that have different grades of truth –Recall the puppy example Fuzzy Logic is “Truth Functional”—i.e., it assumes that the truth value of a sentence can be established in terms of the truth values only of the constituent elements of that sentence. PPL assumes that the world is made up of statements that are either true or false PPL is truth functional for “truth value in a given world” but not truth functional for entailment status.

10
Prop. Logic vs. Prob. Prop. Logic Model theory for logic –Set of all worlds where the formula/KB holds –Each world is either a model or not Proof theory/inference –Rather than enumerate all models, write KB sentences that constrain the models Model theory for prob. Logic –For each world, give the probability p that the formula holds in that world p(w)=0 means that world is definitely not a model Otherwise, 0< p(w) <= 1 Sum of p(w) = 1 AKA Joint Probability Distribution—2 n – 1 numbers Proof Theory –statements on subsets of propositions E.g. p(A)=0.5; p(B|A)=0.7 etc (Cond) Independences… –These constrain the joint probability distribution
=0 means that world is definitely not a model Otherwise, 0< p(w) <= 1 Sum of p(w) = 1 AKA Joint Probability Distribution—2 n – 1 numbers Proof Theory –statements on subsets of propositions E.g. p(A)=0.5; p(B|A)=0.7 etc (Cond) Independences… –These constrain the joint probability distribution.")
11
Easy Special Cases If in addition, each proposition is equally likely to be true or false, –Then the joint probability distribution can be specified without giving any numbers! All worlds are equally probable! If there are n props, each world will be 1/2 n probable –Probability of any propositional conjunction with m (< n) propositions will be 1/2 m If there are no relations between the propositions (i.e., they can take values independently of each other) –Then the joint probability distribution can be specified in terms of probabilities of each proposition being true –Just n numbers instead of 2 n
 propositions will be 1/2 m If there are no relations between the propositions (i.e., they can take values independently of each other) –Then the joint probability distribution can be specified in terms of probabilities of each proposition being true –Just n numbers instead of 2 n.")
12
Will we always need 2 n numbers? If every pair of variables is independent of each other, then – P(x1,x2…xn)= P(xn)* P(xn-1)*…P(x1) –Need just n numbers! –But if our world is that simple, it would also be very uninteresting & uncontrollable (nothing is correlated with anything else!) We need 2 n numbers if every subset of our n-variables are correlated together –P(x1,x2…xn)= P(xn|x1…xn-1)* P(xn-1|x1…xn-2)*…P(x1) –But that is too pessimistic an assumption on the world If our world is so interconnected we would’ve been dead long back… A more realistic middle ground is that interactions between variables are contained to regions. --e.g. the “school variables” and the “home variables” interact only loosely (are independent for most practical purposes) -- Will wind up needing O(2 k ) numbers (k << n)
= P(xn)* P(xn-1)*…P(x1) –Need just n numbers. –But if our world is that simple, it would also be very uninteresting & uncontrollable (nothing is correlated with anything else!) We need 2 n numbers if every subset of our n-variables are correlated together –P(x1,x2…xn)= P(xn|x1…xn-1)* P(xn-1|x1…xn-2)*…P(x1) –But that is too pessimistic an assumption on the world If our world is so interconnected we would’ve been dead long back… A more realistic middle ground is that interactions between variables are contained to regions. --e.g. the school variables and the home variables interact only loosely (are independent for most practical purposes) -- Will wind up needing O(2 k ) numbers (k << n).")
13
Probabilistic Calculus to the Rescue Suppose we know the likelihood of each of the (propositional) worlds (aka Joint Probability distribution ) Then we can use standard rules of probability to compute the likelihood of all queries (as I will remind you) So, Joint Probability Distribution is all that you ever need! In the case of Pearl example, we just need the joint probability distribution over B,E,A,J,M (32 numbers) --In general 2 n separate numbers (which should add up to 1) If Joint Distribution is sufficient for reasoning, what is domain knowledge supposed to help us with? --Answer: Indirectly by helping us specify the joint probability distribution with fewer than 2 n numbers ---The local relations between propositions can be seen as “constraining” the form the joint probability distribution can take! Burglary => Alarm Earth-Quake => Alarm Alarm => John-calls Alarm => Mary-calls Only 10 (instead of 32) numbers to specify! Topology encodes the conditional independence assertions
 --In general 2 n separate numbers (which should add up to 1) If Joint Distribution is sufficient for reasoning, what is domain knowledge supposed to help us with. --Answer: Indirectly by helping us specify the joint probability distribution with fewer than 2 n numbers ---The local relations between propositions can be seen as constraining the form the joint probability distribution can take. Burglary => Alarm Earth-Quake => Alarm Alarm => John-calls Alarm => Mary-calls Only 10 (instead of 32) numbers to specify. Topology encodes the conditional independence assertions.")
14
Probabilistic Calculus to the Rescue Suppose we know the likelihood of each of the (propositional) worlds (aka Joint Probability distribution ) Then we can use standard rules of probability to compute the likelihood of all queries (as I will remind you) So, Joint Probability Distribution is all that you ever need! In the case of Pearl example, we just need the joint probability distribution over B,E,A,J,M (32 numbers) --In general 2 n separate numbers (which should add up to 1) If Joint Distribution is sufficient for reasoning, what is domain knowledge supposed to help us with? --Answer: Indirectly by helping us specify the joint probability distribution with fewer than 2 n numbers ---The local relations between propositions can be seen as “constraining” the form the joint probability distribution can take! Burglary => Alarm Earth-Quake => Alarm Alarm => John-calls Alarm => Mary-calls Only 10 (instead of 32) numbers to specify!
 --In general 2 n separate numbers (which should add up to 1) If Joint Distribution is sufficient for reasoning, what is domain knowledge supposed to help us with. --Answer: Indirectly by helping us specify the joint probability distribution with fewer than 2 n numbers ---The local relations between propositions can be seen as constraining the form the joint probability distribution can take. Burglary => Alarm Earth-Quake => Alarm Alarm => John-calls Alarm => Mary-calls Only 10 (instead of 32) numbers to specify!.")
15
Directly using Joint Distribution Directly using Bayes rule Using Bayes rule With bayes nets Takes O(2 n ) for most natural queries of type P(D|Evidence) NEEDS O(2 n ) probabilities as input Probabilities are of type P(w k )—where w k is a world Can take much less than O(2 n ) time for most natural queries of type P(D|Evidence) STILL NEEDS O(2 n ) probabilities as input Probabilities are of type P(X 1..X n |Y) Can take much less than O(2 n ) time for most natural queries of type P(D|Evidence) Can get by with anywhere between O(n) and O(2 n ) probabilities depending on the conditional independences that hold. Probabilities are of type P(X 1..X n |Y)
.")
16
Prob. Prop logic: The Game plan We will review elementary “discrete variable” probability We will recall that joint probability distribution is all we need to answer any probabilistic query over a set of discrete variables. We will recognize that the hardest part here is not the cost of inference (which is really only O(2 n ) –no worse than the (deterministic) prop logic –Actually it is Co-#P-complete (instead of Co-NP-Complete) (and the former is believed to be harder than the latter) The real problem is assessing probabilities. – You could need as many as 2 n numbers (if all variables are dependent on all other variables); or just n numbers if each variable is independent of all other variables. Generally, you are likely to need somewhere between these two extremes. –The challenge is to Recognize the “conditional independences” between the variables, and exploit them to get by with as few input probabilities as possible and Use the assessed probabilities to compute the probabilities of the user queries efficiently.
 –no worse than the (deterministic) prop logic –Actually it is Co-#P-complete (instead of Co-NP-Complete) (and the former is believed to be harder than the latter) The real problem is assessing probabilities. – You could need as many as 2 n numbers (if all variables are dependent on all other variables); or just n numbers if each variable is independent of all other variables. Generally, you are likely to need somewhere between these two extremes. –The challenge is to Recognize the conditional independences between the variables, and exploit them to get by with as few input probabilities as possible and Use the assessed probabilities to compute the probabilities of the user queries efficiently..")
17
Two ways of specifying world knowledge Extensional Specification (“possible worlds”) –[prop logic] Enumerate all worlds consistent with what you know (models of KB) –[prob logic] Provide likelihood of all worlds given what you know Intensional (implicit) specification –[prop logic] Just state the local propositional constraints that you know (e.g. p=>q which means no world where p is true and q is false is a possible world) –[prop logic] Just state the local probabilistic constraints that you know (e.g. P(q|p) =.99) The local knowledge implicitly defines the extensional specification. Local knowledge acts as a constraint on the possible worlds –As you find out more about the world you live in, you eliminate possible worlds you could be in (or revise their likelihood)
![Two ways of specifying world knowledge Extensional Specification ( possible worlds ) –[prop logic] Enumerate all worlds consistent with what you know (models of KB) –[prob logic] Provide likelihood of all worlds given what you know Intensional (implicit) specification –[prop logic] Just state the local propositional constraints that you know (e.g.](http://images.slideplayer.com/13/3823030/slides/slide_17.jpg "p=>q which means no world where p is true and q is false is a possible world) –[prop logic] Just state the local probabilistic constraints that you know (e.g. P(q|p) =.99) The local knowledge implicitly defines the extensional specification. Local knowledge acts as a constraint on the possible worlds –As you find out more about the world you live in, you eliminate possible worlds you could be in (or revise their likelihood).")
18
Propositional Probabilistic Logic

20
If you know the full joint, You can answer ANY query

22
TA~TA CA0.040.06 ~CA0.010.89 P(CA & TA) = P(CA) = P(TA) = P(CA V TA) = P(CA|~TA) = P(~TA|CA) = Check if P(CA|~TA) = P(~TA|CA)* P(CA) Computing Prob. Queries Given a Joint Distribution Your name:

23
TA~TA CA0.040.06 ~CA0.010.89 P(CA & TA) = 0.04 P(CA) = 0.04+0.06 = 0.1 (marginalizing over TA) P(TA) = 0.04+0.01= 0.05 P(CA V TA) = P(CA) + P(TA) – P(CA&TA) = 0.1+0.05-0.04 = 0.11 P(CA|~TA) = P(CA&~TA)/P(~TA) = 0.06/(0.06+.89) =.06/.95=.0631 Think of this as analogous to entailment by truth-table enumeration!
 = 0.04 P(CA) = = 0.1 (marginalizing over TA) P(TA) = = 0.05 P(CA V TA) = P(CA) + P(TA) – P(CA&TA) = = 0.11 P(CA|~TA) = P(CA&~TA)/P(~TA) = 0.06/( ) =.06/.95=.0631 Think of this as analogous to entailment by truth-table enumeration!")
24
If B=>A then P(A|B) = ? P(B|~A) = ? P(B|A) = ? The material in this slide was presented on the white board

25
Most useful probabilistic reasoning involves computing posterior distributions Probability Variable values P(CA) P(CA|TA) P(CA|TA;Catch) Important: Computing posterior distribution is inference; not learning P(CA|TA;Catch;Romney-won)?
 P(CA|TA) P(CA|TA;Catch) Important: Computing posterior distribution is inference; not learning P(CA|TA;Catch;Romney-won)")
26
CONDITIONAL PROBABLITIES Non-monotonicity w.r.t. evidence– P(A|B) can be either higher, lower or equal to P(A) The material in this slide was presented on the white board
 can be either higher, lower or equal to P(A) The material in this slide was presented on the white board.")
27
A be Anthrax; Rn be Runny Nose P(A|Rn) = P(Rn|A) P(A)/ P(Rn) Get by with easier to assess numbers Generalized bayes rule P(A|B,e) = P(B|A,e) P(A|e) P(B|e) Think of this as analogous to inference rules (like modus-ponens) The material in this slide was presented on the white board
 = P(Rn|A) P(A)/ P(Rn) Get by with easier to assess numbers Generalized bayes rule P(A|B,e) = P(B|A,e) P(A|e) P(B|e) Think of this as analogous to inference rules (like modus-ponens) The material in this slide was presented on the white board")
28
Relative ease/utility of Assessing various types of probabilities Joint distribution requires us to assess probabilities of type P(x1,~x2,x3,….~xn) This means we have to look at all entities in the world and see which fraction of them have x1,~x2,x3….~xm true Difficult experiment to setup.. Conditional probabilities of type P(A|B) are relatively easier to assess –You just need to look at the set of entities having B true, and look at the fraction of them that also have A true –Eventually, they too can get baroque P(x1,~x2,…xm|y1..yn) Among the conditional probabilities, causal probabilities of the form P(effect|cause) are better to assess than diagnostic probabilities of the form P(cause|effect) –Causal probabilities tend to me more stable compared to diagnostic probabilities –(for example, a text book in dentistry can publish P(TA|Cavity) and hope that it will hold in a variety of places. In contrast, P(Cavity|TA) may depend on other fortuitous factors—e.g. in areas where people tend to eat a lot of icecream, many tooth aches may be prevalent, and few of them may be actually due to cavities. Doc, Doc, I have flu. Can you tell if I have a runny nose? The material in this slide was presented on the white board
 are relatively easier to assess –You just need to look at the set of entities having B true, and look at the fraction of them that also have A true –Eventually, they too can get baroque P(x1,~x2,…xm|y1..yn) Among the conditional probabilities, causal probabilities of the form P(effect|cause) are better to assess than diagnostic probabilities of the form P(cause|effect) –Causal probabilities tend to me more stable compared to diagnostic probabilities –(for example, a text book in dentistry can publish P(TA|Cavity) and hope that it will hold in a variety of places. In contrast, P(Cavity|TA) may depend on other fortuitous factors—e.g. in areas where people tend to eat a lot of icecream, many tooth aches may be prevalent, and few of them may be actually due to cavities. Doc, Doc, I have flu. Can you tell if I have a runny nose. The material in this slide was presented on the white board.")
29
What happens if there are multiple symptoms…? Patient walked in and complained of toothache You assess P(Cavity|Toothache) Now you try to probe the patients mouth with that steel thingie, and it catches… How do we update our belief in Cavity? P(Cavity|TA, Catch) = P(TA,Catch| Cavity) * P(Cavity) P(TA,Catch) = P(TA,Catch|Cavity) * P(Cavity) Need to know this! If n evidence variables, We will need 2 n probabilities! Conditional independence To the rescue Suppose P(TA,Catch|cavity) = P(TA|Cavity)*P(Catch|Cavity) The material in this slide was presented on the white board
 Now you try to probe the patients mouth with that steel thingie, and it catches… How do we update our belief in Cavity. P(Cavity|TA, Catch) = P(TA,Catch| Cavity) * P(Cavity) P(TA,Catch) = P(TA,Catch|Cavity) * P(Cavity) Need to know this. If n evidence variables, We will need 2 n probabilities. Conditional independence To the rescue Suppose P(TA,Catch|cavity) = P(TA|Cavity)*P(Catch|Cavity) The material in this slide was presented on the white board.")
32
Local Semantics Node independent of non-descendants given its parents Gives global semantics i.e. the full joint Put variables in reverse topological sort; apply chain rule P(J|M,A,~B,~E)*P(M|A,~B,~E)*P(A|~B,~E)*P(~B|~E)*P(~E) P(J|A) * P(M|A) *P(A|~B,~E) * P(~B) * P(~E) By conditional independence inherent in the Bayes Net.9.7.001.999.998.000628
*P(M|A,~B,~E)*P(A|~B,~E)*P(~B|~E)*P(~E) P(J|A) * P(M|A) *P(A|~B,~E) * P(~B) * P(~E) By conditional independence inherent in the Bayes Net")
33
Conditional Independence Assertions We write X || Y | Z to say that the set of variables X is conditionally independent of the set of variables Y given evidence on the set of variables Z (where X,Y,Z are subsets of the set of all random variables in the domain model) Inference can exploit conditional independence assertions. Specifically, –X || Y| Z implies P(X & Y|Z) = P(X|Z) * P(Y|Z) P(X|Y, Z) = P(X|Z) P(Y|X,Z) = P(Y|Z) –If A||B|C then P(A,B,C)=P(A|B,C)P(B,C) =P(A|B,C)P(B|C)P(C) =P(A|C)P(B|C)P(C) (Can get by with 1+2+2=5 numbers instead of 8) Why not write down all conditional independence assertions that hold in a domain?
 = P(X|Z) * P(Y|Z) P(X|Y, Z) = P(X|Z) P(Y|X,Z) = P(Y|Z) –If A||B|C then P(A,B,C)=P(A|B,C)P(B,C) =P(A|B,C)P(B|C)P(C) =P(A|C)P(B|C)P(C) (Can get by with 1+2+2=5 numbers instead of 8) Why not write down all conditional independence assertions that hold in a domain .")
34
Cond. Indep. Assertions (Contd) Idea: Why not write down all conditional independence assertions (CIA) (X || Y | Z) that hold in a domain? Problem: There can be exponentially many conditional independence assertions that hold in a domain (recall that X, Y and Z are all subsets of the domain variables). Brilliant Idea: May be we should implicitly specify the CIA by writing down the “local dependencies” between variables using a graphical model –A Bayes Network is a way of doing just this. The Bayes Net is a Directed Acyclic Graph whose nodes are random variables, and the immediate dependencies between variables are represented by directed arcs –The topology of a bayes network shows the inter-variable dependencies. Given the topology, there is a way of checking if any Cond. Indep. Assertion. holds in the network (the Bayes Ball algorithm and the D-Sep idea)
 Idea: Why not write down all conditional independence assertions (CIA) (X || Y | Z) that hold in a domain. Problem: There can be exponentially many conditional independence assertions that hold in a domain (recall that X, Y and Z are all subsets of the domain variables). Brilliant Idea: May be we should implicitly specify the CIA by writing down the local dependencies between variables using a graphical model –A Bayes Network is a way of doing just this. The Bayes Net is a Directed Acyclic Graph whose nodes are random variables, and the immediate dependencies between variables are represented by directed arcs –The topology of a bayes network shows the inter-variable dependencies. Given the topology, there is a way of checking if any Cond. Indep. Assertion. holds in the network (the Bayes Ball algorithm and the D-Sep idea).")
35
Topological Semantics Independence from Non-descedants holds Given just the parents Independence from Every node holds Given markov blanket These two conditions are equivalent Many other conditional indepdendence assertions follow from these Markov Blanket Parents; Children; Children’s other parents

36
CIA implicit in Bayes Nets So, what conditional independence assumptions are implicit in Bayes nets? –Local Markov Assumption: A node N is independent of its non-descendants (including ancestors) given its immediate parents. (So if P are the immediate paretnts of N, and A is a subset of of Ancestors and other non-descendants, then {N} || A| P ) (Equivalently) A node N is independent of all other nodes given its markov blanket (parents, children, children’s parents) –Given this assumption, many other conditional independencies follow. For a full answer, we need to appeal to D-Sep condition and/or Bayes Ball reachability
 given its immediate parents. (So if P are the immediate paretnts of N, and A is a subset of of Ancestors and other non-descendants, then {N} || A| P ) (Equivalently) A node N is independent of all other nodes given its markov blanket (parents, children, children’s parents) –Given this assumption, many other conditional independencies follow. For a full answer, we need to appeal to D-Sep condition and/or Bayes Ball reachability.")
38
Alarm P(A|J,M) =P(A)? Burglary Earthquake How many probabilities are needed? 13 for the new; 10 for the old Is this the worst? Introduce variables in the causal order Easy when you know the causality of the domain hard otherwise..

39
Digression: Is assessing/learning numbers the only hard model-learning problem? We are making it sound as if assessing the probabilities is a big deal In doing so, we are taking into account model acquisition/learning costs. How come we didn’t care about these issues in logical reasoning? Is it because acquiring logical knowledge is easy? Actually—if we are writing programs for worlds that we (the humans) already live in, it is easy for us (humans) to add the logical knowledge into the program. It is a pain to give the probabilities.. On the other hand, if the agent is fully autonomous and is bootstrapping itself, then learning logical knowledge is actually harder than learning probabilities.. –For example, we will see that given the bayes network topology (“logic”), learning its CPTs is much easier than learning both topology and CPTs
 already live in, it is easy for us (humans) to add the logical knowledge into the program. It is a pain to give the probabilities.. On the other hand, if the agent is fully autonomous and is bootstrapping itself, then learning logical knowledge is actually harder than learning probabilities.. –For example, we will see that given the bayes network topology ( logic ), learning its CPTs is much easier than learning both topology and CPTs.")
40
Bayesian (Personal) Probabilities Continuing bad friends, in the question above, suppose a second friend comes along and says that he can give you the conditional probabilities that you want to complete the specification of your bayes net. You ask him a CPT entry, and pat comes a response--some number between 0 and 1. This friend is well meaning, but you are worried that the numbers he is giving may lead to some sort of inconsistent joint probability distribution. Is your worry justified ( i.e., can your friend give you numbers that can lead to an inconsistency?) (To understand "inconsistency", consider someone who insists on giving you P(A), P(B), P(A&B) as well as P(AVB) and they wind up not satisfying the P(AVB)= P(A)+P(B) -P(A&B) [or alternately, they insist on giving you P(A|B), P(B|A), P(A) and P(B), and the four numbers dont satisfy the bayes rule] Answer: No—as long as we only ask the friend to fill up the CPTs in the bayes network, there is no way the numbers won’t makeup a consistent joint probability distribution –This should be seen as a feature.. Personal Probabilities –John may be an optimist and believe that P(burglary)=0.01 and Tom may be a pessimist and believe that P(burglary)=0.99 –Bayesians consider both John and Tom to be fine (they don’t insist on an objective frequentist interpretation for probabilites) –However, Bayesians do think that John and Tom should act consistently with their own beliefs For example, it makes no sense for John to go about installing tons of burglar alarms given his belief, just as it makes no sense for Tom to put all his valuables on his lawn
 (To understand inconsistency , consider someone who insists on giving you P(A), P(B), P(A&B) as well as P(AVB) and they wind up not satisfying the P(AVB)= P(A)+P(B) -P(A&B) [or alternately, they insist on giving you P(A|B), P(B|A), P(A) and P(B), and the four numbers dont satisfy the bayes rule] Answer: No—as long as we only ask the friend to fill up the CPTs in the bayes network, there is no way the numbers won’t makeup a consistent joint probability distribution –This should be seen as a feature.. Personal Probabilities –John may be an optimist and believe that P(burglary)=0.01 and Tom may be a pessimist and believe that P(burglary)=0.99 –Bayesians consider both John and Tom to be fine (they don’t insist on an objective frequentist interpretation for probabilites) –However, Bayesians do think that John and Tom should act consistently with their own beliefs For example, it makes no sense for John to go about installing tons of burglar alarms given his belief, just as it makes no sense for Tom to put all his valuables on his lawn.")
41
Ideas for reducing the number of probabilties to be specified Problem 1: Joint distribution requires 2 n numbers to specify; and those numbers are harder to assess Problem 2: But, CPTs will be as big as the full joint if the network is dense CPTs Problem 3: But, CPTs can still be quite hard to specify if there are too many parents (or if the variables are continuous) Solution: Use Bayes Nets to reduce the numbers and specify them as CPTs Solution: Introduce intermediate variables to induce sparsity into the network Solution: Parameterize the CPT (use Noisy OR etc for discrete variables; gaussian etc for continuous variables)
 Solution: Use Bayes Nets to reduce the numbers and specify them as CPTs Solution: Introduce intermediate variables to induce sparsity into the network Solution: Parameterize the CPT (use Noisy OR etc for discrete variables; gaussian etc for continuous variables)")
42
Making the network Sparse by introducing intermediate variables Consider a network of boolean variables where n parent nodes are connected to m children nodes (with each parent influencing each child). –You will need n + m*2 n conditional probabilities Suppose you realize that what is really influencing the child nodes is some single aggregate function on the parent’s values (e.g. sum of the parents). –We can introduce a single intermediate node called “sum” which has links from all the n parent nodes, and separately influences each of the m child nodes Now you will wind up needing only n+ 2 n + 2m conditional probabilities to specify this new network!
. –We can introduce a single intermediate node called sum which has links from all the n parent nodes, and separately influences each of the m child nodes Now you will wind up needing only n+ 2 n + 2m conditional probabilities to specify this new network!.")
43
Learning such hidden variables from data poses challenges..

45
Compact/Parameterized distributions are pretty much the only way to go when continuous variables are involved!

46
We only consider the failure to cause probability of the Causes that hold k i=j+1 riri How about Noisy And? (hint: A&B => ~( ~A V ~B) ) Prob that X holds even though i th parent doesn’t Think of a firing squad with upto k gunners trying to shoot you You will live only if everyone who shoots misses..
 ) Prob that X holds even though i th parent doesn’t Think of a firing squad with upto k gunners trying to shoot you You will live only if everyone who shoots misses...")
48
Constructing Belief Networks: Summary [[Decide on what sorts of queries you are interested in answering –This in turn dictates what factors to model in the network Decide on a vocabulary of the variables and their domains for the problem –Introduce “Hidden” variables into the network as needed to make the network “sparse” Decide on an order of introduction of variables into the network –Introducing variables in causal direction leads to fewer connections (sparse structure) AND easier to assess probabilities Try to use canonical distributions to specify the CPTs –Noisy-OR –Parameterized discrete/continuous distributions Such as Poisson, Normal (Gaussian) etc
 AND easier to assess probabilities Try to use canonical distributions to specify the CPTs –Noisy-OR –Parameterized discrete/continuous distributions Such as Poisson, Normal (Gaussian) etc")
49
Case Study: Pathfinder System Domain: Lymph node diseases –Deals with 60 diseases and 100 disease findings Versions: –Pathfinder I: A rule-based system with logical reasoning –Pathfinder II: Tried a variety of approaches for uncertainity Simple bayes reasoning outperformed –Pathfinder III: Simple bayes reasoning, but reassessed probabilities –Parthfinder IV: Bayesian network was used to handle a variety of conditional dependencies. Deciding vocabulary: 8 hours Devising the topology of the network: 35 hours Assessing the (14,000) probabilities: 40 hours –Physician experts liked assessing causal probabilites Evaluation: 53 “referral” cases –Pathfinder III: 7.9/10 –Pathfinder IV: 8.9/10 [Saves one additional life in every 1000 cases!] –A more recent comparison shows that Pathfinder now outperforms experts who helped design it!!
 probabilities: 40 hours –Physician experts liked assessing causal probabilites Evaluation: 53 referral cases –Pathfinder III: 7.9/10 –Pathfinder IV: 8.9/10 [Saves one additional life in every 1000 cases!] –A more recent comparison shows that Pathfinder now outperforms experts who helped design it!!.")
50
Conditional Independence Assertions We write X || Y | Z to say that the set of variables X is conditionally independent of the set of variables Y given evidence on the set of variables Z (where X,Y,Z are subsets of the set of all random variables in the domain model) Inference can exploit conditional independence assertions. Specifically, –X || Y| Z implies P(X & Y|Z) = P(X|Z) * P(Y|Z) P(X|Y, Z) = P(X|Z) P(Y|X,Z) = P(Y|Z) –If A||B|C then P(A,B,C)=P(A|B,C)P(B,C) =P(A|B,C)P(B|C)P(C) =P(A|C)P(B|C)P(C) (Can get by with 1+2+2=5 numbers instead of 8) Why not write down all conditional independence assertions that hold in a domain?
 = P(X|Z) * P(Y|Z) P(X|Y, Z) = P(X|Z) P(Y|X,Z) = P(Y|Z) –If A||B|C then P(A,B,C)=P(A|B,C)P(B,C) =P(A|B,C)P(B|C)P(C) =P(A|C)P(B|C)P(C) (Can get by with 1+2+2=5 numbers instead of 8) Why not write down all conditional independence assertions that hold in a domain .")
51
Topological Semantics Independence from Non-descedants holds Given just the parents Independence from Every node holds Given markov blanket These two conditions are equivalent Many other conditional indepdendence assertions follow from these Markov Blanket Parents; Children; Children’s other parents

52
Independence in Bayes Networks: Causal Chains; Common Causes; Common Effects Causal chain (linear) X causes Y through Z is blocked if Z is given Common Cause (diverging) X and Y are caused by Z is blocked if Z is given Common Effect (converging) X and Y cause Z is blocked only if neither Z nor its descendants are given
 X causes Y through Z is blocked if Z is given Common Cause (diverging) X and Y are caused by Z is blocked if Z is given Common Effect (converging) X and Y cause Z is blocked only if neither Z nor its descendants are given")
53
D-sep (direction dependent Separation) X || Y | E if every undirected path from X to Y is blocked by E –A path is blocked if there is a node Z on the path s.t. 1.[ Z ] Z is in E and Z has one arrow coming in and another going out 2.[ Z ] is in E and Z has both arrows going out 3.[ Z ] Neither Z nor any of its descendants are in E and both path arrows lead to Z B||M|A (J,M)||E | A B||E B||E | A B||E | M
||E | A B||E B||E | A B||E | M.")
54
Topological Semantics Independence from Non-descedants holds Given just the parents Independence from Every node holds Given markov blanket These two conditions are equivalent Many other conditional indepdendence assertions follow from these Markov Blanket Parents; Children; Children’s other parents

55
Visit to Asia Smoking Lung Cancer Tuberculosis Abnormality in Chest Bronchitis X-Ray Dyspnea “Asia” network: V||A | T T ||L ? T||L | D X||D X||D | A (V,S) || X | A (V,S)||(X,D)| A How many probabilities? (assume all are boolean variables) P(V,~T,S,~L,A,B,~X,~D) = Name:
 || X | A (V,S)||(X,D)| A How many probabilities. (assume all are boolean variables) P(V,~T,S,~L,A,B,~X,~D) = Name:.")
56
0 th idea for Bayes Net Inference Given a bayes net, we can compute all the entries of the joint distribution (by just multiplying entries in CPTs) Given the joint distribution, we can answer any probabilistic query. Ergo, we can do inference on bayes networks Qn: Can we do better? –Ideas: Implicity enumerate only the part of the joint that is needed Use sampling techniques to compute the probabilities

57
Factor Algebra… P(A,B)
")
58
Variable Elimination (Summing Away) P(A,B) = P(B) =? Eliminate A Sum rows where A changes polarity Elimination is what we mostly do to compute probabilities P(A|B) = P(AB)/P(B)
 = P(AB)/P(B).")
59
Normalization

61
If the expression tree is evaluated in a depth first fashion, then the space requirement is linear..

62
f A (a,b,e)*f j (a)*f M (a)+ f A (~a,b,e)*f j (~a)*f M (~a)+
*f j (a)*f M (a)+ f A (~a,b,e)*f j (~a)*f M (~a)+")
63
Complexity depends on the size of the largest factor which in turn depends on the order in which variables are eliminated.. A join..

65
Variable Elimination and Irrelevant Variables… Suppose we asked the query P(J|A=t) –Which is probability that John calls given that Alarm went off –We know that this is a simple lookup into the CPT in our bayes net. –But, variable elimination algorithm is going to sum over the three other variables unnecessarily –In those cases, the factors will be “degenerate” (will sum to 1; see next slide) This problem can be even more prominent if we had many other variables in the network Qn: How can we make variable elimination wake-up and avoid this unnecessary work? –General answer is to (a) identify variables that are irrelevant given the query and evidence –In the P(J|A), we should be able to see that e,b,m are irrelevant and remove them (b) remove the irrelevant variables from the network –A variable v is irrelevant for a query P(X|E) if X || v | E (i.e., X is conditionally independent of v given E). We can use BayesBall or DSEP notions to figure out irrelevant variables v There are a couple of easier sufficient conditions for irrelevance (both of which are special cases of BayesBall/DSep).
 This problem can be even more prominent if we had many other variables in the network Qn: How can we make variable elimination wake-up and avoid this unnecessary work. –General answer is to (a) identify variables that are irrelevant given the query and evidence –In the P(J|A), we should be able to see that e,b,m are irrelevant and remove them (b) remove the irrelevant variables from the network –A variable v is irrelevant for a query P(X|E) if X || v | E (i.e., X is conditionally independent of v given E). We can use BayesBall or DSEP notions to figure out irrelevant variables v There are a couple of easier sufficient conditions for irrelevance (both of which are special cases of BayesBall/DSep)..")
66
*Read Worked Out Example of Variable Elimination in the Lecture Notes*

67
A More Complex Example Visit to Asia Smoking Lung Cancer Tuberculosis Abnormality in Chest Bronchitis X-Ray Dyspnea “Asia” network: [From Lise Getoor’s notes]
![A More Complex Example Visit to Asia Smoking Lung Cancer Tuberculosis Abnormality in Chest Bronchitis X-Ray Dyspnea Asia network: [From Lise Getoor’s notes]](http://images.slideplayer.com/13/3823030/slides/slide_67.jpg "A More Complex Example Visit to Asia Smoking Lung Cancer Tuberculosis Abnormality in Chest Bronchitis X-Ray Dyspnea Asia network: [From Lise Getoor’s notes]")
68
V S L T A B XD We want to compute P(d) Need to eliminate: v,s,x,t,l,a,b Initial factors
 Need to eliminate: v,s,x,t,l,a,b Initial factors")
69
V S L T A B XD We want to compute P(d) Need to eliminate: v,s,x,t,l,a,b Initial factors Eliminate: v Note: f v (t) = P(t) In general, result of elimination is not necessarily a probability term Compute:
 Need to eliminate: v,s,x,t,l,a,b Initial factors Eliminate: v Note: f v (t) = P(t) In general, result of elimination is not necessarily a probability term Compute:")
70
V S L T A B XD We want to compute P(d) Need to eliminate: s,x,t,l,a,b Initial factors Eliminate: s Summing on s results in a factor with two arguments f s (b,l) In general, result of elimination may be a function of several variables Compute:
 Need to eliminate: s,x,t,l,a,b Initial factors Eliminate: s Summing on s results in a factor with two arguments f s (b,l) In general, result of elimination may be a function of several variables Compute:")
71
V S L T A B XD We want to compute P(d) Need to eliminate: x,t,l,a,b Initial factors Eliminate: x Note: f x (a) = 1 for all values of a !! Compute:

72
V S L T A B XD We want to compute P(d) Need to eliminate: t,l,a,b Initial factors Eliminate: t Compute:
 Need to eliminate: t,l,a,b Initial factors Eliminate: t Compute:")
73
V S L T A B XD We want to compute P(d) Need to eliminate: l,a,b Initial factors Eliminate: l Compute:
 Need to eliminate: l,a,b Initial factors Eliminate: l Compute:")
74
V S L T A B XD We want to compute P(d) Need to eliminate: b Initial factors Eliminate: a,b Compute:
 Need to eliminate: b Initial factors Eliminate: a,b Compute:")
75
Variable Elimination We now understand variable elimination as a sequence of rewriting operations Actual computation is done in elimination step Computation depends on order of elimination –Optimal elimination order can be computed—but is NP-hard to do so

76
In general, any leaf node that is not a query or evidence variable is irrelevant (and can be removed) (once it is removed, others may be seen to be irrelevant) Can drop irrelevant variables from the network before starting the query off.. Sufficient Condition 1

77
Sufficient Condition 2 Note that condition 2 doesn’t subsume condition 1. In particular, it won’t allow us to say that M is irrelevant for the query P(J|B)
.")
78
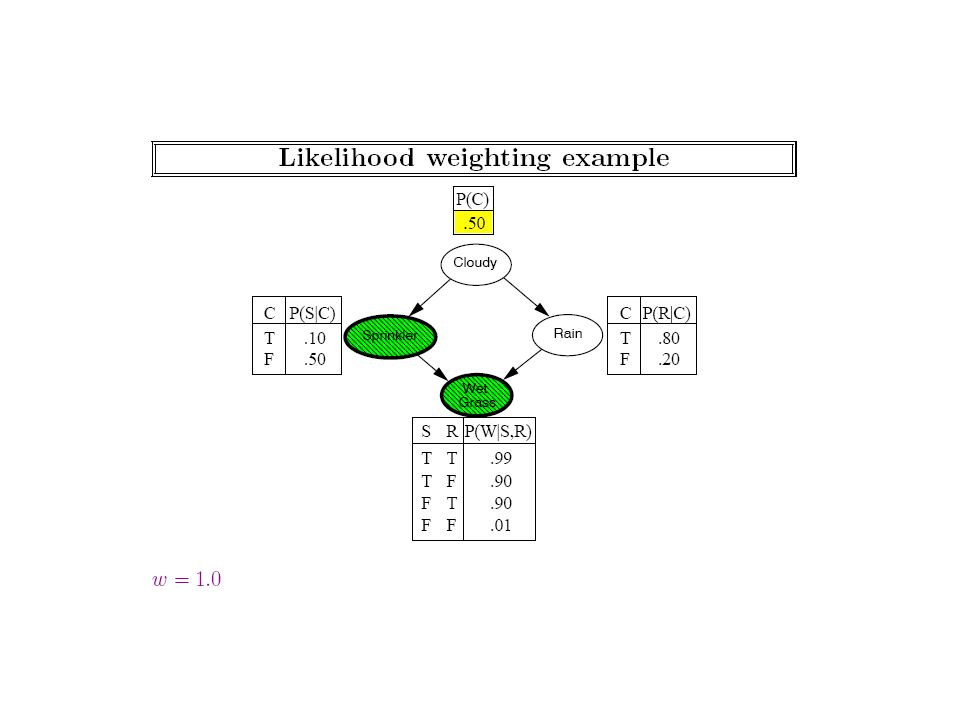
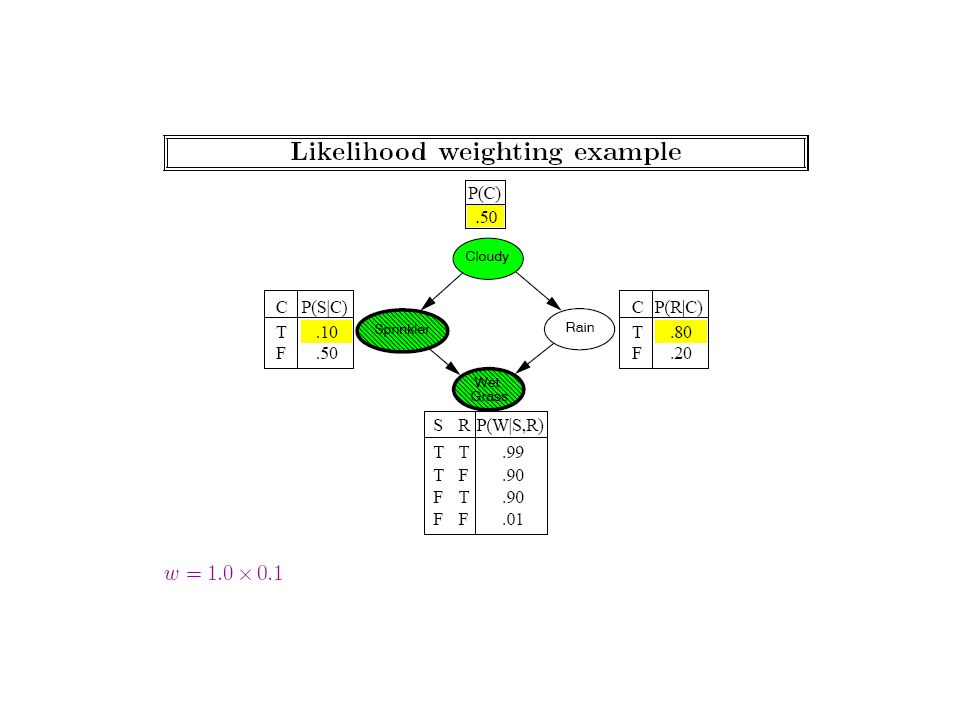
Notice that sampling methods could in general be used even when we don’t know the bayes net (and are just observing the world)! We should strive to make the sampling more efficient given that we know the bayes net

86
Generating a Sample from the Network Network Samples Joint distribution Note that the sample is generated in the causal order so all the required probabilities can be read off from CPTs! (To see how useful this is, consider generating the sample in the order of wetgrass, rain, sprinkler … To sample WG, we will first need P(WG), then we need P(Rain|Wg), then we need P(Sp|Rain,Wg)— NONE of these are directly given in CPTs –and have to be computed… Note that in MCMC we do (re)sample a node given its markov blanket—which is not in causal order—since MB contains children and their parents.
, then we need P(Rain|Wg), then we need P(Sp|Rain,Wg)— NONE of these are directly given in CPTs –and have to be computed… Note that in MCMC we do (re)sample a node given its markov blanket—which is not in causal order—since MB contains children and their parents..")
88
That is, the rejection sampling method doesn’t really use the bayes network that much…

90
Notice that to attach the likelihood to the evidence, we are using the CPTs in the bayes net. (Model-free empirical observation, in contrast, either gives you a sample or not; we can’t get fractional samples)
.")
97
Notice that to attach the likelihood to the evidence, we are using the CPTs in the bayes net. (Model-free empirical observation, in contrast, either gives you a sample or not; we can’t get fractional samples)
.")
102
Note that the other parents of z j are part of the markov blanket P(rain|cl,sp,wg) = P(rain|cl) * P(wg|sp,rain)
 = P(rain|cl) * P(wg|sp,rain)")
104
Examples of singly connected networks include Markov Chains and Hidden Markov Models

105
Network Topology & Complexity of Inference Singly Connected Networks (poly-trees – At most one path between any pair of nodes) Inference is polynomial Cloudy Sprinklers Rain Wetgrass Multiply- connected Inference NP-hard Can be converted to singly-connected (by merging nodes) Cloudy Wetgrass Sprinklers+Rain (takes 4 values 2x2) The “size” of the merged network can beExponentially larger (so polynomial inferenceon that network isn’t exactly god’s gift
 Inference is polynomial Cloudy Sprinklers Rain Wetgrass Multiply- connected Inference NP-hard Can be converted to singly-connected (by merging nodes) Cloudy Wetgrass Sprinklers+Rain (takes 4 values 2x2) The size of the merged network can beExponentially larger (so polynomial inferenceon that network isn’t exactly god’s gift ")
106
Summary of BN Inference Algorithms Exact Inference Algorithms –Enumeration –Variable elimination Avoids the redundant computations of Enumeration –[Many others such as “message passing” algorithms, Constraint- propagation based algorithms etc.] Approximate Inference Algorithms –Based on Stochastic Simulation Sampling from empty networks Rejection sampling Likelihood weighting MCMC [And many more] Complexity –NP-hard (actually #P-Complete; since we “count” models) Polynomial for “Singly connected” networks (one path between each pair of nodes) –NP-hard also for absolute and relative approximation
![Summary of BN Inference Algorithms Exact Inference Algorithms –Enumeration –Variable elimination Avoids the redundant computations of Enumeration –[Many others such as message passing algorithms, Constraint- propagation based algorithms etc.] Approximate Inference Algorithms –Based on Stochastic Simulation Sampling from empty networks Rejection sampling Likelihood weighting MCMC [And many more] Complexity –NP-hard (actually #P-Complete; since we count models) Polynomial for Singly connected networks (one path between each pair of nodes) –NP-hard also for absolute and relative approximation](http://images.slideplayer.com/13/3823030/slides/slide_106.jpg "Summary of BN Inference Algorithms Exact Inference Algorithms –Enumeration –Variable elimination Avoids the redundant computations of Enumeration –[Many others such as message passing algorithms, Constraint- propagation based algorithms etc.] Approximate Inference Algorithms –Based on Stochastic Simulation Sampling from empty networks Rejection sampling Likelihood weighting MCMC [And many more] Complexity –NP-hard (actually #P-Complete; since we count models) Polynomial for Singly connected networks (one path between each pair of nodes) –NP-hard also for absolute and relative approximation")
107
Conjunctive queries are essentially computing joint distributions on sets of query variables. A special case of computing the full joint on query variables is finding just the query variable configuration that is Most likely given the evidence. There are two special cases here MPE—Most Probable Explanation Most likely assignment to all other variables given the evidence Mostly involves max/product MAP—Maximum a posteriori Most likely assignment to some variables given the evidence Can involve, max/product/sum operations

Similar presentations



































 March, 16, 2009.>")


>")
 worlds (aka Joint Probability distribution ) Then we.>")

 Capturing uncertain knowledge Probabilistic.>")



