Download presentation
Presentation is loading. Please wait.

1
3/19

2
Conditional Independence Assertions We write X || Y | Z to say that the set of variables X is conditionally independent of the set of variables Y given evidence on the set of variables Z (where X,Y,Z are subsets of the set of all random variables in the domain model) We saw that Bayes Rule computations can exploit conditional independence assertions. Specifically, –X || Y| Z implies P(X & Y|Z) = P(X|Z) * P(Y|Z) P(X|Y, Z) = P(X|Z) P(Y|X,Z) = P(Y|Z) –If A||B|C then P(A,B,C)=P(A|B,C)P(B,C) =P(A|B,C)P(B|C)P(C) =P(A|C)P(B|C)P(C) (Can get by with 1+2+2=5 numbers instead of 8) Why not write down all conditional independence assertions that hold in a domain?
 = P(X|Z) * P(Y|Z) P(X|Y, Z) = P(X|Z) P(Y|X,Z) = P(Y|Z) –If A||B|C then P(A,B,C)=P(A|B,C)P(B,C) =P(A|B,C)P(B|C)P(C) =P(A|C)P(B|C)P(C) (Can get by with 1+2+2=5 numbers instead of 8) Why not write down all conditional independence assertions that hold in a domain .")
3
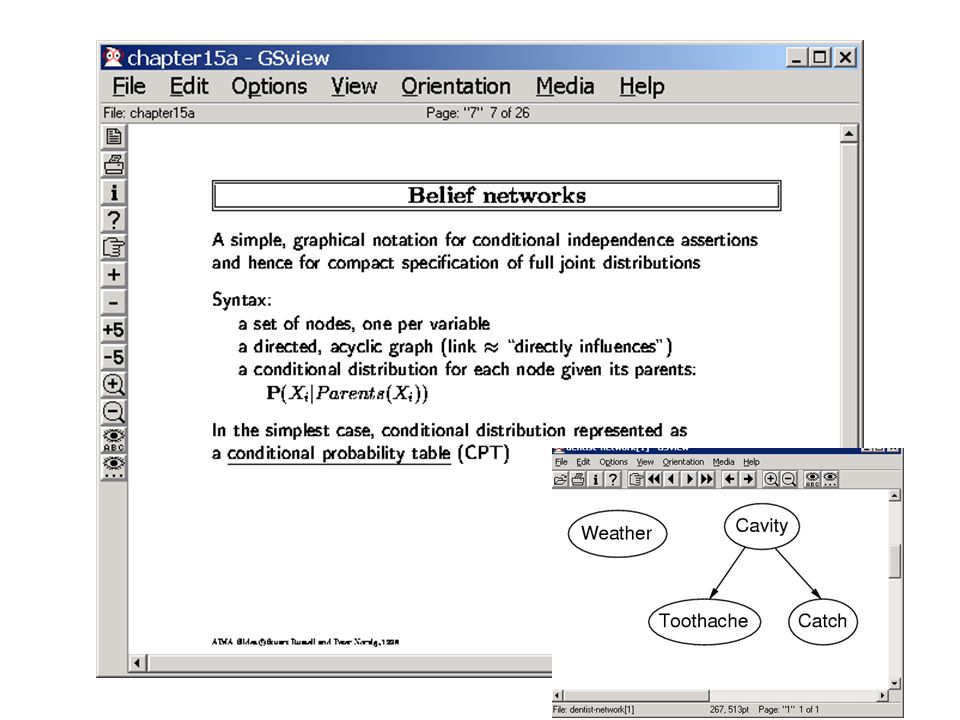
Cond. Indep. Assertions (Contd) Idea: Why not write down all conditional independence assertions (CIA) (X || Y | Z) that hold in a domain? Problem: There can be exponentially many conditional independence assertions that hold in a domain (recall that X, Y and Z are all subsets of the domain variables). Brilliant Idea: May be we should implicitly specify the CIA by writing down the “local dependencies” between variables using a graphical model –A Bayes Network is a way of doing just this. The Bayes Net is a Directed Acyclic Graph whose nodes are random variables, and the immediate dependencies between variables are represented by directed arcs –The topology of a bayes network shows the inter-variable dependencies. Given the topology, there is a way of checking if any Cond. Indep. Assertion. holds in the network (the Bayes Ball algorithm and the D-Sep idea)
 Idea: Why not write down all conditional independence assertions (CIA) (X || Y | Z) that hold in a domain. Problem: There can be exponentially many conditional independence assertions that hold in a domain (recall that X, Y and Z are all subsets of the domain variables). Brilliant Idea: May be we should implicitly specify the CIA by writing down the local dependencies between variables using a graphical model –A Bayes Network is a way of doing just this. The Bayes Net is a Directed Acyclic Graph whose nodes are random variables, and the immediate dependencies between variables are represented by directed arcs –The topology of a bayes network shows the inter-variable dependencies. Given the topology, there is a way of checking if any Cond. Indep. Assertion. holds in the network (the Bayes Ball algorithm and the D-Sep idea).")
5
CIA implicit in Bayes Nets So, what conditional independence assumptions are implicit in Bayes nets? –Local Markov Assumption: A node N is independent of its non-descendants (including ancestors) given its immediate parents. (So if P are the immediate paretnts of N, and A is a subset of of Ancestors and other non-descendants, then {N} || A| P ) (Equivalently) A node N is independent of all other nodes given its markov blanket (parents, children, children’s parents) –Given this assumption, many other conditional independencies follow. For a full answer, we need to appeal to D-Sep condition and/or Bayes Ball reachability
 given its immediate parents. (So if P are the immediate paretnts of N, and A is a subset of of Ancestors and other non-descendants, then {N} || A| P ) (Equivalently) A node N is independent of all other nodes given its markov blanket (parents, children, children’s parents) –Given this assumption, many other conditional independencies follow. For a full answer, we need to appeal to D-Sep condition and/or Bayes Ball reachability.")
6
Topological Semantics Independence from Non-descedants holds Given just the parents Independence from Every node holds Given markov blanket These two conditions are equivalent Many other conditional indepdendence assertions follow from these Markov Blanket Parents; Children; Children’s other parents

8
Local Semantics Node independent of non-descendants given its parents Gives global semantics i.e. the full joint Put variables in reverse topological sort; apply chain rule P(J|M,A,~B,~E)*P(M|A,~B,E)*P(A|~B,E)*P(~B|E)*P(E) P(J|A) * P(M|A) *P(A|~B,E) * P(~B) * P(E) By conditional independence inherent in the Bayes Net
*P(M|A,~B,E)*P(A|~B,E)*P(~B|E)*P(E) P(J|A) * P(M|A) *P(A|~B,E) * P(~B) * P(E) By conditional independence inherent in the Bayes Net.")
10
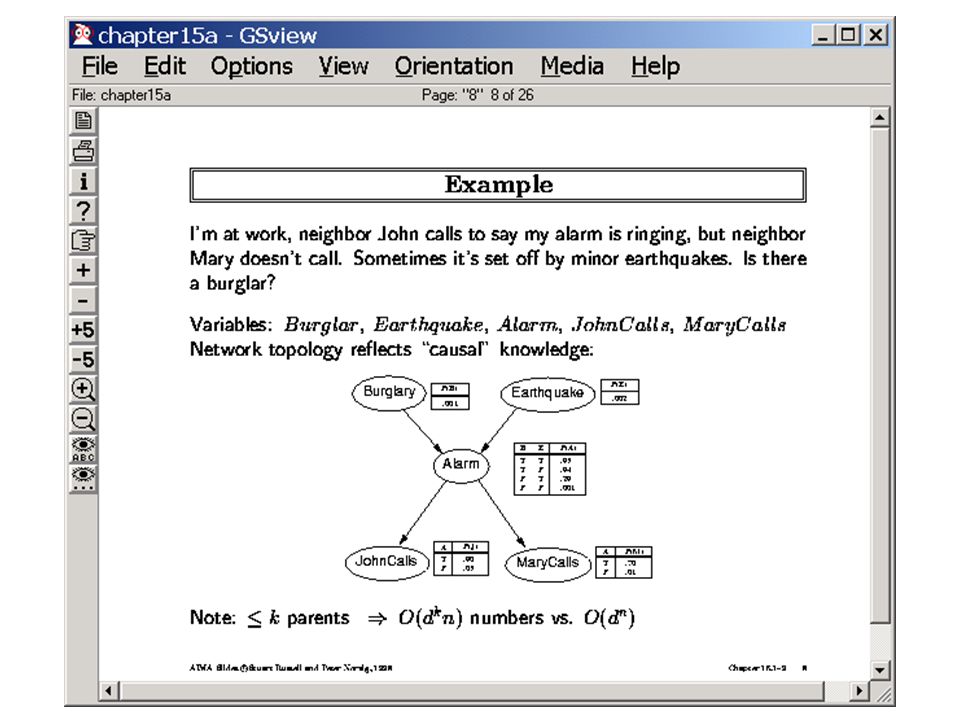
Alarm P(A|J,M) =P(A)? Burglary Earthquake How many probabilities are needed? 13 for the new; 10 for the old Is this the worst? Introduce variables in the causal order Easy when you know the causality of the domain hard otherwise..

11
Digression: Is assessing/learning numbers the only hard model-learning problem? We are making it sound as if assessing the probabilities is a big deal In doing so, we are taking into account model acquisition/learning costs. How come we didn’t care about these issues in logical reasoning? Is it because acquiring logical knowledge is easy? Actually—if we are writing programs for worlds that we (the humans) already live in, it is easy for us (humans) to add the logical knowledge into the program. It is a pain to give the probabilities.. On the other hand, if the agent is fully autonomous and is bootstrapping itself, then learning logical knowledge is actually harder than learning probabilities.. –For example, we will see that given the bayes network topology (“logic”), learning its CPTs is much easier than learning both topology and CPTs
 already live in, it is easy for us (humans) to add the logical knowledge into the program. It is a pain to give the probabilities.. On the other hand, if the agent is fully autonomous and is bootstrapping itself, then learning logical knowledge is actually harder than learning probabilities.. –For example, we will see that given the bayes network topology ( logic ), learning its CPTs is much easier than learning both topology and CPTs.")
12
Ideas for reducing the number of probabilties to be specified Problem 1: Joint distribution requires 2 n numbes to specify; and those numbers are harder to assess Problem 2: But, CPTs will be as big as the full joint if the network is dense CPTs Problem 3: But, CPTs can still be quite hard to specify if there are too many parents (or if the variables are continuous) Solution: Use Bayes Nets to reduce the numbers and specify them as CPTs Solution: Introduce intermediate variables to induce sparsity into the network Solution: Parameterize the CPT (use Noisy OR etc for discrete variables; gaussian etc for continuous variables)
 Solution: Use Bayes Nets to reduce the numbers and specify them as CPTs Solution: Introduce intermediate variables to induce sparsity into the network Solution: Parameterize the CPT (use Noisy OR etc for discrete variables; gaussian etc for continuous variables)")
13
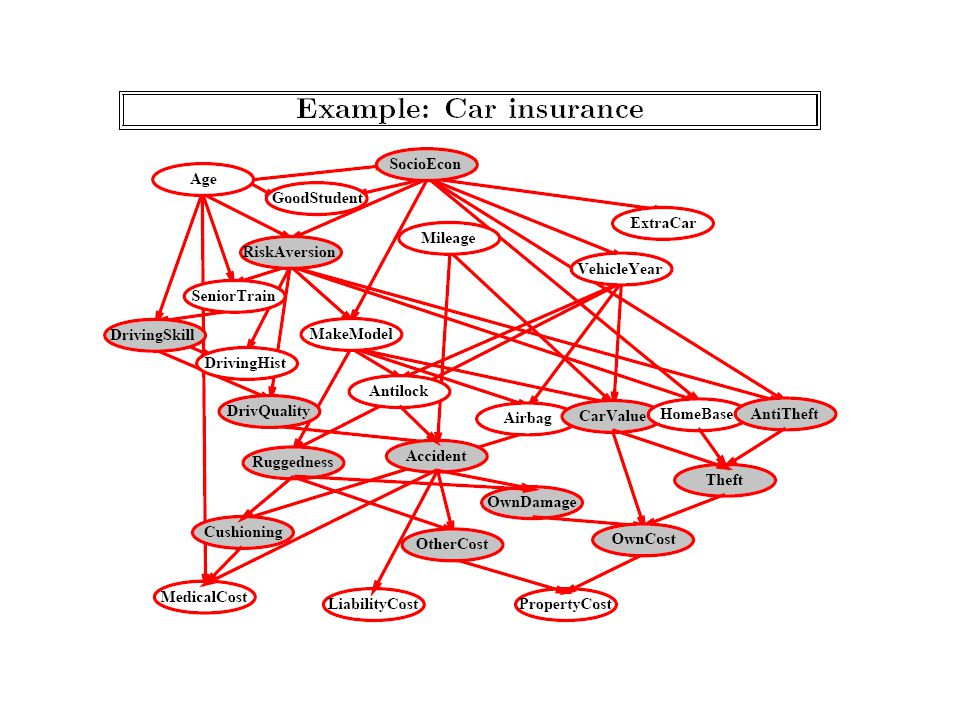
Making the network Sparse by introducing intermediate variables Consider a network of boolean variables where n parent nodes are connected to m children nodes (with each parent influencing each child). –You will need n + m*2 n conditional probabilities Suppose you realize that what is really influencing the child nodes is some single aggregate function on the parent’s values (e.g. sum of the parents). –We can introduce a single intermediate node called “sum” which has links from all the n parent nodes, and separately influences each of the m child nodes Now you will wind up needing only n+ 2 n + 2m conditional probabilities to specify this new network!
. –We can introduce a single intermediate node called sum which has links from all the n parent nodes, and separately influences each of the m child nodes Now you will wind up needing only n+ 2 n + 2m conditional probabilities to specify this new network!.")
14
Learning such hidden variables from data poses challenges..

16
Compact/Parameterized distributions are pretty much the only way to go when continuous variables are involved!

17
We only consider the failure to cause probability of the Causes that hold k i=j+1 riri How about Noisy And? (hint: A&B => ~( ~A V ~B) ) Prob that X holds even though i th parent doesn’t Think of a firing squad with upto k gunners trying to shoot you You will live only if everyone who shot missed..
 ) Prob that X holds even though i th parent doesn’t Think of a firing squad with upto k gunners trying to shoot you You will live only if everyone who shot missed...")
19
Constructing Belief Networks: Summary [[Decide on what sorts of queries you are interested in answering –This in turn dictates what factors to model in the network Decide on a vocabulary of the variables and their domains for the problem –Introduce “Hidden” variables into the network as needed to make the network “sparse” Decide on an order of introduction of variables into the network –Introducing variables in causal direction leads to fewer connections (sparse structure) AND easier to assess probabilities Try to use canonical distributions to specify the CPTs –Noisy-OR –Parameterized discrete/continuous distributions Such as Poisson, Normal (Gaussian) etc
 AND easier to assess probabilities Try to use canonical distributions to specify the CPTs –Noisy-OR –Parameterized discrete/continuous distributions Such as Poisson, Normal (Gaussian) etc")
20
Case Study: Pathfinder System Domain: Lymph node diseases –Deals with 60 diseases and 100 disease findings Versions: –Pathfinder I: A rule-based system with logical reasoning –Pathfinder II: Tried a variety of approaches for uncertainity Simple bayes reasoning outperformed –Pathfinder III: Simple bayes reasoning, but reassessed probabilities –Parthfinder IV: Bayesian network was used to handle a variety of conditional dependencies. Deciding vocabulary: 8 hours Devising the topology of the network: 35 hours Assessing the (14,000) probabilities: 40 hours –Physician experts liked assessing causal probabilites Evaluation: 53 “referral” cases –Pathfinder III: 7.9/10 –Pathfinder IV: 8.9/10 [Saves one additional life in every 1000 cases!] –A more recent comparison shows that Pathfinder now outperforms experts who helped design it!!
 probabilities: 40 hours –Physician experts liked assessing causal probabilites Evaluation: 53 referral cases –Pathfinder III: 7.9/10 –Pathfinder IV: 8.9/10 [Saves one additional life in every 1000 cases!] –A more recent comparison shows that Pathfinder now outperforms experts who helped design it!!.")
Similar presentations








 March, 16, 2009.>")

>")
 worlds (aka Joint Probability distribution ) Then we.>")

 Capturing uncertain knowledge Probabilistic.>")




>")
 --Homework 3 due Thursday --Midterm next Thursday (10/26)>")
 = ?>")
