Download presentation
Presentation is loading. Please wait.

1
Problem Solving and Quantitative Skills in AP Biology
Use this document as a resource to help guide you. This addition to the curriculum is in response to a new level of questioning from the College Board on last years AP Biology Exam. This powerpoint is an overview of the document published by the college board: AP Biology Quantitative Skills: A Guide for Teachers, plus additional information needed to support the requirements.

2
Up until now, there is strong possibility that you have you used the word hypothesis in only one way. Now we have a null hypothesis that we either reject or fail to reject And an alternate hypothesis that we reject or fail to reject.

3
Example: ( on a very simplified scale)
My null hypothesis at this point: There is no difference in the statistics skill level between members of our class that reviewed statistics during the summer and those that didn’t review. Now, if we come back to school and there is a significant difference we would state: Our null hypothesis has been rejected. GET IT??

4
Please don’t let “math” be the enemy, Yes, you will struggle a little, but that is how you learn. I have found that all the tech tricks with graphs, programs, functions, etc, actually make it kinda cool. We will work on this during the entire school year during our investigation time. This material, along with other supporting statistics resources will remain available to help you each time. We will build our expertise over time, this will not happen overnight.

5
Statistics really helps makes things clear.
You have probably asked yourself after many labs during your lifetime, “What did our results mean?”, “How do we know if it really has any meaning at all?”, “How could I test this to see if my experiment had any real meaning?” I have noticed sometimes students get bogged down in the method, equipment, etc. And after the lab have no idea what they just did. I will try my best to introduce lab procedures vs investigations separately so that doesn’t happen.

6
For some it is a new Vocabulary
– I have a whole page of words I think you might need as a reference place. Statistics is the science of conducting studies to collect, organize, summarize, analyze, and draw conclusions from data. Descriptive statistics consists of the collection, organization, summarization, and presentation of data. Inferential statistics consists of generalizing from samples to populations, performing estimations and hypothesis tests, determining relationships among variables, and making predictions. Probability: the chance of the event occurring. Use in inferential statistics.

7
Descriptive Statistics

8
More vocabulary: A population consists of all subjects (human or otherwise) that are being studied. A sample is a group of subjects selected from a population. Discrete variables assume values that can be counted. Continuous variables can assume an infinite number of values between any two specific values. They are obtained by measuring. They often include fractions and decimals
 that are being studied. A sample is a group of subjects selected from a population. Discrete variables assume values that can be counted. Continuous variables can assume an infinite number of values between any two specific values. They are obtained by measuring. They often include fractions and decimals.")
9
Qualitative vs. Quantitative
Marital status of nurses in hospital. Time it takes to run a marathon. Weights of lobsters in a tank in a restaurant. Colors of automobiles in a shopping center parking lot. Ounces of ice cream in ice cream float. Capacity of the NFL football stadiums. Ages of people living in a personal care home. Group responses welcomed since this is first week of school. Problems modified from Elementary Statistics 8th edition by Bluman.

10
Discrete vs. Continuous
Number of pizzas sold by Pizza Express each day. Relative humidity levels in operating rooms at local hospitals. Number of bananas in a bunch at several local supermarkets. Lifetime (in hours) of 15 Ipod batteries. Weights of the backpacks of first graders on a school bus. Number of students each day who make appointments with a math tutor at a local college. Blood pressures of runners in a marathon. Group responses welcomed since this is the first week of school. Problems modified from Elementary Statistics 8th edition by Bluman.
 of 15 Ipod batteries. Weights of the backpacks of first graders on a school bus. Number of students each day who make appointments with a math tutor at a local college. Blood pressures of runners in a marathon. Group responses welcomed since this is the first week of school. Problems modified from Elementary Statistics 8th edition by Bluman.")
11
1. Graphing Effective graphs convey summary or descriptive statistics as part of the display.

12
It is not practical to think you can count everything
It is not practical to think you can count everything. Most of the time, that would simply be impossible. So we take samples. Statistics takes samples and make inferences that represent the true population. Sampling follows predictable patterns. It’s theoretical.

13
Mean, Median, Mode (Central tendencies)
Mean means average, so the first time you think I’m mean….just know I’m average. =)
")
14
To get the mean:

15
Standard Deviation 𝜎 The average value away from the average. Math is fun. Good website. There are some simple standard deviation problems at The bottom of the page. We will link to this to work on some standard deviation problems together. It is had real cute dog graphics.

16
Categories The data you collect to will generally fall into three Categories: Parametric: Normal data. Fits normal curve or distribution. Generally in a decimal form. The bell curve! Examples: plant height, body temperature, response rate. (The prefix para means side by side. So close in comparison, not like an outlier. If para means normal, does paranormal activity mean normal normal activity? ) Nonparametric: not normal. Does not fit a normal distribution. May include outliers. Can be ordered. Can be big, medium, small (qualitative) Frequency or count data: How many fits in this category? Flies you counted with normal wings, etc.
 Nonparametric: not normal. Does not fit a normal distribution. May include outliers. Can be ordered. Can be big, medium, small (qualitative) Frequency or count data: How many fits in this category Flies you counted with normal wings, etc.")
17
Questions to divide into 2 groups.
Is A different than B? How are A and B correlated? To design a good investigation, the type of data needed to answer your question has to be decided during the planning stages. What kind of question is being asked and what kind of data will be required to answer it?

18
5 types of graphs 1. Bar Graphs 2. Scatter plots 3. Box and whiskers plot 4. Histograms 5. Line Graphs

19
College Board AP Investigations that need a graph:
1. Artificial Selection – AP exam 2014 4. Diffusion and Osmosis 5. Photosynthesis 6. Cellular Respiration 9. Biotechnology: Restriction Enzyme Analysis of DNA 12. Fruit Fly Behavior – AP exam 2013 13. Enzyme Activity

20
Bar Graphs Use to compare two samples of categorical or count data. You will need to compare the calculated means with error bars. Example: qualitative: eye color. Always use Sample Standard error bar. (Sample error of the mean) (SEM)
 (SEM)")
21
Bar graph with only the mean plotted.

22
Scatterplots Used to explore associations between two variables visually. One variable is measured against another. It is looking for trends or associations. Plotting of individual data points on an x-y plot.

23
Scatterplots Sine wave-like Bell-curved

24
Box-and-whisker plot Allows comparison of two samples of nonparametric data (data that does not fit a normal distribution) Medians and quartiles Lowest value, 2: Q1, 3: the Median; 4. Q3, 5. highest value Of set.

25
Histograms – use this as a preliminary step to see shape.
Frequency diagram. Used to display the distribution of data, providing a representation of the central tendencies (mean, Median, Mode) and the spread of the data. Can then see if parametric or non. Involves measurement data and data distribution. Requires setting up “bins” – which are uniform range intervals that cover the entire range of the data. Then the number of measurements that fit in each bin (range of unit) are counted and graphed. If enough measurements are made, the data can show the normal distribution, or bell- shaped distribution, on a histogram. Quantitative, uses averages, spreads from low to high; continuous data such as time, or measurements; tenths show minor changes. Sample size should be at least 30.
 and the spread of the data. Can then see if parametric or non. Involves measurement data and data distribution. Requires setting up bins – which are uniform range intervals that cover the entire range of the data. Then the number of measurements that fit in each bin (range of unit) are counted and graphed. If enough measurements are made, the data can show the normal distribution, or bell- shaped distribution, on a histogram. Quantitative, uses averages, spreads from low to high; continuous data such as time, or measurements; tenths show minor changes. Sample size should be at least 30.")
26
Record High Temperatures
Class Boundaries Frequency 99.5- 104.5 2 8 18 114.5- 119.5 13 119.5- 124.5 7 124.5- 129.5 1 129.5- 134.5 Students will use Ipads. We will walk through entering Class Boundaries and Frequencies and making a histogram with these values. Ipad app: Numbers + Create new spreadsheet: blank Enter just as you see on table. Grab all. Create chart. Add details. Mail symbol. Open in other app then Google Drive for home or print.

27
Sunny & Shady Leaves

28
Histogram - nonparametric

29
Line Graphs Can use multiple variables. Usually change over time; line suggests trend

30
Good Graph reminders: Title Easy to identify lines and bars Clearly labeled with units.
X-axis independent variable Y-axis dependent variable Uniform intervals More than one condition: different lines:style,color Indicated on a key Don’t start at origin if your data doesn’t. Standard Error of the Means bars (SEM)
")
31
Taken from the Handbook of Biological Statistics Good Resource
I find that a systematic, step-by-step approach is the best way to analyze biological data. The statistical analysis of a biological experiment may be broken down into the following steps: Specify the biological question to be answered. Put the question in the form of a biological null hypothesis and alternate hypothesis. Put the question in the form of a statistical null hypothesis and alternate hypothesis. Determine which variables are relevant to the question. Determine what kind of variable each one is. Design an experiment that controls or randomizes the confounding variables. Based on the number of variables, the kind of variables, the expected fit to the parametric assumptions, and the hypothesis to be tested, choose the best statistical test to use. If possible, do a power analysis to determine a good sample size for the experiment. Do the experiment. Examine the data to see if it meets the assumptions of the statistical test you chose (normality, homoscedasticity, etc.). If it doesn't, choose a more appropriate test. Apply the chosen statistical test, and interpret the result. Communicate your results effectively, usually with a graph or table.
. If it doesn t, choose a more appropriate test. Apply the chosen statistical test, and interpret the result. Communicate your results effectively, usually with a graph or table.")
32
Chapter 2: Data Analysis
Labs using DATA ANALYSIS: 1. ARTIFICIAL SELECTION – FRQ 2014 2. MATHEMATICAL MODELING: HARDY-WEINBERY 3. COMPARING DNA SEQUENCES TO UNDERSTAND EVOLUTIONARY RELATIONSHIPS WITH BLAST 4. CELL DIVISION: MITOSIS AND MEIOSIS

33
Data analysis Descriptive statistics: summarize data. Shows variation
in the data, standard errors, best-fit functions, and confidence that sufficient data have been collected. Inferential statistics: involves making conclusions, using experimental data to infer parameters in the natural population. Relies on probability. Most measurements are continuous, infinite number over a period of time. Examples: size, time, height, weight, absorbance. Others are: Count data: qualitative, categorical, example: number of hairs, etc. Requires different statistical tools.

34
Run through of the steps.
Good idea to do this first, before you design your own experiment. Most investigations will allow to have an initial run- through with all of class doing the same thing.

35
Components of Data Analysis

36
Bias How can we be certain if the statistic we use is giving an accurate estimate of? Think of what we want to estimate (the parameter) as the target and the way we estimate it (the statistic) as the arrow. Our statistic is called unbiased if it is close to being on target. Our statistic is called biased if it is not close to being on target. Information from AP Statistics teacher concerning sample size and the larger the sample size, the closer the confidence gets to the real mean of the population.
 as the target and the way we estimate it (the statistic) as the arrow. Our statistic is called unbiased if it is. close to being on target. Our statistic is. called biased if it is not close to being on. target. Information from AP Statistics teacher concerning sample size and the larger the sample size, the closer the confidence gets to the real mean of the population.")
37
Bias We determine bias of a statistic by comparing the center of its sampling distribution to the parameter being estimated. Sample means and proportions are both unbiased estimators.

39
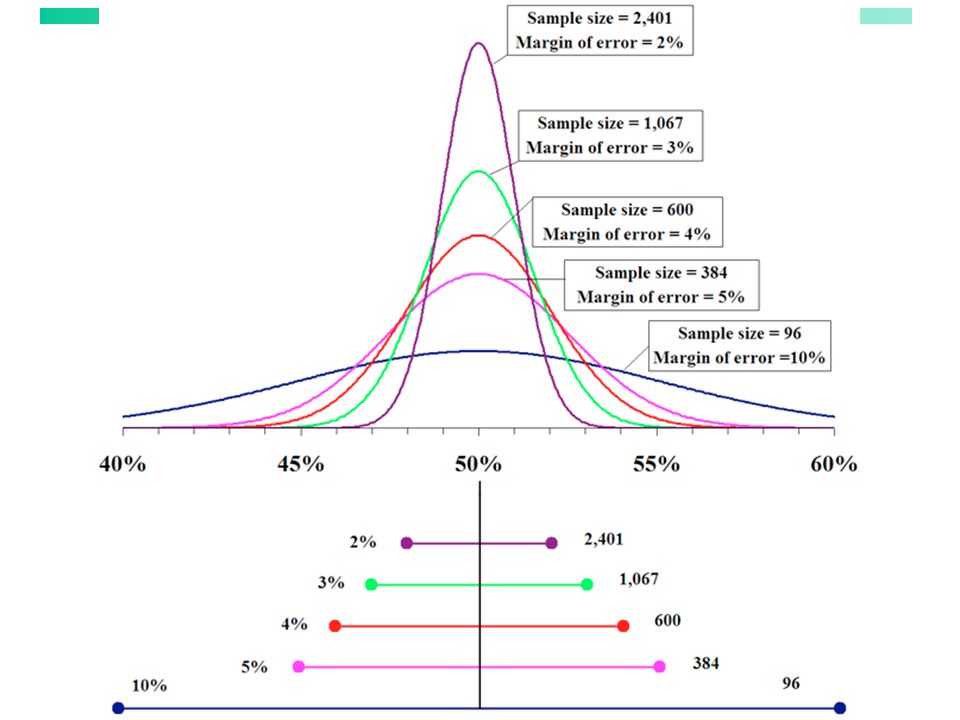
Sample Standard Error Allows for inference of how sample mean matches up to the true population. A distribution of the sample means helps define boundaries of confidence in our sample. ∓ 1 SE describes 67% confidence range. ∓ 2 SE defines 95% certainty Confidence limits contains the true population mean. 95% confident: larger range to contain the population mean (95% of the data found here) 67% confident: narrower range to contain the population mean. SE – inference in which to draw conclusions SD – just looking at data 95% is trade off for never being 100% sure.
 67% confident: narrower range to contain the population mean. SE – inference in which to draw conclusions. SD – just looking at data. 95% is trade off for never being 100% sure.")
40
Inference/Confidence Intervals/ Empirical Rule/ 67-95-99.7 Rule
Confidence Intervals: Use to determine if two populations are different from one another.

41
Parametric or Nonparametric: Time for a group activity
Parametric or Nonparametric: Time for a group activity. Make a histogram. Students will be given a baggie of colored squares with the measurements for the leaf widths. They will assemble a histogram based on these measurements. There are 30 squares for shady leaves and 30 squares for sunny leaves. Some groups will receive triple the amount of squares and some will receive double the amount of squares. Students will make a histogram. They will determine parametric or nonparametric. They will then be asked what type of data is this. They should come up measurements. They will use this to begin to answer the next steps. What’s in your tool bag?

42
So, we made a histogram Looked for our shape
So, we made a histogram Looked for our shape. Parametric or nonparametric?. What type of graph will we use? If parametric, we will use our sample size, mean standard deviation, and standard error to analyze. If nonparametric, we will use medians, modes, quartiles, and range . Often use a box and whiskers plot. These are the tools we will use for each type to analyze and describe it.

43
Error Bars

44
Another example: Body Temperature What kind of data has been collected?

45
Explore the sample: Is it parametric. What type of graph
Explore the sample: Is it parametric? What type of graph? What is in your tool bag?

46
Chapter 3: Hypothesis Testing
Necessary in the following Investigations: 1. Artificial Selection 2. Mathematical Modeling: Hardy-Weinberg 3. Comparing DNA: BLAST 4. Diffusion and Osmosis 5. Photosynthesis 6. Cellular Respiration 7. Cell Division: Mitosis and Meiosis 8. Biotechnology: Bacterial Transformation 9. Biotechnology: RE of DNA 10. Energy Dynamics 11. Transpiration 12. Fruit-Fly Behavior 13. Enzyme Activity

47
Hypothesis A hypothesis is a statement explaining that a causal relationship exists between and underlying factor (variable) and an observable phenomenon. You might propose a tentative explanation and this would be called your working hypothesis. ABSOLUTE PROOF IS NOT POSSIBLE, SO WE FOCUS ON TRYING TO REJECT A NULL HYPOTHESIS. A null hypothesis is a statement that the variable has no causal relationship. An alternative to the null hypothesis would be that there is a size difference, etc.
 and an observable phenomenon. You might propose a tentative explanation and this would be called your working hypothesis. ABSOLUTE PROOF IS NOT POSSIBLE, SO WE FOCUS ON TRYING TO REJECT A NULL HYPOTHESIS. A null hypothesis is a statement that the variable has no causal relationship. An alternative to the null hypothesis would be that there is a size difference, etc.")
48
Crucial to understand. We say we reject the null, not that the investigation has proven the alternative hypothesis. A hypothesis is a testable statement explaining some relationship between cause and effect. A prediction is a statement of what you think will happen.

49
It is good to have more than one working hypotheses
It is good to have more than one working hypotheses. The investigator can remain more open scientifically and not tied to one single explanation.

50
Hypothesis Testing Asks the question: Is there something to these measurements? Or Is the effect real?

51
Hypothesis testing The data analysis tools used, such as SE, mean, variance, median, etc. are now used to calculate comparative test statistics. These tests determine a probability and distribution of the samples – the null distribution. A critical value of the probability of whether the results or even more extreme results occur by chance alone, if the null hypothesis is true (probability value, or p-value of less than 5%)
")
52
4 possible outcomes of Hypothesis Testing

53
5% critical values in Biology
Decision point in biology. 1% or 0.1% more critical. Like life or death issues in medical studies.

54
The suggested path for including hypothesis testing:
1. Choose a statistical test based on the question and types of data. Next page table. 2. State the null and alternative hypotheses 3. Design and carry out the investigation. 4. Conduct a data analysis, and present graphical and tabular summaries of the data. 5. Carry out the statistical tests. Include the sample size, test statistic chosen, and p-values in the data reports. 6. Make a conclusion, always stating the amount of evidence in terms of the alternative hypothesis.

56
Examples of Hypothesis Testing
t– test Chi-Square Trends – linear regression and r 1. Establish null and alternate H0 null hypothesis – There is no difference between the two true populations. H1 alternate hypothesis – There is a significant difference between the two population means. Establish critical value – p value of 5% Decision table for test P-value Analyze p value and critical value. Reject null. Or state results support alternate hypothesis. Do not accept the alternative hypothesis.

57
T-test Example two groups independent from each other:
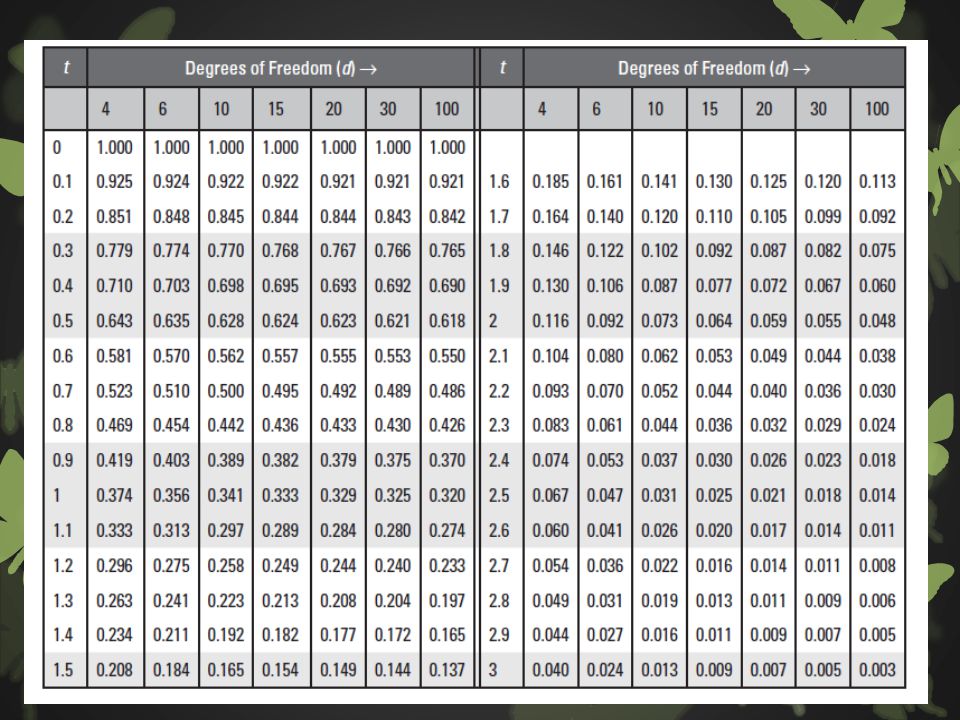
Unpaired T test : determines how different two sample populations are from one another by comparing means and errors. The College Board manual doesn’t go into how to run the test outside of an Excel program, so I don’t foresee this as a problem to calculate, maybe just an understanding required. One tail and two tail refer to both sides of the distribution or just one. The t-test can be used to determine how different two sample populations are from one another by comparing means and standard errors. One sample T-test formula: (sample mean-population mean) The sample standard error Then the t-test value is taken to a t-test table and you need degrees of freedom and t value to estimate the p value. d= n-1
 The sample standard error. Then the t-test value is taken to a t-test table and you need degrees of freedom and t value to estimate the p value. d= n-1.")
59
Comparing two samples and testing for differences
1. Construct two histograms – to get a visual of distribution, overlap, shape. 2. Calculate descriptive statistics. 3. Display in bar graphs 4. Test for differences. 5. Two sample t-test

60
Chi-Square Results Makes comparison between the data collected and what we expect. We will use this test most often. Genetics, animal behavior.

62
A p-value of 0.05 means that there is a 5% chance that the difference between the observed and the expected data is a random difference and a 95% chance that the difference is real and repeatable. A significant difference. If the p-value is greater than 0.05 we would fail to reject to the null hypothesis.

63
This is the table given on your formula sheet. We need to
wrap your head around the difference of the tables and how the application to the null is still the same.

64
Trends and Associations

65
Best-fit line, linear regression, and r
Is there a general trend? A regression analysis graphs a best fit line that summarizes all the points into a single linear equation. Positive correlation: heart rate goes up when temp goes up. Trend line is created from how far each point is from the mean x value and from the mean y value. The r-value provides an estimate of the degree of correlation. r-value of 1 is positive 1:1 correlation R-value of -1 is negative correlation r-value of .25 equal R2 of which means 6.4% of variation (difference) is due to temp and not a strong correlation. R-value does not imply causal relationship. Two tailed t for this since 2 variables. P value on last graph p which means 96% confidence that heart rate and body temperature are correlated, although not strongly so.
 is due to temp and not a strong correlation. R-value does not imply causal relationship. Two tailed t for this since 2 variables. P value on last graph p which means 96% confidence that heart rate and body temperature are correlated, although not strongly so.")
66
Chapter 4: Mathematical Modeling
Labs using Mathematical Modeling 1. Artifical Selection 2. Mathematical Modeling: Hardy-Weinberg 3. Comparing DNA: BLAST 9. Biotechnology: RE Analysis of DNA 10. Energy Dynamics 11. Transpiration

67
Mathematical Modeling
The process of creating mathematical or computer-based representations of the structure and interactions of complex biological systems. What can we measure? What should we measure? What are the relevant variables? What are the simplest informative models that we can build?

68
Deterministic models are calculated with fixed probabilities.
Stochastic models use a random number generator to create a model that has a variable outcome and contingencies, much as normal biological systems do. Example is Investigation 2: Mathematical modeling: Hardy-Weinberg.

69
Example: Simple Model of Population Growth
Maybe we might try this sometime: Building a model.

72
FRQ writing If you use statistics to answer the question, use statistics to justify your answer. More resources: aphs.pdf ing.html

73
Make some time for this!! www.randi.org www.badscience.net MythBusters
Ted Talks “Battling Bad Science” cience

74
set A set B set C set D 14 17 3 15 18 6 13 7 20 12 9 11 8 16 10 12.8 15.1 9.5 Data sets for demo. avg. →

Similar presentations






 Parameter Estimation of PDF and Fitting a Distribution Function.>")
















