Download presentation
Presentation is loading. Please wait.

1
Kenneth Owens

2
We wish to compute the interaction between particles (bodies) given their mass and positions Simulation is performed in time steps ◦ Forces between all bodies is computed O(n 2 ) ◦ Positions for all bodies are updated based on their current kinematics and the interaction with other bodies O(n) ◦ Time moves forward by one step
 given their mass and positions Simulation is performed in time steps ◦ Forces between all bodies is computed O(n 2 ) ◦ Positions for all bodies are updated based on their current kinematics and the interaction with other bodies O(n) ◦ Time moves forward by one step")
3
The force between a body i and N other bodies is approximated as above by computing the interaction given their mass (m), the distance vector between them (r _ij ), and a softening factor (ε). This is computed for all bodies with all other bodies

4
Euler Method: For each particle, a discrete timestep (dt) is used to approximate the continuous kinematic equation and update the position and velocity of each particle
 is used to approximate the continuous kinematic equation and update the position and velocity of each particle")
5
Execute an n-body simulation on a distributed memory architecture with multiple GPUs on each node

6
Sequential implementation of n-body simulation code ◦ Written in C ◦ Compiled using gcc-4.4 with –O3 MPI implementation ◦ Written in C ◦ Compiled using mpicc.mpich with gcc-4.4 using 0-3 ◦ Executed using mpirun.mpich on 2,5, an 10 nodes GPU implementation ◦ Written in C with CUDA extensions ◦ Compiled using nvcc with gcc-4.4 using –O3 ◦ Executed on Nvidia 580s MPI-GPU implementation ◦ The MPI driver above was combined with the GPU kernel implementation ◦ Compiled but not tested for correctness

7
The main method of the driver calls nbody nbody calls two externally linked function ◦ compute_forces computes the interactions ◦ update_positions updates the kinematics void nbody(vector4d_t* positions, vector4d_t* velocities, vector4d_t* current_positions, vector4d_t* current_velocities, vector3d_t* accel, size_t size, value_t dt, value_t damping, value_t softening_squared) { compute_forces(positions,accel, size, positions, size, softening_squared); update_positions(positions, velocities, current_positions, current_velocities, accel, size, dt, damping); }
 { compute_forces(positions,accel, size, positions, size, softening_squared); update_positions(positions, velocities, current_positions, current_velocities, accel, size, dt, damping); }")
8
Computes the pair-wise interaction ◦ Hidden second loop in acceleration function void compute_forces(vector4d_t* positions, vector3d_t* forces, size_t positions_size, vector4d_t* sources, size_t sources_size, value_t softening_squared) { for (size_t i = 0; i < positions_size; i++) { forces[i] = acceleration(positions[i],sources,sources_size, forces[i], softening_squared); } }
![ Computes the pair-wise interaction ◦ Hidden second loop in acceleration function void compute_forces(vector4d_t* positions, vector3d_t* forces, size_t positions_size, vector4d_t* sources, size_t sources_size, value_t softening_squared) { for (size_t i = 0; i < positions_size; i++) { forces[i] = acceleration(positions[i],sources,sources_size, forces[i], softening_squared); } }](http://images.slideplayer.com/13/3728248/slides/slide_8.jpg " Computes the pair-wise interaction ◦ Hidden second loop in acceleration function void compute_forces(vector4d_t* positions, vector3d_t* forces, size_t positions_size, vector4d_t* sources, size_t sources_size, value_t softening_squared) { for (size_t i = 0; i < positions_size; i++) { forces[i] = acceleration(positions[i],sources,sources_size, forces[i], softening_squared); } }")
9
Computation for individual interaction written using c vector3d_t interaction(vector3d_t acceleration, vector4d_t body1, vector4d_t body2, value_t softening_squared) { vector3d_t force; force.x = body1.x - body2.x; force.y = body1.y - body2.y; force.z = body1.z - body2.z; float distSqr = force.x * force.x + force.y * force.y + force.z * force.z; distSqr += softening_squared; float invDist = 1.0f / sqrt(distSqr); float invDistCube = invDist * invDist * invDist; float s = body2.w * invDistCube; acceleration.x += force.x * s; acceleration.y += force.y * s; acceleration.z += force.z * s; return acceleration; }
 { vector3d_t force; force.x = body1.x - body2.x; force.y = body1.y - body2.y; force.z = body1.z - body2.z; float distSqr = force.x * force.x + force.y * force.y + force.z * force.z; distSqr += softening_squared; float invDist = 1.0f / sqrt(distSqr); float invDistCube = invDist * invDist * invDist; float s = body2.w * invDistCube; acceleration.x += force.x * s; acceleration.y += force.y * s; acceleration.z += force.z * s; return acceleration; }")
10
Updates each position based on the computed forces void update_positions(vector4d_t* positions, vector4d_t* velocities, vector4d_t* current_positions, vector4d_t* current_velocities, vector3d_t* acceleration, size_t size, value_t dt, value_t damping) { for(size_t i = 0; i < size; i++) { vector4d_t current_position = current_positions[i]; vector3d_t accel = acceleration[i]; vector4d_t current_velocity = current_velocities[i]; update_position(&positions[i], &velocities[i], current_position, current_velocity, accel, dt, damping); }
![ Updates each position based on the computed forces void update_positions(vector4d_t* positions, vector4d_t* velocities, vector4d_t* current_positions, vector4d_t* current_velocities, vector3d_t* acceleration, size_t size, value_t dt, value_t damping) { for(size_t i = 0; i < size; i++) { vector4d_t current_position = current_positions[i]; vector3d_t accel = acceleration[i]; vector4d_t current_velocity = current_velocities[i]; update_position(&positions[i], &velocities[i], current_position, current_velocity, accel, dt, damping); }](http://images.slideplayer.com/13/3728248/slides/slide_10.jpg " Updates each position based on the computed forces void update_positions(vector4d_t* positions, vector4d_t* velocities, vector4d_t* current_positions, vector4d_t* current_velocities, vector3d_t* acceleration, size_t size, value_t dt, value_t damping) { for(size_t i = 0; i < size; i++) { vector4d_t current_position = current_positions[i]; vector3d_t accel = acceleration[i]; vector4d_t current_velocity = current_velocities[i]; update_position(&positions[i], &velocities[i], current_position, current_velocity, accel, dt, damping); }")
11
Implements the previously shown equations void update_position(vector4d_t* position, vector4d_t* velocity, vector4d_t current_position, vector4d_t current_velocity, vector3d_t acceleration,value_t dt, value_t damping) { current_velocity.x += acceleration.x * dt; current_velocity.y += acceleration.y * dt; current_velocity.z += acceleration.z * dt; current_velocity.x *= damping; current_velocity.y *= damping; current_velocity.z *= damping; current_position.x += current_velocity.x * dt; current_position.y += current_velocity.y * dt; current_position.z += current_velocity.z * dt; *position = current_position; *velocity = current_velocity; }
 { current_velocity.x += acceleration.x * dt; current_velocity.y += acceleration.y * dt; current_velocity.z += acceleration.z * dt; current_velocity.x *= damping; current_velocity.y *= damping; current_velocity.z *= damping; current_position.x += current_velocity.x * dt; current_position.y += current_velocity.y * dt; current_position.z += current_velocity.z * dt; *position = current_position; *velocity = current_velocity; }")
12
Started with the implementation from GPU Gems http://http.developer.nvidia.com/GPUGems3/ gpugems3_ch31.html http://http.developer.nvidia.com/GPUGems3/ gpugems3_ch31.html Modified the code to work with data sizes that are larger than 256 but that are not evenly divisible by 256 Added kinematics update Code no longer works for sizes less than 256 ◦ Needed command line specification to control grid and block size anyway

13
Copies to device memory and execute the compute_force_gpu kernel ◦ Note - cudaMemAlloc truncated to fit code void compute_forces(vector4d_t* positions, vector3d_t* forces, size_t positions_size, vector4d_t* sources, size_t sources_size, value_t softening_squared) { ….. compute_forces_gpu >>(device_positions, device_forces, positions_size, device_sources, sources_size, softening_squared ); cudaThreadSynchronize(); cudaMemcpy(forces, device_forces, positions_size * sizeof(float3), cudaMemcpyDeviceToHost); cudaFree((void**)device_positions); cudaFree((void**)device_sources); cudaFree((void**)device_forces); err = cudaGetLastError(); if( cudaSuccess != err) { fprintf(stderr, "Cuda error: %s: \n", cudaGetErrorString( err) );
; cudaThreadSynchronize(); cudaMemcpy(forces, device_forces, positions_size * sizeof(float3), cudaMemcpyDeviceToHost); cudaFree((void**)device_positions); cudaFree((void**)device_sources); cudaFree((void**)device_forces); err = cudaGetLastError(); if( cudaSuccess != err) { fprintf(stderr, Cuda error: %s: \n , cudaGetErrorString( err) );.")
14
Every thread computes the acceleration for its position and moves to the next block ◦ For our test sizes this only implemented cleanup for strides not divisible by 256 __global__ void compute_forces_gpu(float4* positions, float3* forces,int size, float4* sources, int sources_size, float softening_squared ) { for(int index = __mul24(blockIdx.x,blockDim.x) + threadIdx.x; index < size; index += blockDim.x * gridDim.x) { float4 pos = positions[index]; forces[index] = acceleration(pos, sources, sources_size, forces[index], softening_squared);
![ Every thread computes the acceleration for its position and moves to the next block ◦ For our test sizes this only implemented cleanup for strides not divisible by 256 __global__ void compute_forces_gpu(float4* positions, float3* forces,int size, float4* sources, int sources_size, float softening_squared ) { for(int index = __mul24(blockIdx.x,blockDim.x) + threadIdx.x; index < size; index += blockDim.x * gridDim.x) { float4 pos = positions[index]; forces[index] = acceleration(pos, sources, sources_size, forces[index], softening_squared);](http://images.slideplayer.com/13/3728248/slides/slide_14.jpg " Every thread computes the acceleration for its position and moves to the next block ◦ For our test sizes this only implemented cleanup for strides not divisible by 256 __global__ void compute_forces_gpu(float4* positions, float3* forces,int size, float4* sources, int sources_size, float softening_squared ) { for(int index = __mul24(blockIdx.x,blockDim.x) + threadIdx.x; index < size; index += blockDim.x * gridDim.x) { float4 pos = positions[index]; forces[index] = acceleration(pos, sources, sources_size, forces[index], softening_squared);")
15
Uses float3 and float4 instead of home brewed vector types Shared memory is used 256 positions per block Each thread strides across the grid to update a single particle __device__ float3 acceleration(float4 position, float4* positions, int size, float3 acc, float softening_squared) { extern __shared__ float4 sharedPos[]; int p = blockDim.x; int q = blockDim.y; int n = size; int numTiles = n / (p * q); for (int tile = blockIdx.y; tile < numTiles + blockIdx.y; tile++) { sharedPos[threadIdx.x+blockDim.x*threadIdx.y] = positions[WRAP(blockIdx.x + tile,gridDim.x) * p + threadIdx.x]; __syncthreads(); // This is the "tile_calculation" function from the GPUG3 article. acc = gravitation(position, acc,softening_squared); __syncthreads(); } return acc; }
![ Uses float3 and float4 instead of home brewed vector types Shared memory is used 256 positions per block Each thread strides across the grid to update a single particle __device__ float3 acceleration(float4 position, float4* positions, int size, float3 acc, float softening_squared) { extern __shared__ float4 sharedPos[]; int p = blockDim.x; int q = blockDim.y; int n = size; int numTiles = n / (p * q); for (int tile = blockIdx.y; tile < numTiles + blockIdx.y; tile++) { sharedPos[threadIdx.x+blockDim.x*threadIdx.y] = positions[WRAP(blockIdx.x + tile,gridDim.x) * p + threadIdx.x]; __syncthreads(); // This is the tile_calculation function from the GPUG3 article.](http://images.slideplayer.com/13/3728248/slides/slide_15.jpg "acc = gravitation(position, acc,softening_squared); __syncthreads(); } return acc; }.")
16
Kernel strides in the same way as the force computation All threads update a single position simulaneously __global__ void update_positions_gpu(float4* positions, float4* velocities, float4* current_positions, float4* current_velocities, float3* forces, int size, float dt, float damping) { for(int index = __mul24(blockIdx.x,blockDim.x) + threadIdx.x; index < size; index += blockDim.x * gridDim.x) { float4 pos = current_positions[index]; float3 accel = forces[index]; float4 vel = current_velocities[index]; vel.x += accel.x * dt; vel.y += accel.y * dt; vel.z += accel.z * dt; vel.x *= damping; vel.y *= damping; vel.z *= damping; // new position = old position + velocity * deltaTime pos.x += vel.x * dt; pos.y += vel.y * dt; pos.z += vel.z * dt; // store new position and velocity positions[index] = pos; velocities[index] = vel; }
![ Kernel strides in the same way as the force computation All threads update a single position simulaneously __global__ void update_positions_gpu(float4* positions, float4* velocities, float4* current_positions, float4* current_velocities, float3* forces, int size, float dt, float damping) { for(int index = __mul24(blockIdx.x,blockDim.x) + threadIdx.x; index < size; index += blockDim.x * gridDim.x) { float4 pos = current_positions[index]; float3 accel = forces[index]; float4 vel = current_velocities[index]; vel.x += accel.x * dt; vel.y += accel.y * dt; vel.z += accel.z * dt; vel.x *= damping; vel.y *= damping; vel.z *= damping; // new position = old position + velocity * deltaTime pos.x += vel.x * dt; pos.y += vel.y * dt; pos.z += vel.z * dt; // store new position and velocity positions[index] = pos; velocities[index] = vel; }](http://images.slideplayer.com/13/3728248/slides/slide_16.jpg " Kernel strides in the same way as the force computation All threads update a single position simulaneously __global__ void update_positions_gpu(float4* positions, float4* velocities, float4* current_positions, float4* current_velocities, float3* forces, int size, float dt, float damping) { for(int index = __mul24(blockIdx.x,blockDim.x) + threadIdx.x; index < size; index += blockDim.x * gridDim.x) { float4 pos = current_positions[index]; float3 accel = forces[index]; float4 vel = current_velocities[index]; vel.x += accel.x * dt; vel.y += accel.y * dt; vel.z += accel.z * dt; vel.x *= damping; vel.y *= damping; vel.z *= damping; // new position = old position + velocity * deltaTime pos.x += vel.x * dt; pos.y += vel.y * dt; pos.z += vel.z * dt; // store new position and velocity positions[index] = pos; velocities[index] = vel; }")
17
O(n 2 )/p pipeline implementation ◦ Particles are divided among processes ◦ Particle positions are shared in a ring communication topology ◦ Force computation occurs for all particles by sending the data around the ring ◦ After all forces are computed each process updates the kinematics of its own particles
/p pipeline implementation ◦ Particles are divided among processes ◦ Particle positions are shared in a ring communication topology ◦ Force computation occurs for all particles by sending the data around the ring ◦ After all forces are computed each process updates the kinematics of its own particles")
18
Compiles with CPU and GPU implementations Timings have only been collected for CPU for(size_t i = 0; i < time_steps; i++) { memcpy( sendbuf, current_positions, num_particles * sizeof(vector4d_t) ); for (pipe=0; pipe<size; pipe++) { if (pipe != size-1) { MPI_Isend( sendbuf, num_particles, mpi_vector4d_t, right, pipe, commring, &request[0] ); MPI_Irecv( recvbuf, num_particles, mpi_vector4d_t, left, pipe, commring, &request[1] ); } compute_forces(positions,accel, num_particles, positions, num_particles, softening_squared); if (pipe != size-1) MPI_Waitall( 2, request, statuses ); memcpy( sendbuf, recvbuf, num_particles * sizeof(vector4d_t) ); } update_positions(positions, velocities, current_positions, current_velocities, accel, num_particles, dt, damping); }
![ Compiles with CPU and GPU implementations Timings have only been collected for CPU for(size_t i = 0; i < time_steps; i++) { memcpy( sendbuf, current_positions, num_particles * sizeof(vector4d_t) ); for (pipe=0; pipe<size; pipe++) { if (pipe != size-1) { MPI_Isend( sendbuf, num_particles, mpi_vector4d_t, right, pipe, commring, &request[0] ); MPI_Irecv( recvbuf, num_particles, mpi_vector4d_t, left, pipe, commring, &request[1] ); } compute_forces(positions,accel, num_particles, positions, num_particles, softening_squared); if (pipe != size-1) MPI_Waitall( 2, request, statuses ); memcpy( sendbuf, recvbuf, num_particles * sizeof(vector4d_t) ); } update_positions(positions, velocities, current_positions, current_velocities, accel, num_particles, dt, damping); }](http://images.slideplayer.com/13/3728248/slides/slide_18.jpg " Compiles with CPU and GPU implementations Timings have only been collected for CPU for(size_t i = 0; i < time_steps; i++) { memcpy( sendbuf, current_positions, num_particles * sizeof(vector4d_t) ); for (pipe=0; pipe<size; pipe++) { if (pipe != size-1) { MPI_Isend( sendbuf, num_particles, mpi_vector4d_t, right, pipe, commring, &request[0] ); MPI_Irecv( recvbuf, num_particles, mpi_vector4d_t, left, pipe, commring, &request[1] ); } compute_forces(positions,accel, num_particles, positions, num_particles, softening_squared); if (pipe != size-1) MPI_Waitall( 2, request, statuses ); memcpy( sendbuf, recvbuf, num_particles * sizeof(vector4d_t) ); } update_positions(positions, velocities, current_positions, current_velocities, accel, num_particles, dt, damping); }")
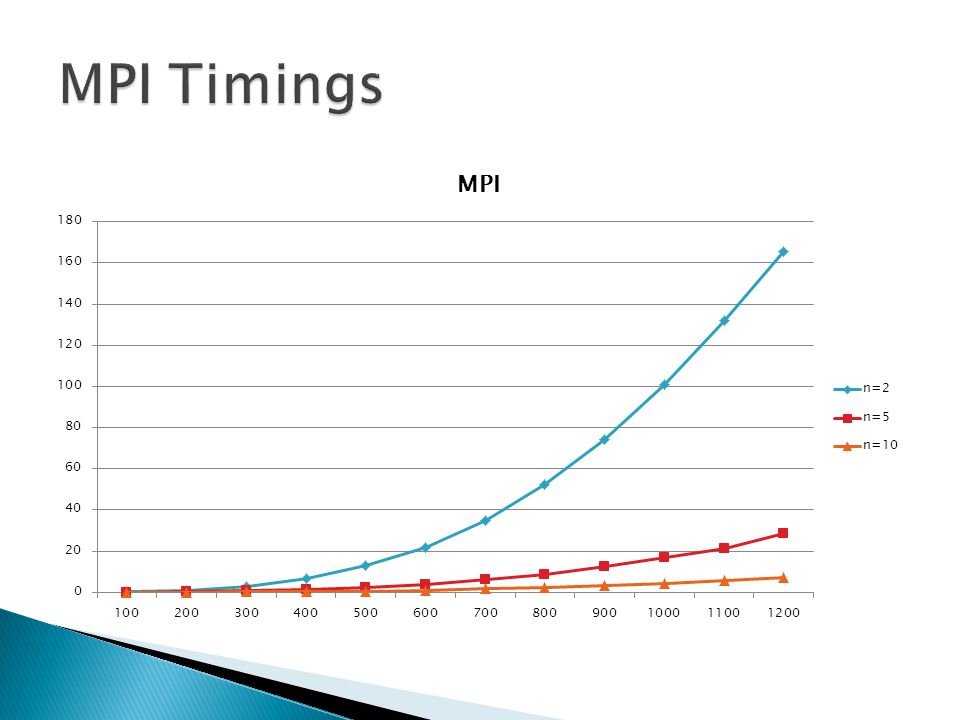
19
Taken of float for sequential and gpu Taken on tux for mpi All used 10 iterations for time steps Wallclock time was collected for comparison Memory allocation time was omitted ◦ Except for device memory allocation and device data transfer Timings where not collected for the code using MPI to distribute data over multiple nodes with multiple GPUs

26
We achieved several orders of magnitude speed-up going to a GPU We achieved similar results to what was obtained in GPU gems The sequential implementation was not optimal as it did not use SSE or multiple cores – much lower than the theoretical possible FLOPs for the Xeon CPU The MPI driver showed that task level parallelism can be exploited using distributed memory computing

27
Run the MPI GPU version on Draco FMM (Fast Multiple Method) MPI implementation Multi-device GPU implementation
 MPI implementation Multi-device GPU implementation")
Similar presentations














 No makeup class Friday! March 23, Guest Lecture Austin Robison,>")


 Supercomputing for the Masses by Peter Zalutski.>")






