Download presentation
Presentation is loading. Please wait.

1
MEOW: Metadata Enhancement and OAI Workshop

3
Metadata Enhancement, Sharing and OAI-PMH

4
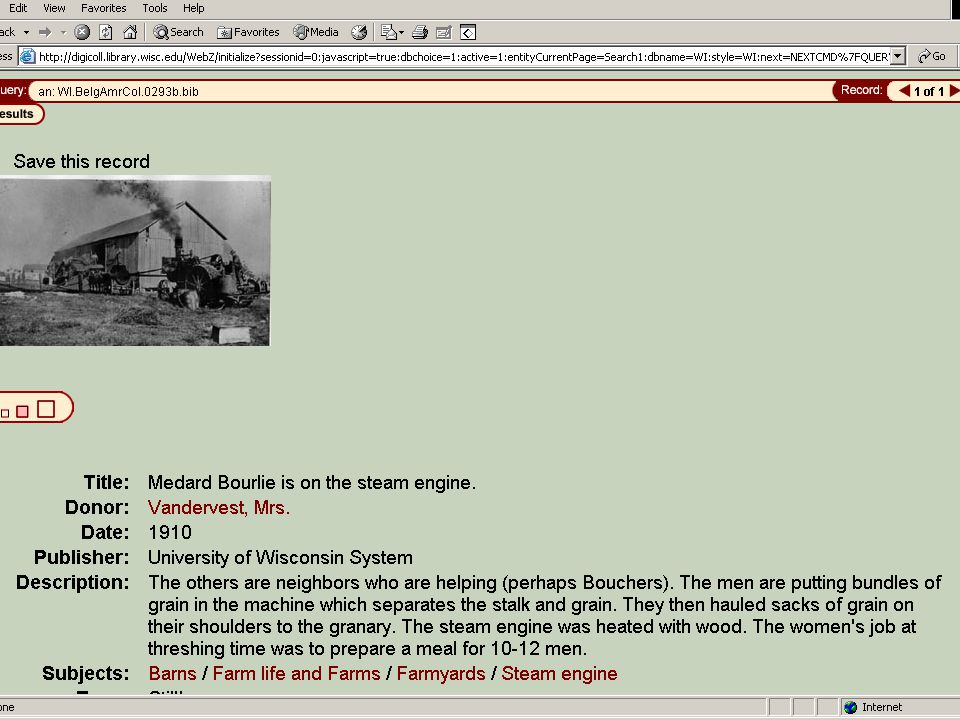
What does this record describe?
identifier: publisher: Museum of Zoology, Fish Field Notes format: jpeg rights: These pages may be freely searched and displayed. Permission must be received for subsequent distribution in print or electronically. type: image subject: ; 1926; 0812; 18; Trib. to Sixteen Cr. Trib. Pine River, Manistee R.; JAM26-460; 05; 1926/05/18; R10W; S26; S27; T21N language: UND source: Michigan 1926 Metzelaar, ; description: Flora and Fauna of the Great Lakes Region

6
Creating descriptive metadata
“Digital library” systems ContentDM ExLibris Digitool Greenstone Library catalogs Spreadsheets & databases XML

7
Some Emerging Trends in Metadata Creation
“Schema-agnostic” metadata Metadata that is both shareable and re-purposeable Harvestable metadata (OAI-PMH) “Non-exclusive”/”cross-cultural” metadata--i.e. it’s okay to combine standards from different metadata communities--e.g. MARC and CCO, DACS and AACR, DACS and CCO, EAD and CDWA Lite, etc. Importance of authorities--and difficulties in “bringing along” the power of authorities with shareable metadata records The need for practical, economically feasible approaches to metadata creation
 Non-exclusive / cross-cultural metadata--i.e. it’s okay to combine standards from different metadata communities--e.g. MARC and CCO, DACS and AACR, DACS and CCO, EAD and CDWA Lite, etc. Importance of authorities--and difficulties in bringing along the power of authorities with shareable metadata records. The need for practical, economically feasible approaches to metadata creation.")
8
Building “Good digital collections”
Interoperable – with the important goal of cross-collection searching Persistent – reliably accessible Re-usable – repositories of digital objects that can be used for multiple purposes

9
Issues Many significant digital collections lack standardized metadata
Such inconsistent metadata causes access problems, especially when collections are aggregated Enhancing metadata for existing collections is often difficult to undertake because of a lack of tools to automate the process

10
Issues IMLS grant: “Enhancing and Remediating Legacy Metadata for Effective Resource Sharing.” “Metadata today is likely to be created by people without any metadata training … metadata records are also created by automated means … unsurprisingly, the metadata resulting form these processes varies strikingly in quality and often does not play well together .. Nevertheless, many metadata aggregators use this metadata to build services for end users, thus contributing to criticisms that metadata is of limited value, can’t be trusted or that it’s demonstrably so incomplete as to be worthless”--Diane Hillman.

11
Issues Useful services depend on good metadata, but most metadata is not very good Human created metadata is expensive Automated crawling strategies are limited by: Accessibility barriers (rights issues, technical issues) Variable results with crawling technologies for non-text Best metadata does not rely solely on information contained within the resource itself Ex.: Controlled vocabularies, descriptions, links
 Variable results with crawling technologies for non-text. Best metadata does not rely solely on information contained within the resource itself. Ex.: Controlled vocabularies, descriptions, links.")
12
What is shareable metadata?
Is quality metadata Promotes search interoperability “the ability to perform a search over diverse sets of metadata records and obtain meaningful results.” Is human understandable outside of its local context Is useful outside of its local context Is machine processable

13
Shareable metadata defined
Promotes search interoperability - “the ability to perform a search over diverse sets of metadata records and obtain meaningful results” (Priscilla Caplan) Is human understandable outside of its local context Is useful outside of its local context Preferably is machine processable
 Is human understandable outside of its local context. Is useful outside of its local context. Preferably is machine processable.")
14
Why share metadata anyway?
Benefits to users Single search of a variety of digital resources Aggregation of subject-specific resources Higher quality resources Benefits to institutions Increased user access to collection by allowing metadata to appear in other places Exposure to broader audience, new users Surfacing rare, unknown, or scattered collections

15
Different shapes and sizes…
Range of different aggregations: focused subject area v. comprehensive specialized audience v. general audience Range of different displays

16
Metadata as a view of the resource
There is no monolithic, one-size-fits-all metadata record Metadata for the same thing is different depending on use and audience Affected by format, content, and context Descriptive vs. administrative vs. technical, etc. data

17
Metadata is a view of a resource
No monolithic, one-size-fits-all metadata record The view might be different depending on use and audience as well as format, content, and context Content standard is a view Metadata standard is a view Vocabulary used is a view

18
Choice of metadata format(s) as a view
Many factors affect choice of metadata formats Many different formats may all be appropriate for a single item High-quality metadata in a format not common in your community of practice is not shareable

19
Focus of description as a view
Link between records for analog and digital Hierarchical record with all versions Physical with link to digital All versions in flat record Content but not carrier

20
Finding the right balance
Metadata providers know the materials Document encoding schemes and controlled vocabularies Document practices Ensure record validity Aggregators have the processing power Format conversion Reconcile known vocabularies Normalize data Batch metadata enhancement

21
6 Cs and lots of Ss of shareable metadata
Content Consistency Coherence Context Communication Conformance Metadata standards Vocabulary and encoding standards Descriptive content standards Technical standards

22
Content Choose appropriate vocabularies Choose appropriate granularity
Make it obvious what to display Make it obvious what to index Exclude unnecessary “filler” Make it clear what links point to

23
Consistency Records in a set should all reflect the same practice
Fields used Vocabularies Syntax encoding schemes Allows aggregators to apply same enhancement logic to an entire group of records

24
Coherence Metadata format chosen makes sense for materials and managing institution Not just Dublin Core! Record should be self-explanatory Values must appear in appropriate elements Repeat fields instead of “packing” to explicitly indicate where one value ends and another begins

25
Context Include information not used locally
Exclude information only used locally Current safe assumptions Users discover material through shared record User then delivered to your environment for full context Context driven by intended use

26
Communication Method for creating shared records
Vocabularies and content standards used in shared records Record updating practices and schedules Accrual practices and schedules Existence of analytical or supplementary materials Provenance of materials

27
Conformance to Standards
Metadata standards (and not just DC) Vocabulary and encoding standards Descriptive content standards (AACR2, CCO, DACS) Technical standards (XML, Character encoding, etc)
 Vocabulary and encoding standards. Descriptive content standards (AACR2, CCO, DACS) Technical standards (XML, Character encoding, etc)")
28
Before you share… Check your metadata Appropriate view? Consistent?
Context provided? Does the aggregator have what they need? Documented? Can a stranger tell you what the record describes?

29
The reality of sharing metadata
We can no longer afford to only think about our local users Creating shareable metadata will require more work on your part Creating shareable metadata will require our vendors to support (more) standards Creating shareable metadata is no longer an option, it’s a requirement
 standards. Creating shareable metadata is no longer an option, it’s a requirement.")
30
So where does RDA fit in? RDA is a content standard
MODS is a metadata standard RDA is closely aligned with MARC and MODS Useful to have a RDA – MODS examples particularly as MODS is shifting away from MARC Although because of its origins in the library world RDA presupposes MARC as a vehicle for cataloging records, this emergent cataloging code could also be used with MODS, Dublin Core, or other metadata schemas. Lack of engagement with the MODS community beyond the Library of Congress

31
DLF Aquifer Guidelines
Does NOT recommend any one content standard over another “Choice and format of titles should be governed by a content standard such as the Anglo-American Cataloging Rules, 2nd edition (AACR2), Cataloguing Cultural Objects (CCO), or Describing Archives: A Content Standard (DACS). Details such as capitalization, choosing among the forms of titles presented on an item, and use of abbreviations should be determined based on the rules in a content standard. One standard should be chosen and used consistently for all records in an OAI set.”
, Cataloguing Cultural Objects (CCO), or Describing Archives: A Content Standard (DACS). Details such as capitalization, choosing among the forms of titles presented on an item, and use of abbreviations should be determined based on the rules in a content standard. One standard should be chosen and used consistently for all records in an OAI set.")
32
Metadata aggregators CIC Metadata Portal Records and digital resources shared by consortium of institutions, provided for Educators, researchers, and general public Benefits: Single comprehensive search of multiple collections and a variety of disciplines

36
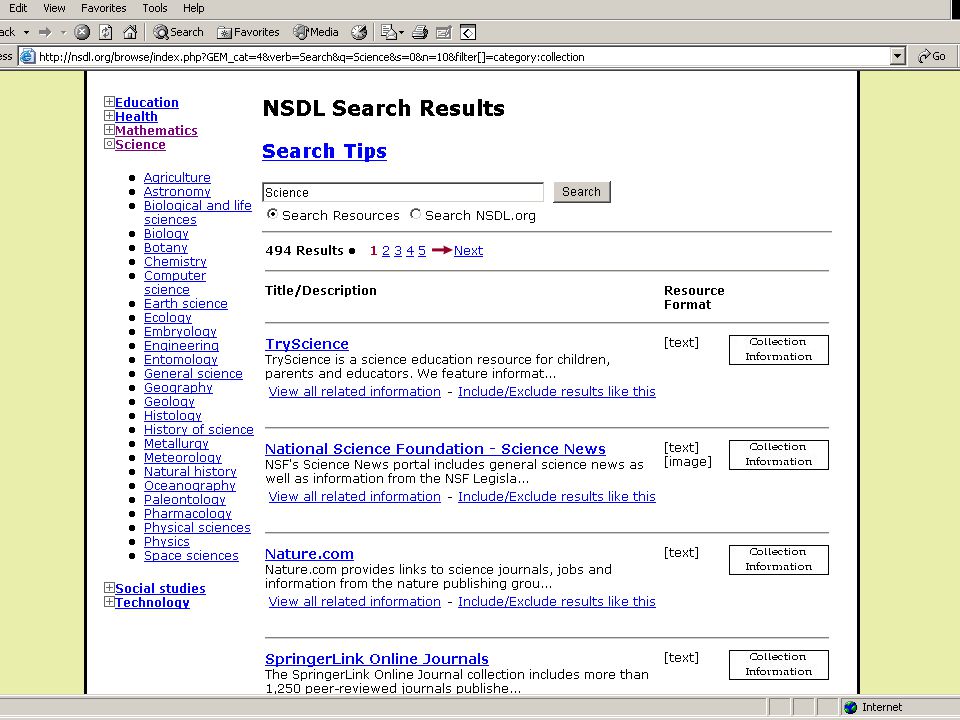
Metadata aggregators National Science Digital Library http://nsdl.org
Online resources and records pertaining to science & math education and research, vetted for inclusion, provided for Educators, researchers, policy makers, and the general public Benefits: Single portal serving a range of resources on a specialized topic to a diverse audience

40
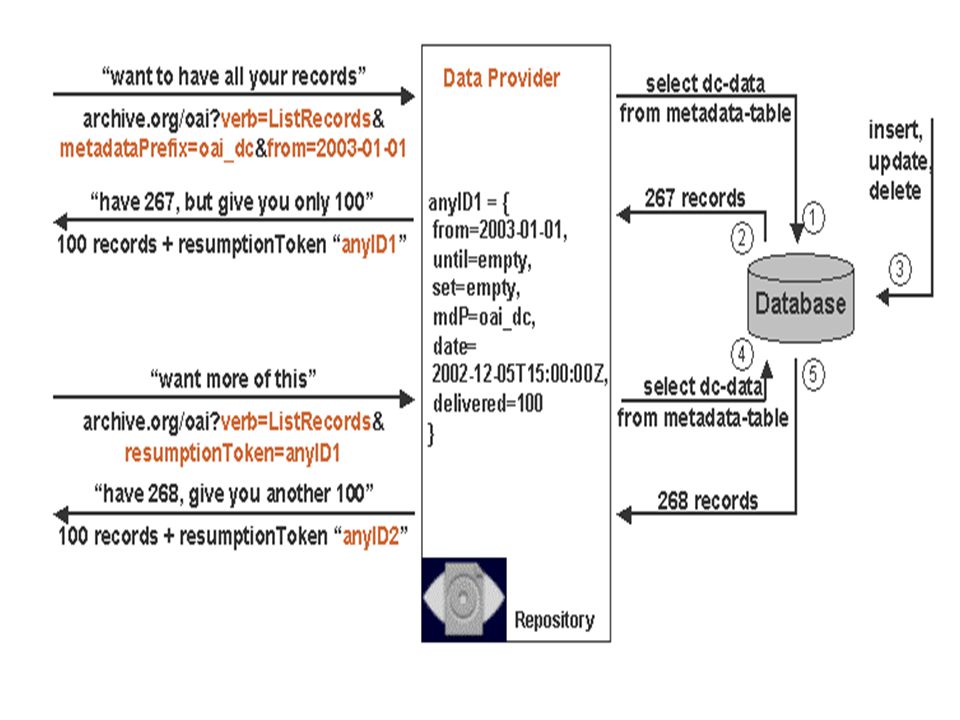
OAI-PMH Open Archives Initiative-Protocol for Metadata Harvesting
OAI-PMH defines a mechanism for harvesting records containing metadata from repositories. The OAI-PMH gives a simple technical option for data providers to make their metadata available to services, based on the open standards HTTP (Hypertext Transport Protocol) and XML (Extensible Markup Language). The metadata that is harvested may be in any format that is agreed by a community (or by any discrete set of data and service providers), although unqualified Dublin Core is specified to provide a basic level of interoperability
 and XML (Extensible Markup Language). The metadata that is harvested may be in any format that is agreed by a community (or by any discrete set of data and service providers), although unqualified Dublin Core is specified to provide a basic level of interoperability.")
41
OAI-PMH Metadata from many sources can be gathered together in one database, and services can be provided based on this centrally harvested, or "aggregated" data. Data Provider: a Data Provider maintains one or more repositories (web servers) that support the OAI-PMH as a means of exposing metadata. Service Provider: a Service Provider issues OAI-PMH requests to data providers and uses the metadata as a basis for building value-added services. A Service Provider in this manner is "harvesting" the metadata exposed by Data Providers
 that support the OAI-PMH as a means of exposing metadata. Service Provider: a Service Provider issues OAI-PMH requests to data providers and uses the metadata as a basis for building value-added services. A Service Provider in this manner is harvesting the metadata exposed by Data Providers.")
42
OAI-PMH Structure Intentionally designed to be simple Data providers
Have metadata they want to share “Expose” their metadata to be harvested Service providers Harvest metadata from data providers Provide searching of harvested metadata from multiple sources Can also provide other value-added services

43
Data Providers Set up a server that responds to harvesting requests
Required to expose metadata in simple Dublin Core (DC) format Can also expose metadata in any other format expressible with an XML schema
 format. Can also expose metadata in any other format expressible with an XML schema.")
44
Service Providers Harvest and store metadata
Generally provide search/browse access to this metadata Can be general or domain-specific Can choose to collect metadata in formats other than DC Generally link out to holding institutions for access to digital content OAIster is a good example

45
Pop Quiz What is the OAI-PMH? (Select one answer)
(a) The OAI-PMH is a protocol for sharing metadata. (b) The OAI-PMH is a low-barrier protocol for searching across repositories and retrieving resources from them.
 The OAI-PMH is a protocol for sharing metadata. (b) The OAI-PMH is a low-barrier protocol for searching across repositories and retrieving resources from them.")
46
Multiple Service Providers can harvest from multiple Data Providers.

47
Basic functioning of OAI-PMH

50
Finding the right balance
Metadata providers know the materials Document encoding schemes and controlled vocabularies Document practices Ensure record validity Aggregators have the processing power Format conversion Reconcile known vocabularies Normalize data Batch metadata enhancement

51
Why share metadata? Benefits to users Benefits to institutions
One-stop searching Aggregation of subject-specific resources Benefits to institutions Increased exposure for collections Broader user base Bringing together of distributed collections Don’t expect users will know about your collection and remember to visit it.

52
Why share metadata with OAI?
“Low barrier” protocol Shares metadata only, not content, simplifying rights issues Same effort on your part to share with one or a hundred service providers (basically) Wide adoption in the cultural heritage sector Quickly eclipsed older methods such as Z39.50
 Wide adoption in the cultural heritage sector. Quickly eclipsed older methods such as Z")
53
Common Problems with Metadata in Aggregation
Consistency Sufficiency Compatibility

54
Consistency problems Appearance of data Application of format
Granularity of records Vocabulary usage Result: Service Provider must normalize data (if can determine what “normal” is)
")
55
Sufficiency problems Too little info for understanding what resource is, especially outside of local context Result: Users don’t know whether a resource is relevant or not

56
Compatibility problems
Information in records is Erroneous Unnecessary Incompatible Result: Interferes with harvesting and indexing

57
Common content mistakes
No indication of vocabulary used Names LCNAF: Michelangelo Buonarroti, ULAN: Buonarroti, Michelangelo Places LCSH: Jakarta (Indonesia) TGN: Jakarta Subjects LCSH: Neo-impressionism (Art) AAT: Pointillism Shared record for a single page in a book Link goes to search interface rather than item being described “Unknown” or “N/A” in metadata record
 TGN: Jakarta. Subjects. LCSH: Neo-impressionism (Art) AAT: Pointillism. Shared record for a single page in a book. Link goes to search interface rather than item being described. Unknown or N/A in metadata record.")
58
Common context mistakes
Leaving out information that applies to an entire collection (“On a horse”) Location information lacking parent institution Geographic information lacking higher-level jurisdiction Inclusion of administrative metadata
 Location information lacking parent institution. Geographic information lacking higher-level jurisdiction. Inclusion of administrative metadata.")
59
1. Duplication problem Different collections describing same source:

61
Duplication problems Duplicates can be identical records,
can describe the same source, but with different metadata, and can describe the same source but with links to different or slightly different location identifiers (e.g. index page vs. splash page).
.")
62
2. Record quality could be different
No date. No format, type, grade level, language, rights, etc. Description might be based on the then table of contents.

63
No date. Description might be based on the then cover page. Description is no longer relevant. Format missed images. No grade level, rights.

64
No date. Description is more general and can last longer. + Recorded grade level, format, type + No language, rights.

65
Completeness Search & Display
3. Incomplete data causes low recall Completeness Search & Display No FORMAT information

66
Completeness Search & Display (cont.)
Collections which did not provide FORMAT information are excluded from being searched at advanced searches

67
Completeness Search & Display (cont.)
Collections did not use EDUCATIONLEVEL or AUDIENCE element would not be in the pool when a user searches by Grade Level.

68
Expectations for discovery systems are rising
Growth of cutting-edge systems outside of libraries affecting user expectations Higher user expectations are a good thing! Many expected functions will be easier with robust structured metadata Genre access Faceted browsing Limiting scope by time, place, etc.

69
Libraries are having trouble meeting those expectations
Non-textual resources are more difficult to search Legacy metadata isn’t always structured in ways that allow high-level services Legacy metadata doesn’t always include enough information to allow high-level services Creating new metadata needed to provide high-level services is prohibitively expensive

70
Enter automated enhancement methods
Much research has been done Little of it has been put into production systems in library metadata creation environments Still requires human intervention Fear of human skills becoming devalued Metadata aggregators, out of necessity, are among the first implementers Automatic enhancement holds great promise for standardizing and streamlining metadata creation and aggregation activities

71
Why Enhance Metadata at All?
Four categories of problems limit metadata usefulness: Missing data: elements not present Incorrect data: values not conforming to proper usage Confusing data: embedded html tags, improper separation of multiple elements, etc. Insufficient data: no indication of controlled vocabularies, formats, etc.

72
Solving the problems -- Enriching and enhancing harvested records
Metadata Repository Enriched record Aggregation

73
Aggregation It is possible that these problems be eliminated to certain level through a process called ‘aggregation’ in a metadata repository. The notion behind this process is that a metadata record, “a series of statements about resources,” can be aggregated to build a more complete profile of a resource.

75
Incorrect element mapping
Data-conversion-related problems Incorrect element mapping OPTIONS mapped to SUBJECT, missing all KEYWORDS missed?! missing keywords

76
AUTHOR mapped to DESCRIPTION, no CREATOR

77
Only physical description, no content description

78
Inappropriate mapping
CLASSIFICATION mapped to SUBJECT and missed all the KEYWORDs.

79
Solving the problems -- Correcting the errors
Checking and testing crosswalks!!! Re-harvesting Training how to use OAI tools

80
Value space that should follow standardized rules: Examples from values associated with DATE element
1979 T21:48.00Z 200003 C1999, 2000 January, 1919 May, 1919 1987, c2000 ?1999 1952 (issued) (1982) 1930?] Between 1680 and 1896? dc.date: Recommended best practice for encoding the date value is defined in a profile of ISO 8601 [W3CDTF] and includes (among others) dates of the form YYYY-MM-DD
 (1982) 1930 ] Between 1680 and 1896 dc.date: Recommended best practice for encoding the date value. is defined in a profile of ISO 8601 [W3CDTF] and includes. (among others) dates of the form YYYY-MM-DD.")
81
German LOCLANGUAGE:: German
Value space that should apply standard controlled vocabularies: Examples from values associated with LANGUAGE element en eng en-GB en-US English engfre new Korean Deutsch German LOCLANGUAGE:: German dc.language: Recommended best practice is to use RFC 3066 [RFC3066] which, in conjunction with ISO639 [ISO639]), defines two- and three-letter primary language tags with optional subtags.
, defines two- and three-letter primary language tags with optional subtags.")
82
Two efforts to promote shareable metadata
Best Practices for OAI Data Provider Implementations and Shareable Metadata Digital Library Federation / Aquifer Implementation Guidelines for Shareable MODS Records

83
Everyone could use better metadata!
?

84
Metadata Enhancement Clustering and classification
Automated name authority control Date normalization Thumbnail generation and creating actionable URLs

85
Clustering and classification
UC-Irvine and Michigan Evaluate topic/subject-based metadata enhancement Clustering: “learning the topics” (pre-process) Classification: using the learned topics to determine topics in records and records in topics
 Classification: using the learned topics to determine topics in records and records in topics.")
86
Topic Model State-of-the-art statistical algorithm
Learns a set of topics or subjects covered by a collection of text records Works by finding patterns of co-occurring words Determines the mix of topics associated with each record

87
Clustering and classification
Mix of scientific repositories Average of 75 words per record Used words from <title>, <description>, <subject> for clustering Only kept words that occurred in more than 10 records Result: a final vocabulary of 90,000 words Cluster words into topics: ended up with 500 topics

88
Clustering and classification
500 topics too many to look at Needed to organize topics under broad topical categories Cluster the clusters (automatic) Use pre-defined categories Classify group of keywords (manual + automatic) Create hierarchy by hand (manual)
 Use pre-defined categories. Classify group of keywords (manual + automatic) Create hierarchy by hand (manual)")
89
clustering is learning the topics
vocab- ulary Cluster preprocess topic model (cluster/learn) topics OAI records vocab -ulary Classify preprocess topic model (classify) 1. topics in records 2. records in topics OAI records classification is using the learned topics
 topics. OAI. records. vocab. -ulary. Classify. preprocess. topic. model. (classify) 1. topics in records. 2. records in topics. OAI. records. classification is using the learned topics.")
90
Preprocessing Example
<ID=oai:CiteSeerPSU:44072> <title>Reinforcement Learning: A Survey <description>This paper surveys the field of reinforcement learning from a computer-science perspective. It is written to be accessible to researchers familiar with machine learning. Both the historical basis of the field and a broad selection of current work are summarized. Reinforcement learning is the problem faced by an agent that learns behavior through trial-and-error interactions with a dynamic environment. The work described here has a resemblance to work in psychology, but differs considerably in the details and in the use of the word "reinforcement." … <subject>Leslie Pack Kaelbling, Michael Littman, Andrew Moore. Reinforcement Learning: A Survey vocab -ulary <ID=oai:CiteSeerPSU:44072> reinforcement learning survey survey field reinforcement learning computer science perspective written accessible researcher familiar machine learning historical basis field broad selection current summarized reinforcement learning faced agent learn behavior trial error interaction dynamic environment resemblance psychology differ considerably detail word reinforcement … leslie pack kaelbling littman andrew moore reinforcement learning survey preprocess

91
Example Topics (1) Words in Topic Topic Label
gene sequence genes sequences cdna region amino_acid clones encoding cloned coding dna genomic cloning clone gene sequencing social cultural political culture conflict identity society economic context gender contemporary politic world examines tradition sociology institution ethic discourse cultural identity general_relativity gravity gravitational solution black_hole tensor einstein horizon spacetime equation field metric vacuum scalar matter energy relativity relativity house garden houses dwelling housing homes terrace estate home building architecture residence homestead residences road cottage domestic fences lawn historic domestic architecture

92
Example Topics (2) Words in Topic Usefulness
large small size larger smaller sizes scale sized largest Reasonable but unusable foi para pacientes por foram dos doen resultados grupo das tratamento entre Topic about patient treatment, in Spanish building street visible santa_ana view avenue public_library front orange corner Not usable: mix of concept words and specific geographic location words

93
Topics Assigned to a Record
Metadata Record Topic Labels (% words assigned) Aggregating sets of judgments: two impossibility results compared (C. List and P. Pettit) May's celebrated theorem (1952) shows that, if a group of individuals wants to make a choice between two alternatives (say x and y), then majority voting is the unique decision procedure satisfying a set of attractive minimal conditions ... game theory (21%) argument (12%) criteria (7%)
 Aggregating sets of judgments: two impossibility results compared. (C. List and P. Pettit) May s celebrated theorem (1952) shows that, if a group of individuals wants to make a choice between two alternatives (say x and y), then majority voting is the unique decision procedure satisfying a set of attractive minimal conditions ... game theory (21%) argument (12%) criteria (7%)")
96
Clustering and classification
Selected useful topics [ t482 ] labor worker employment wage market labour job unemployment wages earning panel find evidence individual participation skill [ t372 ] firm investment capital productivity innovation industry sector economic industrial foreign industries corporate ownership technological companies evidence

97
Clustering and classification
Selected less useful topics [ t255 ] journal author chapter vol notes editor publication issue special bibliography reader references appendix literature submitted topic [ t013 ] university department mail edu institute science california usa computer york fax college press center address

98
Broad Topical Categories (BTCs)
By clustering the clusters Worked well Can choose desired number of BTCs By classifying groups of keywords Worked well too Then review and manually edit Include or exclude any subtopic

101
Clustering and classification: Further evaluation
Need to test non-English and cultural heritage repositories Need usability testing “On the horse” problem more prevalent When to re-cluster?

102
Automated Name Authority Control (ANAC)
Johns Hopkins University: research only; never implemented 29,000 Levy sheet music records 13,764 unique names

103
ANAC The evidence used to determine the probability of a match between a name to an LC record is a set of Boolean tests involving the name, the Levy metadata associated with that name, and the LC record. The following fields were used by ANAC: Levy record: Given name: often abbreviated Middle names: often abbreviated Family name Modifiers: titles and suffixes Date: publication year Location: publication location (city) LC record: Given name: includes abbreviations Middle names: includes abbreviations Birth: year of birth Death: year of death Context: miscellaneous data
 LC record: Given name: includes abbreviations. Middle names: includes abbreviations. Birth: year of birth. Death: year of death. Context: miscellaneous data.")
104
ANAC The tests used are: first name equality and consistency, middle name equality and consistency, music terms present in LC record context, name modifier consistency, Levy sheet music publication consistent with LC author birth and death, and Levy record publication location in LC record context

105
ANAC In order to train the system, the Cataloging Department at the Sheridan Libraries generated ground truth data. For each name in 2,000 randomly selected Levy metadata records, catalogers recorded the authorized form of the name when a matching authority record was available. The entire process required 311 hours (approximately seven minutes per name). The human catalogers used much the same type of evidence as ANAC in establishing matches. Catalogers examined name similarity; compared publication dates from the Levy records to birth and death dates in the authority records; and examined authority record note fields for musical terms. In addition, the catalogers often searched for bibliographic records of other editions of a particular title to determine the authoritative name assigned to the subject.
. The human catalogers used much the same type of evidence as ANAC in establishing matches. Catalogers examined name similarity; compared publication dates from the Levy records to birth and death dates in the authority records; and examined authority record note fields for musical terms. In addition, the catalogers often searched for bibliographic records of other editions of a particular title to determine the authoritative name assigned to the subject.")
106
ANAC Overall, ANAC was successful 58% of the time. When a name had an LC record, ANAC was successful 77% of the time, but when an LC record did not exist for a name ANAC was successful only 12% of them time. The reason for this discrepancy is that ANAC cannot learn whether or not a name has been added to the LC authority file. It took ANAC five hours and forty-five minutes to classify the 2,673 (2,841 minus 168) names, or about eight seconds per name. The database-bound process of retrieving the candidate set of MARC records given a family name consumed most of this time.
 names, or about eight seconds per name. The database-bound process of retrieving the candidate set of MARC records given a family name consumed most of this time.")
107
ANAC Matching very dependent on contextual data
Machine matching much faster than manual (8 sec. vs. 7 min.) Performance reasonable even with dirty metadata. Machine matching could enhance manual work Combination of machine processing and human intervention produced best results Approach could be tweaked by comparing names to multiple authority files or domain specific databases ANAC not a generalizable tool, but there are others
 Performance reasonable even with dirty metadata. Machine matching could enhance manual work. Combination of machine processing and human intervention produced best results. Approach could be tweaked by comparing names to multiple authority files or domain specific databases. ANAC not a generalizable tool, but there are others.")
108
Date Normalization How to make “ca. 1880” a machine-readable date but not a 19-2 baseball score California Digital Library Created for American West project, so sidestepped issue of B.C.E. date normalization Uses <date> element If no <date>, searches for date-like strings in <title>, then <description> Currently normalizes to YYYY only, not MM or DD (will add later)
")
109
<date>: Encoding Variances
ca (ca). 1920) by CAD Unknown ca. June 19, 1901. (ca). June 19, 1901) [2001 or 2002.] 1853. c1875. c1908 November 19 c1905 1929 June 6 [between 1904 and 1908] [ca. 1967] 1918 ? [1919 ?] 191-? 1870 December, c1871 1920, 1921, 1922, 1923, 1924, 1925, 1926, 1927, 1928, 1929
. 1920) by CAD. Unknown. ca. June 19, (ca). June 19, 1901) [2001 or 2002.] c1875. c1908 November 19. c June 6. [between 1904 and 1908] [ca. 1967] 1918 [1919 ] December, c , 1921, 1922, 1923, 1924, 1925, 1926, 1927, 1928,")
110
Normalization Process
Extract dates Standardize approximate dates, e.g. ca = 1902~ CDL uses +/- 5 years e.g. 1902~ = Normalize Dates Populate date.found or date.guess Create era, decade and year tokens

111
Recognizing Unknowns Recognizes wide range of expression of date unknownness in <date> element, e.g. unknown, unkn, unavail, n.d., nd, undated, no date, not indicated Looks for date-like strings to normalize in <title>, then <description> when <date> element contains one of these expressions If no date, look for Civil War, Renaissance, dates of reigns of sovereigns, etc.

112
Known Issues Distinguishing “c” for circa from “c” for copyright (currently interprets as later) Getting tripped up by baseball scores in non-<date> elements Getting tripped up by 4-digit item identifiers

113
Thumbnail generation and creating actionable URLs
Thumbnail: “A miniature representation of a page or image that is used to identify a file by its content”—PC Magazine Need coordination between metadata harvesting and thumbnail grabbing Digital libraries need digital objects <identifier> element in DC is a problem: hard to identify link to actual object

114
Thumbnail generation and creating actionable URLs
“Users should be able to download, manipulate, morph, annotate, cross-search, and repurpose digital library content” Find best possible link, find best possible image, build thumbnail: registry of links; data providers retain the responsibility of maintaining the authoritative version of their resource Need to find a way to express intellectual property rights related to manipulation of objects Try to get providers to supply better metadata, but in mean time use what we’ve got

115
Characteristics of quality metadata:
Completeness. -- choosing an element set allowing the resources in question to be described as completely as is economically feasible, and -- applying that element set as completely as possible. Accuracy. -- the metadata being correct and factual, and conforming to syntax of the element set in use. Provenance. Here provenance refers to the provision of information about the expertise of the person(s) creating the original metadata, and its transformation history. Conformance to expectations. Metadata elements, use of controlled vocabularies, and robustness should match the expectations of a particular community. Logical consistency and coherence. -- element usage matching standard definitions, and consistent application of these elements. Timeliness. Currency--metadata keeping up with changes to the resource it describes. Lag -- a resource’s availability preceding the availability of its metadata. Accessibility. Proper association of metadata with the resource it describes and readability by target users contribute to this characteristic.
 creating the original metadata, and its transformation history. Conformance to expectations. Metadata elements, use of controlled vocabularies, and robustness should match the expectations of a particular community. Logical consistency and coherence. -- element usage matching standard definitions, and consistent application of these elements. Timeliness. Currency--metadata keeping up with changes to the resource it describes. Lag -- a resource’s availability preceding the availability of its metadata. Accessibility. Proper association of metadata with the resource it describes and readability by target users contribute to this characteristic.")
116
Additional characteristics that make quality metadata more useful in a shared environment:
Proper context. … each record contain the context necessary for understanding the resource the record describes, without relying on outside information. Content coherence. … need to contain enough information such that the record makes sense standing on its own, yet exclude information that only makes sense in a local environment. Use of standard vocabularies. The use of standard vocabularies enables the better integration of metadata records from one source with records from other sources. Consistency. All decisions made about application of elements, syntax of metadata values, and usage of controlled vocabularies, should be consistent within an identifiable set of metadata records so those using this metadata can apply any necessary transformation steps without having to process inconsistencies within such a set. Technical conformance. Metadata should conform to the specified XML schemas and should be properly encoded.

117
How Can We Ensure A Better Quality?
Make Policies on: minimum quality requirements, quality measurement instruments, quality enforcement policies, quality enhancement actions, and the training of metadata creators. Training! A 2-hour training may eliminate hundreds of errors IT team should talk with content team A test of crosswalk for OAI harvest may prevent thousands of mis-matched or missed values Use Tools: Provide instructions on best practices Use template for inputting records, with suggested syntax, vocabularies, and build-in values Use validators Implement duplicate checking algorithm

118
Final Thoughts Creating shareable metadata requires thinking outside of our local box Creating shareable metadata will require more work on our part Creating shareable metadata will require our vendors to support (more) standards Creating shareable metadata is no longer an option, it’s a requirement
 standards. Creating shareable metadata is no longer an option, it’s a requirement.")
119
Before we share… Check our metadata Appropriate view? Consistent?
Context provided? Does the aggregator have what they need? Documented? Can a stranger tell you what the record describes?

120
More thoughts Automated metadata enhancement techniques promise to play an essential role in building and aggregating digital library collections But they are not a “magic bullet” – must be used together with other techniques User-contributed metadata Content-based retrieval Item-level attention by specialists Many collections could benefit Legacy collections described in MARC Special collections largely undescribed, especially at the item level Should technical services expand metadata activities Catalogers and their skills essential to this process

121
The Way Forward? Service providers should be more demanding (i.e. require that data providers adhere to certain standards and use certain vocabularies, require “pre-washed” metadata. Data providers should consistently use appropriate standard schemas in their local systems. Service providers should consider “adding value” via services like vocabulary mapping, query expansion, vocabulary-assisted searching, user-added metadata, post-harvest subsetting, metadata enhancement, etc

122
Lessons Learned Metadata (descriptive, technical, rights, administrative, preservation) is one of your biggest investments. Do it once, do it right (consistent schemas, controlled vocabularies), and you can re-purpose metadata in a wide variety of ways. Good descriptive metadata records can be core—records don’t need to be “full” to be “good.” Creation of consistent, standards-based descriptive metadata (a.k.a. cataloging!) is time- and labor-intensive, but it’s worth it.
, and you can re-purpose metadata in a wide variety of ways. Good descriptive metadata records can be core—records don’t need to be full to be good. Creation of consistent, standards-based descriptive metadata (a.k.a. cataloging!) is time- and labor-intensive, but it’s worth it.")
Similar presentations


























 Byte: Group of bits that represents a single.>")

 metadata scheme to determine its utility based on structure, interoperability.>")



 NISO Metadata Workshop May 20, 2004 Rebecca Guenther Network Development and MARC Standards Office Library.>")
