Download presentation
Presentation is loading. Please wait.

1
Unsupervised Detection of Anomalous Text David Guthrie The University of Sheffield

2
Textual Anomalies Computers are routinely used to detect differences from what is normal or expected –fraud –network attacks Principal focus of this research is to similarly detect text that is irregular We view text that deviates from its context as a type of anomaly

3
New Document Collection Anomalous Documents?

4
Find text that is unusual

5
New Document Anomalous Segments?

6
New Document Anomalous Segments?

7
New Document Anomalous Segments?

8
New Document Anomalous Segments? Anomalous

9
Motivation Plagiarism –Writing style of plagiarized passages anomalous with respect to the rest of the authors work –Detect such passages because writing is “odd” not by using external resources (web) Improving Corpora –Automatically gathered corpora can contain errors. Improve the integrity and homogeneity. Unsolicited Email –E.g. Spam constructed from sentences Undesirable Bulletin Board or Wiki posts –E.g. rants on wikipedia

10
Goals To develop a general approach which recognizes: –different dimensions of anomaly –fairly small segments (50 to 100 words) –Multiple anomalous segments
 –Multiple anomalous segments")
11
Unsupervised For this task we assume there is no training data available to characterize “normal” or “anomalous” language When we first look at a document we have no idea which segments are “normal” and which are “anomalous” Segments are anomalous with respect to the rest of the document not to a training corpus

12
Outlier Detection Treat the problem as a type of outlier detection We aim to find pieces of text in a corpus that differ significantly from the majority of text in that corpus and thus are ‘outliers’

13
Characterizing Text 166 features computed for every piece of text (many of which have been used successfully for genre classification by Biber, Kessler, Argamon, …) Simple Surface Features Readability Measures POS Distributions (RASP) Vocabulary Obscurity Emotional Affect (General Inquirer Dictionary)
 Simple Surface Features Readability Measures POS Distributions (RASP) Vocabulary Obscurity Emotional Affect (General Inquirer Dictionary)")
14
Readability Measures Attempt to provide a rough indication of the reading level required for a text Purported to correspond how “easily” a text is read Work well for differentiating certain texts ( Scores are Flesch Reading Ease) Romeo & Juliet 84 Plato’s Republic 69 Comic Books 92 Sports Illustrated 63 New York Times 39 IRS Code -6
 Romeo & Juliet 84 Plato’s Republic 69 Comic Books 92 Sports Illustrated 63 New York Times 39 IRS Code -6")
15
Readability Measures Flesch-Kincaid Reading Ease Flesch-Kincaid Grade Level Gunning-Fog Index Coleman-Liau Formula Automated Readability Index Lix Formula SMOG Index

16
Obscurity of Vocabulary Implemented new features to capture vocabulary richness used in a segment of text Lists of most frequent words in Gigaword Measure distribution of words in a segment of text in each group of words Top 1,000 words Top 5,000 words Top 10,000 words Top 50,000 words Top 100,000 words Top 200,000 words Top 300,000 words

17
Part-of-Speech All segments are passed through the RASP (Robust and Accurate Statistical Parser) part-of-speech tagger All words tagged with one of 155 part-of-speech tags from the CLAWS 2 tagset
 part-of-speech tagger All words tagged with one of 155 part-of-speech tags from the CLAWS 2 tagset")
18
Part-of-Speech Ratio of adjectives to nouns % of sentences that begin with a subordinating or coordinating conjunctions (but, so, then, yet, if, because, unless, or…) % articles % prepositions % pronouns % adjectives %conjuctions Diversity of POS trigrams
 % articles % prepositions % pronouns % adjectives %conjuctions Diversity of POS trigrams")
19
Morphological Analysis Texts are also run through the RASP morphological analyser, which produces words lemmas and inflectional affixes Gather statistics about the percentage of passive sentences and amount of nominalization were made thinking apples be + ed make + ed think + ing apple + s

20
Rank Features Store lists ordered by the frequency of occurrence of certain stylistic phenomena Most frequent POS trigrams list Most frequent POS bigram list Most frequent POS list Most frequent Articles list Most frequent Prepositions list Most frequent Conjunctions list Most frequent Pronouns list

21
List Rank Similarity To calculate the similarity between two segments lists, we use the Spearman’s Rank Correlation measure

22
Sentiment General Inquirer Dictionary (Developed by social science department at Harvard) 7,800 words tagged with 114 categories: –Positive –Negative –Strong –Weak –Active –Passive –Overstated –Understated –Agreement –Disagreement and many more … - Negate - Casual slang - Think - Know - Compare - Person Relations - Need - Power Gain - Power Loss - Affection - Work
 7,800 words tagged with 114 categories: –Positive –Negative –Strong –Weak –Active –Passive –Overstated –Understated –Agreement –Disagreement and many more … - Negate - Casual slang - Think - Know - Compare - Person Relations - Need - Power Gain - Power Loss - Affection - Work")
23
Representation Characterize each piece of text (document, segment, paragraph, …) in our corpus as a vector of features Use these vectors to construct a matrix, X, which has number of rows equal to the pieces of text in the corpus and number of columns equal to the number of features
 in our corpus as a vector of features Use these vectors to construct a matrix, X, which has number of rows equal to the pieces of text in the corpus and number of columns equal to the number of features")
24
Feature Matrix X segf1f2f3f4f5f6f7…fpfp 1 2 3 4 5 6 7 … n Represent each piece of text as a vector of features Document or corpus

25
Feature Matrix X segf1f2f3f4f5f6f7…fpfp 1 2 3 4 5 6 7 … n Identify outlying Text Document or corpus

26
Approaches Mean Distance: Compute average distance from other segments Comp Distance: compute a segment’s difference from its complement SDE Distance Find the projection of the data where segments appear farthest

27
Mean Distance

28
Finding Outlying Segments Feature Matrix segf1f2f3f4f5f6f7…fn 1 2 3 4 5 6 7 … n Calculate the distance from segment 1 to segment 2 Dist =.5

29
Finding Outlying Segments Feature Matrix segf1f2f3f4f5f6f7…fn 1 2 3 4 5 6 7 … n Calculate the distance from segment 1 to segment 3 Dist=.3

30
Finding Outlying Segments Feature Matrix se g f1f1 f2f2 f3f3 f4f4 f5f5 f6f6 f7f7 …fnfn 1 2 3 4 5 6 7 … n Build a Distance Matrix

31
Finding Outlying Segments Feature Matrix se g f1f1 f2f2 f3f3 f4f4 f5f5 f6f6 f7f7 …fnfn 1 2 3 4 5 6 7 … n Choose the segment that is most different Distance Matrix outlier

32
Ranking Segments Feature Matrix Distance Matrix List of Segments Produce a Ranking of Segments

33
Distance Measures Cosine Similarity Measure d = 1 - s City Block Distance Euclidean Distance Pearson Correlation Coefficient d = 1 - r

34
Standardizing Variables Desirable for all variables to have about the same influence We can express them each as deviations from their means in units of standard deviations (Z score) Or Standardize all variables to have a minimum of zero and a maximum of one
 Or Standardize all variables to have a minimum of zero and a maximum of one")
35
Comp Distance

36
Distance from complement New Document or corpus

37
Distance from complement Segment the text

38
Distance from complement segf1f2f3f4f5f6f7…fn 1 2 3 4 5 6 7 … n Characterize one segment

39
Distance from complement Characterize the complement of the segment

40
Distance from complement Compute the distance between the two vectors D=.4

41
Distance from complement For all segments D=.4

42
Distance from complement Compute distance between segments D=.6 D=.4

43
Rank by distance from complement Next, segments are ranked by their distance from the complement In this scenario we can make good use of list features

44
SDE Dist

45
SDE Use the Stahel-Donoho Estimator (SDE) to identify outliers Project the data down to one dimension and measure the outlyingness of each piece of text in that dimension For every piece of text, the goal is to find a projection of the that maximizes its robust z- score Especially suited to data with a large number of dimensions (features)
 to identify outliers Project the data down to one dimension and measure the outlyingness of each piece of text in that dimension For every piece of text, the goal is to find a projection of the that maximizes its robust z- score Especially suited to data with a large number of dimensions (features)")
46
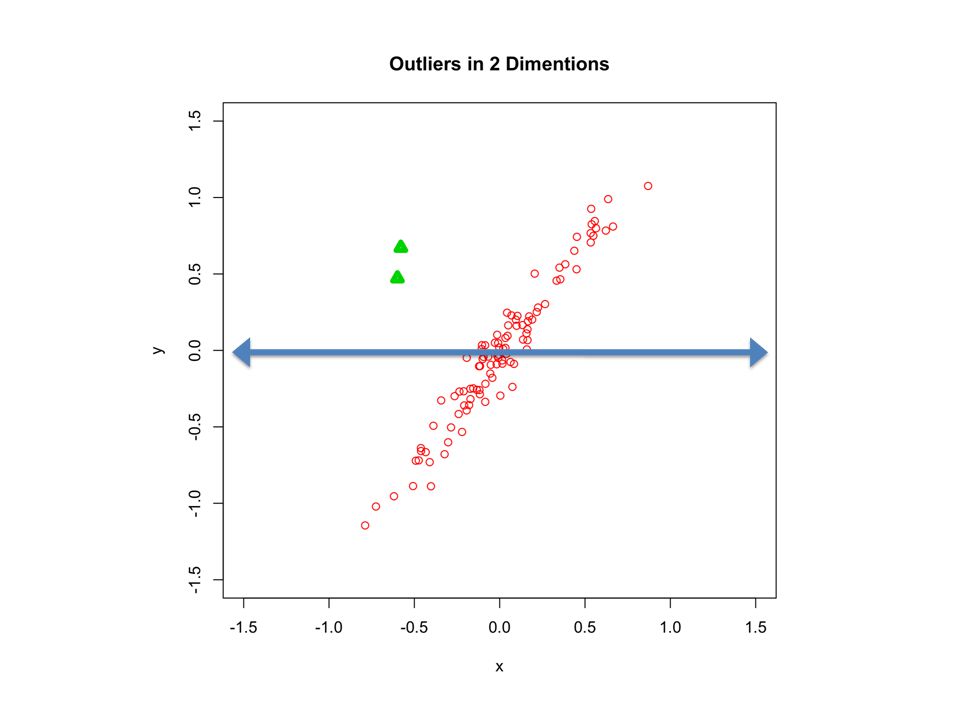
Outliers are ‘hidden’

48
Robust Zscore of furthest point is <3

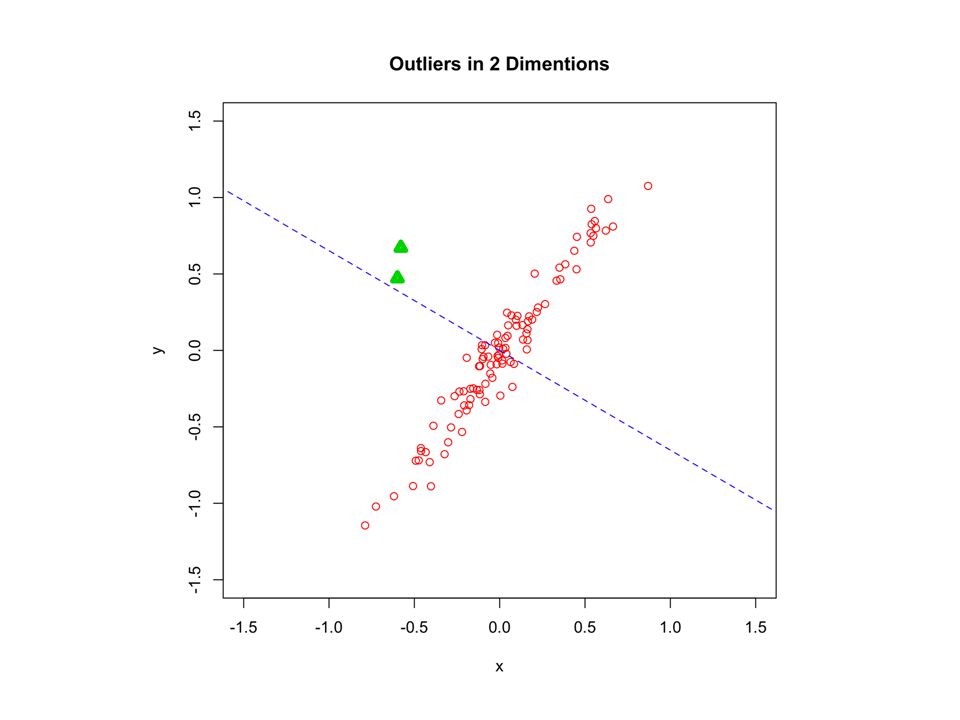
51
Robust z score for triangles in this Projection is >12 std dev

54
Outliers are clearly visible

56
SDE Where a is a direction (unit length vector) and x i a is the projection of row x i onto direction a mad is the median absolute deviation
 and x i a is the projection of row x i onto direction a mad is the median absolute deviation")
57
Anomalies have a large SD The distances for each piece of text SD(x i ) are then sorted and all pieces of text are ranked
 are then sorted and all pieces of text are ranked")
58
Experiments In each experiment we randomly select 50 segments of text from a corpus and insert one piece of text from a different source to act as an ‘outlier’ Rank segments We varied the size of the pieces of text from 100 to 1000 words

59
Normal Population Anomalous Population Creating Test Documents

60
Normal Population Anomalous Population Creating Test Documents

61
Normal PopulationAnomalous Population

62
Test Document Creating Test Documents Now we attempt to spot this anomaly

63
Creating Test Documents Normal PopulationAnomalous Population Test documents are created for every segment in anomalous text

64
New Document System Output: a ranking Most Anomalous 2nd Most Anomalous 3nd Most Anomalous

65
Author Tests Compare 8 different authors »Bronte »Carroll »Doyle »Eliot »James »Kipling »Tennyson »Wells 56 pairs of authors For each author we use 50,000 words For each pair at least 50 different paragraphs from one author are inserted into the other author, one at a time. Tests are run using different segment sizes: »100 words »500 words »1000 words

66
Authorship Anomalies - Top 5 Ranking

67
Testing whether opinion can be detected in a factual story Opinion text is editorials from 4 newspapers totalling 28,200 words »Guardian »New Statesman »New York Times »Daily Telegraph Factual text is randomly chosen from the Gigaword and consists of 4 different 78,000 word segments one each from one of the 4 news wire services: »Agence France Press English Service »Associated Press Worldstream English Service »The New York Times Newswire Service »The Xinhua News Agency English Service Each opinion text paragraph is inserted into each news wire service one at a time for at least 28 insertions on each newswire Tests are run using different paragraph sizes Fact versus Opinion Tests

68
Opinion Anomalies - Top 5 Ranking

69
Very different genre from newswire. The writing is much more procedural (e.g. instructions to build telephone phreaking devices) and also very informal (e.g. ``When the fuse contacts the balloon, watch out!!!'') Randomly insert one segment from the Anarchist Cookbook and attempt to identify outliers –This is repeated 200 times for each segment size (100, 500, and 1,000 words) News versus Anarchist Cookbook
 and also very informal (e.g. ``When the fuse contacts the balloon, watch out!!! ) Randomly insert one segment from the Anarchist Cookbook and attempt to identify outliers –This is repeated 200 times for each segment size (100, 500, and 1,000 words) News versus Anarchist Cookbook.")
70
Anarchist Cookbook Anomalies - Top 5 Ranking

71
35 thousand words of Chinese news articles were hand picked (Wei Liu) and translated into English using Google’s Chinese to English translation engine Similar genre to English newswire but translations are far from perfect and so the language use is very odd Test collections are created for each segment size as before News versus Chinese MT
 and translated into English using Google’s Chinese to English translation engine Similar genre to English newswire but translations are far from perfect and so the language use is very odd Test collections are created for each segment size as before News versus Chinese MT")
72
Chinese MT Anomalies - Top 5 Ranking

73
Results Comp Distance anomaly detection produced best overall results, closely followed by SDE dist. City block distance measure always produced good rankings (with all methods)
.")
74
Conclusions Variations in text can be viewed as a type of anomaly or outlier and can be successfully detected using automatic unsupervised techniques Stylistic features and distributions of the rarity of words are a good choices for characterizing text and detecting a broad range of anomalies. Procedure that measures a piece of texts distance from its textual complement performs best Accuracy for anomaly detection improves considerably as we increase the length of our segments.

Similar presentations















 Objectives: Track I (duration 2 years) Specification and creation of large word lists and lexica suited for flexible.>")



>")
 of the words in.>")


