Download presentation
Presentation is loading. Please wait.

1
Universal Scaling of Semantic Information Revealed from IB word clusters or Human language as optimal biological adaptation Naftali Tishby School of Computer Science & Engineering & Interdisciplinary Center for Neural Computation The Hebrew University, Jerusalem, Israel http://www.cs.huji.ac.il/~tishby Workshop on Machine Learning in Natural Language Processing CRI, Haifa University December 2006

2
Outline: u Language – a window into our cognitive processing l What can we learn from word statistics? l How can we quantify it? l Is there a “correct level” of description ? u Information Bottleneck (IB) and the representation of relevance l Finding Approximate sufficient statistics u Words, documents and meaning… u Trading complexity and accuracy l Scaling of semantic information u Possible models: small world properties
 and the representation of relevance l Finding Approximate sufficient statistics u Words, documents and meaning… u Trading complexity and accuracy l Scaling of semantic information u Possible models: small world properties.")
3
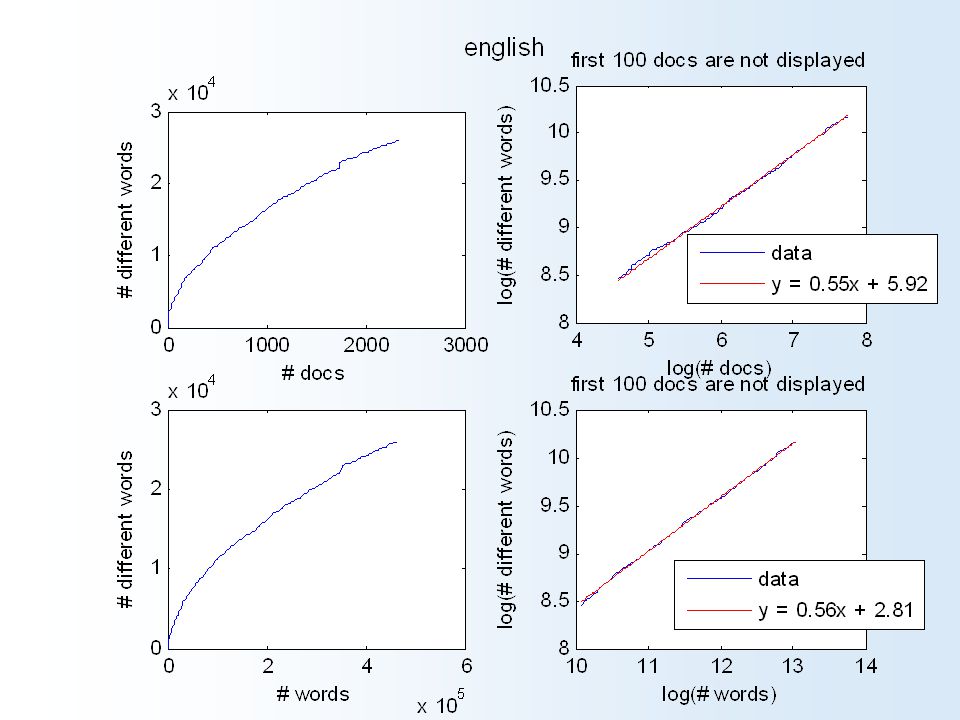
012345 6 x 10 4 0 4000 6000 Number of observed words What are words? acquired persistent neural activity associated with perception and cognitive functions appear in every language in a regular power-law sub-linear rate Number of different words Log number of words Log number of different words 8.599.51010.511 7.5 8 8.5 9 9.5 data y = 0.64x + 2.07 10000 8000 2000

7
Rank – Frequency of words Words exhibit “scale-free” statistics- Zipf’s law

8
How are words/languages generated? Basic observations: Basic observations: serve for communication and representation serve for communication and representation adapt to variable world statistics adapt to variable world statistics collective (social) entity collective (social) entity acquired continuously (individually and collectively) acquired continuously (individually and collectively)Competition between comm. efficiency and adaptability / learnability
 entity collective (social) entity acquired continuously (individually and collectively) acquired continuously (individually and collectively)Competition between comm. efficiency and adaptability / learnability.")
9
Complexity – Accuracy Tradeoff Complexity Accuracy Possible Representations

10
Complexity Accuracy Possible Models/representations Limited data BoundedComputation Complexity – Accuracy Tradeoff

11
Can we quantify it…? When there is a (relevant) prediction or distortion measure Accuracy good predictions (low distortion/error) Complexity long minimal description (optimal codes) A general tradeoff between distortion and compression: Information Theory
 prediction or distortion measure Accuracy good predictions (low distortion/error) Complexity long minimal description (optimal codes) A general tradeoff between distortion and compression: Information Theory.")
12
What can we learn from word co-occurrence...?

13
We need to index the max number of non-overlapping green blobs inside the blue blob: (mutual information!) Representation and Mutual Information
 Representation and Mutual Information")
14
IB: an Information Theoretic Principle For extracting Relevant structure The minimal representation of X that keeps as much information about another variable, Y, as possible. Generalizes the classical notion of “sufficient statistics”.

15
Self Consistent Equations The Self Consistent Equations Marginal: Markov condition: Bayes’ rule:

16
effective distortion The emerged effective distortion measure: Regular if is absolutely continuous w.r.t. Small if predicts y as well as x:

17
Information Bottleneck The Information Bottleneck Algorithm “free energy”

18
The emergent effective distortion measure: Generalized BA-algorithm

19
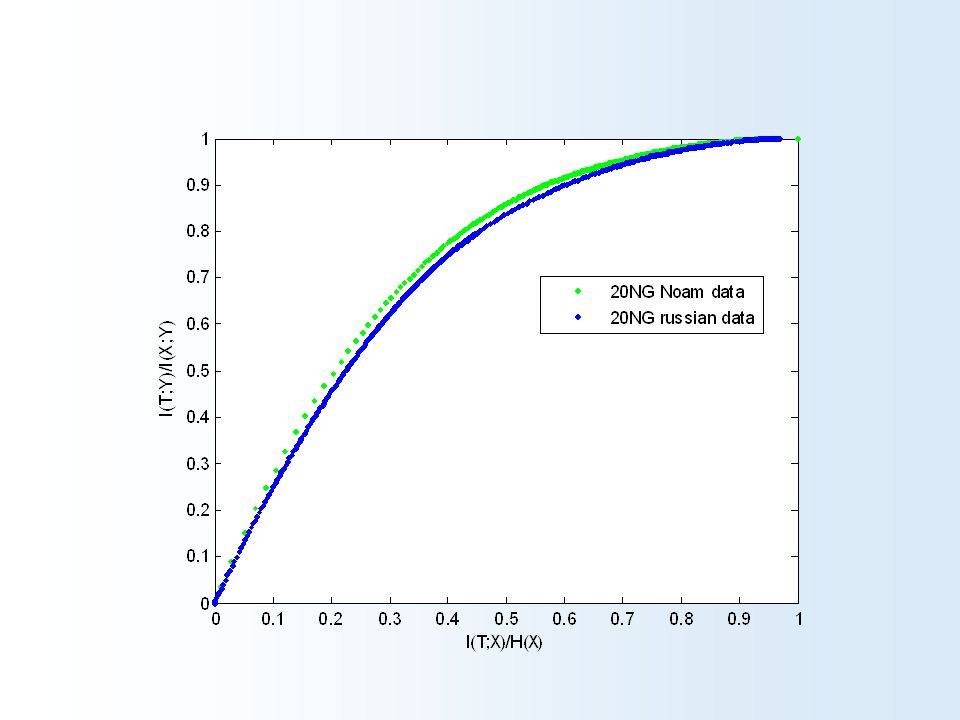
Can be calculated analytically for Markov chains, Gaussian processes, etc., and numerically in general. IYIY IXIX I C1 Y (I C1 X ) I C2 Y (I C2 X ) I C3 Y (I C3 X ) The limit is always the convex envelope of increasing complexity Information Curves
 I C2 Y (I C2 X ) I C3 Y (I C3 X ) The limit is always the convex envelope of increasing complexity Information Curves.")
20
Naftali Tishby ACAI-99 20 Words and topics again...

21
Simple Example

22
A new compact representation The document clusters preserve the relevant information between the documents and words

23
Analyzing Co-Occurrence Tables Topics Words Topics-Words counts matrix

24
Words The exact same counts matrix after permutation Topics

25
Word clusters Topic Clusters The eord clusters provide a compact representation that preserve the information about the topics

26
Quantified by Mutual Information The distinctions inside each cluster Are less relevant for predicting the class Words Irrelevant distinctions

27
Symmetric IB through Deterministic Annealing alt.atheism rec.autos rec.motorcycles rec.sport.* sci.med sci.space soc.religion.christian talk.politics.* comp.* misc.forsale sci.crypt sci.electronics car turkish game team jesus gun hockey … x file image encryption window dos mac … Newsgroup Word P(T C,T W )
")
28
Symmetric IB through Deterministic Annealing Newsgroup word comp.graphics comp.os.ms-windows.misc comp.windows.x comp.sys.ibm.pc.hardware comp.sys.mac.hardware misc.forsale sci.crypt sci.electronics windows image window jpeg graphics … encryption db ide escrow monitor … P(T C,T W )
")
29
Symmetric IB through Deterministic Annealing Newsgroup word P(T C,T W )
")
30
Symmetric IB through Deterministic Annealing Newsgroup word alt.atheism rec.sport.baseball rec.sport.hockey soc.religion.christian talk.politics.mideast talk.religion.misc rec.autos rec.motorcycles sci.med sci.space talk.politics.guns talk.politics.misc armenian turkish jesus hockey israeli armenians … car q gun bike fbi health … P(T C,T W )
")
31
Symmetric IB through Deterministic Annealing Newsgroup Word P(T C,T W )
")
32
Symmetric IB through Deterministic Annealing Newsgroup Word P(T C,T W )
")
33
Symmetric IB through Deterministic Annealing Newsgroup Word atheists christianity jesus bible sin faith … alt.atheism soc.religion.christian talk.religion.misc P(T C,T W )
")
34
We observe Semantic Scaling

36
Simplified Chinese 2.09 Traditional Chinese 1.73 Dutch 2.3 French 2.22 Hebrew 1.63 Italian 2.35 Japanese 1.42 Portuguese 2.9 Spanish 1.89

37
-4.5-4-3.5-3-2.5-2-1.5-0.50 -8 -7 -6 -5 -4 -3 -2 0 log(1-I(T;X)/H(X)) log(1-I(T;Y)/I(X;Y)) Chinese Simplified Chinese Traditional Dutch French Hebrew Italian Japanese Korean Porgutuese Spanish English 20NG Jose English UTF English Reuters English 20NG Noam
/H(X)) log(1-I(T;Y)/I(X;Y)) Chinese Simplified Chinese Traditional Dutch French Hebrew Italian Japanese Korean Porgutuese Spanish English 20NG Jose English UTF English Reuters English 20NG Noam")
38
-4.5-4-3.5-3-2.5-2-1.5-0.5 -14 -12 -10 -8 -6 -4 -2 log(1-I(T;X)/H(X)) log(1-I(T;Y)/I(X;Y)) Random selection of 200 words
/H(X)) log(1-I(T;Y)/I(X;Y)) Random selection of 200 words")
39
Can we understand it? Any subset of the language has the same exponent!

40
But what does it tell about Language? “Efficiency of the words”: Log-ratio of added Word Entropy that is transferred to Meaningful Information Language appears to have constant word efficiency! ~ 2

41
Possible Explanations? Power laws are too common to mean anything… Zipf’s law and similar… “never trust linear log-log plots…” Zipf’s law and similar… “never trust linear log-log plots…” It’s a property of my Analysis, not of Language How do I know that its not all in the way we cluster the words? How do I know that its not all in the way we cluster the words? Words are generated at a Constant level of Ambiguity: words are generated at a constant rate, depending only on the concept (occurred) ambiguity in usage irrespective of vocabulary size or domain words are generated at a constant rate, depending only on the concept (occurred) ambiguity in usage irrespective of vocabulary size or domain Small world (scale free) properties of word acquisition…
 ambiguity in usage irrespective of vocabulary size or domain words are generated at a constant rate, depending only on the concept (occurred) ambiguity in usage irrespective of vocabulary size or domain Small world (scale free) properties of word acquisition….")
42
Many Thanks to… u Bill u Bill Bialek u Fernando u Fernando Pereira u Noam u Noam Slonim u Dmitry u Dmitry Davidov u Amir u Amir Navot u Josemine u Josemine Magdalen u Banter u Banter Co. (z”l)
.")
Similar presentations








 Computer Science cpsc502, Lecture 15 Nov, 1, 2011 Slide credit: C. Conati, S.>")












