Download presentation
Presentation is loading. Please wait.

1
A Strategy for the Future of High Performance Computing? Advanced Computing Laboratory Los Alamos National Laboratory Pete Beckman

2
2 Advanced Computing Laboratory Los Alamos National Laboratory Observations: The US Supercomputing Industry l All US high-performance vendors are building clusters of SMPs (with the exception of Tera) l Each company, IBM, SGI, Compaq, HP, and SUN has a different version of Unix l Each company attempts to scale system software designed for database, internet, technical and servers l This fractured market forces 5 different parallel file systems, fast message implementations, etc l Supercomputer companies tend to go out of business
 l Each company, IBM, SGI, Compaq, HP, and SUN has a different version of Unix l Each company attempts to scale system software designed for database, internet, technical and servers l This fractured market forces 5 different parallel file systems, fast message implementations, etc l Supercomputer companies tend to go out of business")
3
Pete Beckman3 Advanced Computing Laboratory Los Alamos National Laboratory New Limitations People used to say: “The number of Tflops available is limited only by the amount of money you wish to spend” The Reality: We are at a point where our ability to build machines from components exceeds our ability to admin, program and run them But we do it anyway. Many large clusters are being installed...

4
Pete Beckman4 Advanced Computing Laboratory Los Alamos National Laboratory Scalable System Software is currently the weak link Software for Tflop clusters of SMPs is hard l System administration, configuration, booting, management, & monitoring l Scalable smart NIC messaging (zero copy) l Cluster/Global/Parallel File System l Job queuing and running l I/O (scratch, prefetch, NASD) l Fault tolerance and on-the-fly reconfiguration
 l Cluster/Global/Parallel File System l Job queuing and running l I/O (scratch, prefetch, NASD) l Fault tolerance and on-the-fly reconfiguration")
5
Pete Beckman5 Advanced Computing Laboratory Los Alamos National Laboratory Why use Linux for clusters of SMPs, and as a basis for system software research? l The OS for scalable clusters needs more research l Open Source! (it’s more then just geek chic) n No lawyers, no NDAs, no worries mate! n Visible code improves faster n The whole environment, or just the mods can be distributed n Scientific collaboration is just an URL away... l Small, well designed, stable, mature, kernel n ~240K lines of code without device drivers /proc filesystem and dynamically loadable modules n The OS is extendable, optimizable, tunable Linux is a lot of fun (Shagadelic, Baby!) Did I mention no lawyers?
 n No lawyers, no NDAs, no worries mate. n Visible code improves faster n The whole environment, or just the mods can be distributed n Scientific collaboration is just an URL away... l Small, well designed, stable, mature, kernel n ~240K lines of code without device drivers /proc filesystem and dynamically loadable modules n The OS is extendable, optimizable, tunable Linux is a lot of fun (Shagadelic, Baby!) Did I mention no lawyers .")
6
Pete Beckman6 Advanced Computing Laboratory Los Alamos National Laboratory Isn’t Open Source hype? Do you really need it? A very quick example Supermon and Superview: High Performance Cluster Monitoring Tools Ron Minnich, Karen Reid, Matt Sottile

7
Pete Beckman7 Advanced Computing Laboratory Los Alamos National Laboratory The problem: get really fast stats from a very large cluster l Monitor hundreds of nodes at rates up to 100 Hz l Monitor at 10Hz without significant impact on the application l Monitor hardware performance counters l Collect a wide range of kernel information (disk blocks, memory, interrupts, etc)
")
8
Pete Beckman8 Advanced Computing Laboratory Los Alamos National Laboratory Solution l Modify the kernel so all the parameters can be grabbed without going though /proc l Tightly coupled clusters can get real- time monitoring stats. l This is not of general use to the desktop, and web server markets l Stats for 100 nodes takes about 20 ms

9
Pete Beckman9 Advanced Computing Laboratory Los Alamos National Laboratory Superview: the Java tool for Supermon

10
Pete Beckman10 Advanced Computing Laboratory Los Alamos National Laboratory Where should we concentrate our efforts? Some areas for improvement…. Scalable Linux System Software

11
Pete Beckman11 Advanced Computing Laboratory Los Alamos National Laboratory Software: The hard part Linux environments (page 1) l Compilers n F90 (PGI, Absoft, Compaq) n F77 (GNU, PGI, Absoft, Compaq, Fujitsu) n HPF (PGI, Compaq?) n C/C++ (PGI, KAI, GNU, Compaq, Fujitsu) n OpenMP (PGI) n Metrowerks Code Warrior for C, C++, (Fortran?) l Debuggers n Totalview… maybe, real soon now, almost? n gdb, DDD, etc.

12
Pete Beckman12 Advanced Computing Laboratory Los Alamos National Laboratory Software: The hard part Linux environments (page 2) l Message Passing n MPICH, PVM, MPI MSTI, Nexus n OS Bypass: –ST, FM, AM, PM, GM, VIA, Portals, etc –Fast Interconnects: Myrinet, GigE, HiPPI, SCI l Shared Memory Programming n Pthreads, Tulip-Threads, etc. l Parallel Performance Tools n TAU, Vampir, PGI PGProf, Jumpshot, etc

13
Pete Beckman13 Advanced Computing Laboratory Los Alamos National Laboratory Software: The hard part Linux environments (page 3) l File Systems & I/O n e2fs (native), NFS n PVFS, Coda, GFS n MPI-IO, ROMIO l Archival Storage n HPSS & ADSM clients l Job Control n LSF, PBS, Maui
 l File Systems & I/O n e2fs (native), NFS n PVFS, Coda, GFS n MPI-IO, ROMIO l Archival Storage n HPSS & ADSM clients l Job Control n LSF, PBS, Maui")
14
Pete Beckman14 Advanced Computing Laboratory Los Alamos National Laboratory Software: The hard part Linux environments (page 4) l Libraries and Frameworks n BLAS, OVERTURE, POOMA, Atlas n Alpha math libraries (Compaq) l System Administration n Building and booting tools n Cfengine n Monitoring and management tools n Configuration database n SGI Project Accounting
 l Libraries and Frameworks n BLAS, OVERTURE, POOMA, Atlas n Alpha math libraries (Compaq) l System Administration n Building and booting tools n Cfengine n Monitoring and management tools n Configuration database n SGI Project Accounting")
15
Pete Beckman15 Advanced Computing Laboratory Los Alamos National Laboratory Software for Linux clusters A report card (current status) Compilers Parallel debuggers Message passing Shared memory prog. Parallel performance tools File Systems Archival Storage Job Control Math Libraries ………………………………...………..A …………………………..……...I ………………………….….…..A- ……….…………..……..A …………...………..C+ ………………….………...………..D …………………………….……..C ………………………………...……..B- ……………………………………..B

16
Pete Beckman16 Advanced Computing Laboratory Los Alamos National Laboratory Summary of the most important areas l First Priority n Cluster management, administration, images, monitoring, etc n Cluster/parallel/global file systems n Continued work on scalable messaging n Faster, more scalable SMP n Virtual memory optimized for HPC n TCP/IP improvements Wish List NIC boot, BIOS NVRAM, Serial console OS bypass standards in the kernel Tightly-coupled scheduling, accounting Newest Drivers

17
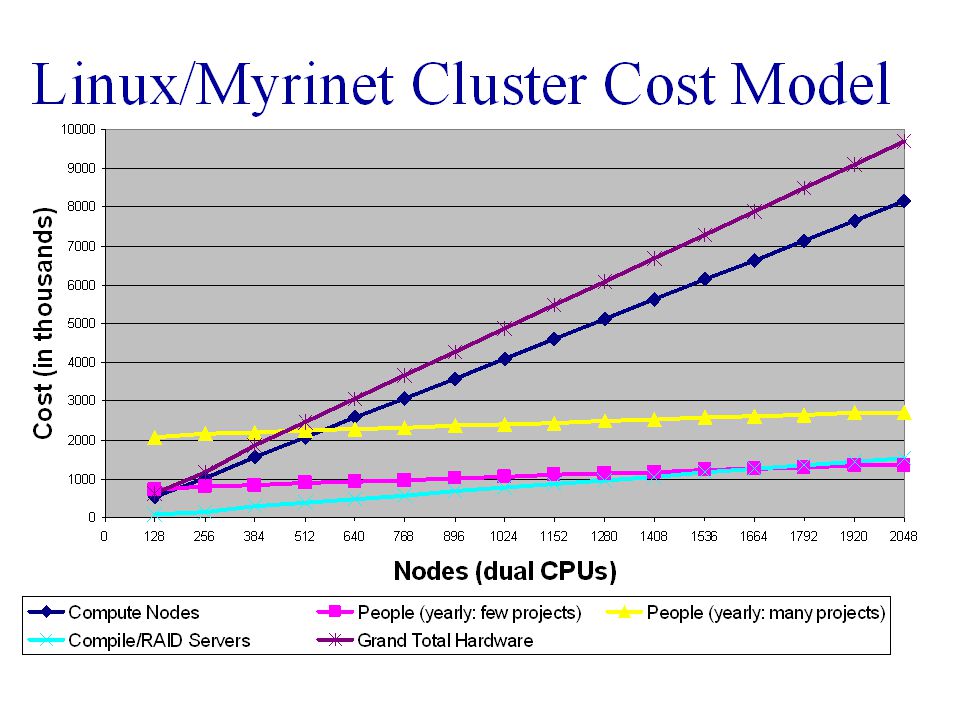
Pete Beckman17 Advanced Computing Laboratory Los Alamos National Laboratory Honest cluster costs: publish the numbers l How many sysadmins and programmers are we required for support? l What are the service and replacement costs? l How much was hardware integration? l How many users can you support and at what levels? l How much was the hardware?

18
Pete Beckman18 Advanced Computing Laboratory Los Alamos National Laboratory Compute Nodes Gigabit Ethernet Control Node Control Node Gigabit Multistage Interconnection Fabric Network Attached Secure Disks Unit Tera-Scale SMP Cluster Architecture

21
Pete Beckman21 Advanced Computing Laboratory Los Alamos National Laboratory Let someone else put it together l Compaq l Dell l Penguin Computing l Alta Tech l VA Linux l DCG l Paralogic l Microway Ask about support

22
Pete Beckman22 Advanced Computing Laboratory Los Alamos National Laboratory Cluster Benchmarking Lies, Damn Lies, and the Top500 l Make MPI zero-byte messaging a special case (improves latency numbers) l Convert multiply flops to addition, recount flops l Hire a Linpack consultant to help you achieve “the number” the vendor promised l “We unloaded the trucks, and 24hrs later, we calculated the size of the galaxy in acres.” l For $15K and 3 rolls of duct tape I built a supercomputer in my cubicle…. Vendor Published Linpack, Latency, and Bandwidth numbers are worthless

23
Pete Beckman23 Advanced Computing Laboratory Los Alamos National Laboratory Plug-in Framework for Cluster Benchmarks

24
Pete Beckman24 Advanced Computing Laboratory Los Alamos National Laboratory MPI Message Matching

25
Pete Beckman25 Advanced Computing Laboratory Los Alamos National Laboratory

26
Pete Beckman26 Advanced Computing Laboratory Los Alamos National Laboratory

27
Pete Beckman27 Advanced Computing Laboratory Los Alamos National Laboratory Conclusions l Lots of Linux clusters will be at SC99 l The Big 5 vendors do not have the critical mass to develop the system software for multi-teraflop clusters l The HPC community (labs, vendors, universities, etc.) needs to work together l The hardware consolidation is nearly over, the software consolidation is on its way l A Linux-based “commodity” Open Source strategy could provide a mechanism for: n open vendor collaboration n academic and laboratory participation n one Open Source software environment
 needs to work together l The hardware consolidation is nearly over, the software consolidation is on its way l A Linux-based commodity Open Source strategy could provide a mechanism for: n open vendor collaboration n academic and laboratory participation n one Open Source software environment")
28
Pete Beckman28 Advanced Computing Laboratory Los Alamos National Laboratory News and Announcements: l The next Extreme Linux conference will be in Williamsburg in October. The call for papers will be out soon, start preparing those technical papers… l There will be several cluster tutorials at SC99. Remy Evard, Bill Saphir, and Pete Beckman will be running one focused on system administration and user environment for large clusters.

Similar presentations










>")
 –35 at top500.org –Linpack Benchmark 825.>")



 Ron Brightwell Sandia National Labs Scalable Computing Systems Department>")




