Download presentation
Presentation is loading. Please wait.

2
. Please start your Daily Portfolio

3
Introduction to Statistics for the Social Sciences SBS200, COMM200, GEOG200, PA200, POL200, or SOC200 Lecture Section 001, Summer Session II, 2013 9:00 - 11:20am Monday - Friday Room 312 Social Sciences (Monday – Thursdays) Room 480 Marshall Building (Fridays) http://www.youtube.com/watch?v=oSQJP40PcGI
 Room 480 Marshall Building (Fridays) v=oSQJP40PcGI")
4
My last name starts with a letter somewhere between A. A – D B. E – L C. M – R D. S – Z Please click in Please double check All cell phones other electronic devices are turned off and stowed away

5
Homework due – Wednesday On class website: Please print and complete homework worksheet #13 Multiple Regression

6
Schedule of readings Before Friday Please read chapters 10 – 14 Please read Chapters 17, and 18 in Plous Chapter 17: Social Influences Chapter 18: Group Judgments and Decisions Study Guide is online

7
Next couple of lectures 7/30/13 Use this as your study guide Simple and Multiple Regression Using correlation for predictions r versus r 2 Regression uses the predictor variable (independent) to make predictions about the predicted variable (dependent) Coefficient of correlation is name for r Coefficient of determination is name for r 2 (remember it is always positive – no direction info) Standard error of the estimate is our measure of the variability of the dots around the regression line (average deviation of each data point from the regression line – like standard deviation) Coefficient of regression will b for each variable (like slope)
 to make predictions about the predicted variable (dependent) Coefficient of correlation is name for r Coefficient of determination is name for r 2 (remember it is always positive – no direction info) Standard error of the estimate is our measure of the variability of the dots around the regression line (average deviation of each data point from the regression line – like standard deviation) Coefficient of regression will b for each variable (like slope)")
8
Other Problems The expected frequeny of teeth brushing for having one cavity is Frequency of teeth brushing= 5.5 + (-.91) Cavities If Cavities = 3, what is the prediction for Frequency of teeth brushing? Frequency of teeth brushing= 5.5 + (-.91) Cavities Frequency of teeth brushing= 5.5 + (-.91) (3) Frequency of teeth brushing= 5.5 + (-2.73) = 2.77 (3.0, 2.77) Prediction line Y = a + b 1 X 1 Y-intercept Slope If number of cavities = 3 Frequency of Teeth brushing will be 2.77
 Cavities Frequency of teeth brushing= (-.91) (3) Frequency of teeth brushing= (-2.73) = 2.77 (3.0, 2.77) Prediction line Y = a + b 1 X 1 Y-intercept Slope If number of cavities = 3 Frequency of Teeth brushing will be")
9
r = - 0.85 b 1 = - 0.91 (slope) b 0 = 5.5 (intercept) Draw a regression line and regression equation Prediction line Y = b 1 X 1 + b 0 Y = (-.91)X 1 + 5.5
 b 0 = 5.5 (intercept) Draw a regression line and regression equation Prediction line Y = b 1 X 1 + b 0 Y = (-.91)X")
10
Correlation - lets predict how often they brushed their teeth 0 1 2 3 4 5 Number of cavities Number of times per day teeth are brushed 1 2 3 4 5 0 Find prediction line Y = b 1 X + b 0 Y = (-0.91) X + 5.5 Y = (-0.91) 1 + 5.5 = 4.59 (plot 1,4.59) Y = (-0.91) 5 + 5.5 = 0.95 (plot 5,0.95) Plot line - predict Y from X - Pick an X - Pick another X Lets try X of 1 Lets try X of 5
 X Y = (-0.91) = 4.59 (plot 1,4.59) Y = (-0.91) = 0.95 (plot 5,0.95) Plot line - predict Y from X - Pick an X - Pick another X Lets try X of 1 Lets try X of 5")
11
r = -0.85 b 1 = - 0.91 b 0 = 5.5 Y = b 1 X + b 0 Y = (-0.91) 3 + 5.5 = 2.77 Y = (-0.91) 1 + 5.5 = 4.59 Y = (-0.91) 2 + 5.5 = 3.68 Y = (-0.91) 3 + 5.5 = 2.77 Y = (-0.91) 5 + 5.5 =.95 Y = (-0.91) X + 5.5 X Y. 1 5 3 4 2 3 3 2 5 1 0 1 2 3 4 5 Number of cavities Number of times per day teeth are brushed 1 2 3 4 5 0

12
Correlation - Evaluating the prediction line Does the prediction line perfectly predict the Ys from the Xs? No, lets see How much error is there? Exactly? Prediction line Y = b 1 X 1 + b 0 Y = (-.91)X 1 + 5.5 0 1 2 3 4 5 Number of cavities Number of times per day teeth are brushed 1 2 3 4 5 0 Residuals The green lines show how much error there is in our prediction line…how much we are wrong in our predictions
X Number of cavities Number of times per day teeth are brushed Residuals The green lines show how much error there is in our prediction line…how much we are wrong in our predictions.")
13
Correlation Perfect correlation = +1.00 or -1.00 The more closely the dots approximate a straight line, (the less spread out they are) the stronger the relationship is. One variable perfectly predicts the other No variability in the scatterplot The dots approximate a straight line Any Residuals?

14
0 1 2 3 4 5 Number of cavities 5 Number of times per day teeth are brushed 1 2 3 4 0 Shorter green lines suggest better prediction – smaller error Longer green lines suggest worse prediction – larger error Why are green lines vertical? Remember, we are predicting the variable on the Y axis So, error would be how we are wrong about Y (vertical) How well does the prediction line predict the Ys from the Xs? Residuals A note about curvilinear relationships and patterns of the residuals
 How well does the prediction line predict the Ys from the Xs. Residuals A note about curvilinear relationships and patterns of the residuals.")
15
0 1 2 3 4 5 Number of cavities Number of times per day teeth are brushed 1 2 3 4 5 0 Slope doesnt give variability info Intercept doesnt give variability info Correlation r does give variability info How well does the prediction line predict the Ys from the Xs? Residuals Residuals do give variability info

16
What if we want to know the average deviation score? Finding the standard error of the estimate (line) Standard error of the estimate: a measure of the average amount of predictive error the average amount that Y scores differ from Y scores a mean of the lengths of the green lines Standard error of the estimate (line) Sound familiar??
 Standard error of the estimate: a measure of the average amount of predictive error the average amount that Y scores differ from Y scores a mean of the lengths of the green lines Standard error of the estimate (line) Sound familiar .")
17
Correlation - lets predict how often they brushed their teeth 0 1 2 3 4 5 Number of cavities Number of times per day teeth are brushed 1 2 3 4 5 0 Find prediction line Y = b 1 X + b 0 Y = (-0.91) X + 5.5 Y = (-0.91) 1 + 5.5 = 4.59 (plot 1,4.59) Y = (-0.91) 5 + 5.5 = 0.95 (plot 5,0.95) Plot line - predict Y from X - Pick an X - Pick another X Lets try X of 1 Lets try X of 5
 X Y = (-0.91) = 4.59 (plot 1,4.59) Y = (-0.91) = 0.95 (plot 5,0.95) Plot line - predict Y from X - Pick an X - Pick another X Lets try X of 1 Lets try X of 5")
18
r = -0.85 b 1 = - 0.91 b 0 = 5.5 Y = b 1 X + b 0 Y = (-0.91) 3 + 5.5 = 2.77 Y = (-0.91) 1 + 5.5 = 4.59 Y = (-0.91) 2 + 5.5 = 3.68 Y = (-0.91) 4 + 5.5 = 1.86 Y = (-0.91) 5 + 5.5 =.95 Y = (-0.91) X + 5.5 X Y Y Y-Y. 1 5 4.59 0.41 3 4 2.77 1.23 2 3 3.68 -0.68 3 2 2.77 -0.77 5 1 0.95 0.05 0 1 2 3 4 5 Number of cavities Number of times per day teeth are brushed 1 2 3 4 5 0 These are our predicted values for each X score A note on Adding up deviations.41 1.23 -.77 -.68 0.05

19
r = -0.85 b 1 = - 0.91 b 0 = 5.5 Y = b 1 X + b 0 Y = (-0.91) 3 + 5.5 = 2.77 Y = (-0.91) 1 + 5.5 = 4.59 Y = (-0.91) 2 + 5.5 = 3.68 Y = (-0.91) 4 + 5.5 = 1.86 Y = (-0.91) 5 + 5.5 =.95 Y = (-0.91) X + 5.5 X Y Y Y-Y. (Y-Y) 2 1 5 4.59 0.41 0.168 3 4 2.77 1.231.513 2 3 3.68 -0.680.462 3 2 2.77 -0.770.593 5 1 0.95 0.05.0025 0 1 2 3 4 5 Number of cavities Number of times per day teeth are brushed 1 2 3 4 5 0.41 1.23 -.77 -.68 0.05 2.739 3 0.95 This is like our average (or standard) size of our residual Standard Error of the Estimate
 Number of cavities Number of times per day teeth are brushed This is like our average (or standard) size of our residual Standard Error of the Estimate.")
20
Is the regression line better than just guessing the mean of the Y variable? How much does the information about the relationship actually help? 0 1 2 3 4 5 Number of cavities Number of times per day teeth are brushed 1 2 3 4 5 0 5 # of times teeth are brushed 1 2 3 4 0 0 1 2 3 4 5 Number of cavities Which minimizes error better? How much better does the regression line predict the observed results? r2r2 Wow!

21
What is r 2 ? r 2 = The proportion of the total variance in one variable that is predictable by its relationship with the other variable If mothers and daughters heights are correlated with an r =.8, then what amount (proportion or percentage) of variance of mothers height is accounted for by daughters height? Examples.64 because (.8) 2 =.64
 of variance of mothers height is accounted for by daughters height. Examples.64 because (.8) 2 =.64.")
22
What is r 2 ? r 2 = The proportion of the total variance in one variable that is predictable for its relationship with the other variable If mothers and daughters heights are correlated with an r =.8, then what proportion of variance of mothers height is not accounted for by daughters height? Examples.36 because (1.0 -.64) =.36 or 36% because 100% - 64% = 36%
 =.36 or 36% because 100% - 64% = 36%.")
23
What is r 2 ? r 2 = The proportion of the total variance in one variable that is predictable for its relationship with the other variable If ice cream sales and temperature are correlated with an r =.5, then what amount (proportion or percentage) of variance of ice cream sales is accounted for by temperature? Examples.25 because (.5) 2 =.25
 of variance of ice cream sales is accounted for by temperature. Examples.25 because (.5) 2 =.25.")
24
What is r 2 ? r 2 = The proportion of the total variance in one variable that is predictable for its relationship with the other variable If ice cream sales and temperature are correlated with an r =.5, then what amount (proportion or percentage) of variance of ice cream sales is not accounted for by temperature? Examples.75 because (1.0 -.25) =.75 or 75% because 100% - 25% = 75%
 of variance of ice cream sales is not accounted for by temperature. Examples.75 because ( ) =.75 or 75% because 100% - 25% = 75%.")
25
regression equations Questions on homework?

27
the hours worked and weekly pay is a strong positive correlation. This correlation is significant, r(3) = 0.92; p < 0.05 The relationship between +0.92 positive strong up down 6.0857 55.286 y' = 6.0857x + 55.286 207.43 85.71.846231 or 84% 84% of the total variance of weekly pay is accounted for by hours worked For each additional hour worked, weekly pay will increase by $6.09
 = 0.92; p < 0.05 The relationship between positive strong up down y = x or 84% 84% of the total variance of weekly pay is accounted for by hours worked For each additional hour worked, weekly pay will increase by $6.09.")
28
400 380 360 340 320 300 4 8 5 6 7 Number of Operators Wait Time 280

29
-.73 The relationship between wait time and number of operators working is negative and strong. This correlation is not significant, r(3) = 0.73; n.s. negative strong number of operators increase, wait time decreases 458 -18.5 y' = -18.5x + 458 365 seconds 328 seconds.53695 or 54% The proportion of total variance of wait time accounted for by number of operators is 54%. For each additional operator added, wait time will decrease by 18.5 seconds Critical r = 0.878 No we do not reject the null
 = 0.73; n.s. negative strong number of operators increase, wait time decreases y = -18.5x seconds 328 seconds or 54% The proportion of total variance of wait time accounted for by number of operators is 54%. For each additional operator added, wait time will decrease by 18.5 seconds Critical r = No we do not reject the null.")
30
39 36 33 30 27 24 21 Median Income Percent of BAs 45 48 51 54 57 60 63 66

31
0.8875 The relationship between median income and percent of residents with BA degree is strong and positive. This correlation is significant, r(8) = 0.89; p < 0.05. positive strong median income goes up so does percent of residents who have a BA degree 3.1819 25% of residents 35% of residents.78766 or 78% The proportion of total variance of % of BAs accounted for by median income is 78%. For each additional $1 in income, percent of BAs increases by.0005 Percent of residents with a BA degree 10 8 0.0005 y' = 0.0005x + 3.1819 Critical r = 0.632 Yes we reject the null
 = 0.89; p < positive strong median income goes up so does percent of residents who have a BA degree % of residents 35% of residents or 78% The proportion of total variance of % of BAs accounted for by median income is 78%. For each additional $1 in income, percent of BAs increases by.0005 Percent of residents with a BA degree y = x Critical r = Yes we reject the null.")
32
30 27 24 21 18 15 12 Median Income Crime Rate 45 48 51 54 57 60 63 66

33
-0.6293 The relationship between crime rate and median income is negative and moderate. This correlation is not significant, r(8) = -0.63; p < n.s. [0.6293 is not bigger than critical of 0.632]. negative moderate median income goes up, crime rate tends to go down 4662.5 2,417 thefts 1,418.5 thefts.396 or 40% The proportion of total variance of thefts accounted for by median income is 40%. For each additional $1 in income, thefts go down by.0499 Crime Rate 10 8 -0.0499 y' = -0.0499x + 4662.5 Critical r = 0.632 No we do not reject the null
 = -0.63; p < n.s. [ is not bigger than critical of 0.632]. negative moderate median income goes up, crime rate tends to go down ,417 thefts 1,418.5 thefts.396 or 40% The proportion of total variance of thefts accounted for by median income is 40%. For each additional $1 in income, thefts go down by.0499 Crime Rate y = x Critical r = No we do not reject the null.")
34
Example of Simple Regression The manager of copier company wants to determine whether there is a relationship between the number of sales calls made in a month and the number of copiers sold that month. The manager selects a random sample of 10 representatives and determines the number of sales calls each representative made last month and the number of copiers sold.

35
What are we predicting? Correlation: Independent and dependent variables When used for prediction we refer to the predicted variable as the dependent variable and the predictor variable as the independent variable Dependent Variable Independent Variable Soni Mark Tom Susan Jeff Carlos Who sold the most copiers? Who sold the fewest copiers?

36
Correlation Coefficient – Excel Example

37
0.759014 Interpret r = 0.759 Positive relationship between the number of sales calls and the number of copiers sold. Strong relationship Remember, we have not demonstrated cause and effect here, only that the two variablessales calls and copiers soldare related.

38
Correlation Coefficient – Excel Example 0.759014 Interpret r = 0.759 Does this correlation reach significance? n = 10, df = 8 alpha =.05 Observed r is larger than critical r (0.759 > 0.632) therefore we reject the null hypothesis. r (8) = 0.759; p < 0.05
 therefore we reject the null hypothesis. r (8) = 0.759; p <")
39
Coefficient of Determination – Excel Example 0.759014 Interpret r 2 = 0.576 (.759 2 =.576) we can say that 57.6 percent of the variation in the number of copiers sold is explained, or accounted for, by the variation in the number of sales calls. Remember, we lose the directionality of the relationship with the r 2

40
Find Regression Equation – Excel Example

42
Regression Equation - Example State the regression equation Y = a + bx Y = 18.9476 + 1.1842x Solve for some value of Y Y = 18.9476 + 1.1842 (20) Y = 42.63 If make this many calls If you probably sell this much What is the expected number of copiers sold by a representative who made 20 calls? Interpret the slope Y = 18.9476 + 1.1842x For each additional sales call made we sell 1.842 more copiers

43
Regression Equation - Example What is the expected number of copiers sold by a representative who made 40 calls? Solve for some value of Y Y = 18.9476 + 1.1842 (40) Y = 66.3156 If make this many calls If you probably sell this much
 Y = If make this many calls If you probably sell this much.")
44
An example for The Standard Error of Estimate The standard error of estimate measures the scatter, or dispersion, of the observed values around the line of regression A formula that can be used to compute the standard error: Standard error of the estimate (line)
")
45
Regression Analysis – Least Squares Principle When we calculate the regression line we try to: minimize distance between predicted Ys and actual (data) Y points (length of green lines) remember because of the negative and positive values cancelling each other out we have to square those distance (deviations) so we are trying to minimize the sum of squares of the vertical distances between the actual Y values and the predicted Y values
 Y points (length of green lines) remember because of the negative and positive values cancelling each other out we have to square those distance (deviations) so we are trying to minimize the sum of squares of the vertical distances between the actual Y values and the predicted Y values")
46
The Standard Error of Estimate Step 1: List all the Y data points

47
The Standard Error of Estimate Step 1: List all the Y data points Step 2: Find all the predicted Y data points

48
The Standard Error of Estimate Step 3: Find deviations Step 4: Square and add up deviations

49
Then simply plug in the numbers and solve for the standard error of the estimate Remember conceptually, this is like the average of the length of those green lines 784.211 10 - 2 = 9.901 =

50
Writing Assignment - 5 Questions 2. What is a residual? How would you find it? 1. What is regression used for? Include and example 3. What is Standard Error of the Estimate (How is it related to residuals?) 4. Give one fact about r 2 5. How is regression line like a mean?
 4. Give one fact about r 2 5. How is regression line like a mean .")
51
Writing Assignment - 5 Questions Regressions are used to take advantage of relationships between variables described in correlations. We choose a value on the independent variable (on x axis) to predict values for the dependent variable (on y axis). 1. What is regression used for? Include and example
 to predict values for the dependent variable (on y axis). 1. What is regression used for. Include and example.")
52
Writing Assignment - 5 Questions 2. What is a residual? How would you find it? Residuals are the difference between our predicted y (y) and the actual y data points. Once we choose a value on our independent variable and predict a value for our dependent variable, we look to see how close our prediction was. We are measuring how wrong we were, or the amount of error for that guess. Y – Y
 and the actual y data points. Once we choose a value on our independent variable and predict a value for our dependent variable, we look to see how close our prediction was. We are measuring how wrong we were, or the amount of error for that guess. Y – Y.")
53
Writing Assignment - 5 Questions 3. What is Standard Error of the Estimate (How is it related to residuals?) The average length of the residuals The average error of our guess The average length of the green lines The standard deviation of the regression line
 The average length of the residuals The average error of our guess The average length of the green lines The standard deviation of the regression line.")
54
Writing Assignment - 5 Questions 4. Give one fact about r 2 5. How is regression line like a mean?

55
Correlation - the prediction line Prediction line makes the relationship easier to see (even if specific observations - dots - are removed) identifies the center of the cluster of (paired) observations identifies the central tendency of the relationship (kind of like a mean) can be used for prediction should be drawn to provide a best fit for the data should be drawn to provide maximum predictive (explanatory) power for the data should be drawn to provide minimum predictive error - what is it good for? r2r2

56
Some useful terms Regression uses the predictor variable (independent) to make predictions about the predicted variable (dependent) Coefficient of correlation is name for r Coefficient of determination is name for r 2 (remember it is always positive – no direction info) Standard error of the estimate is our measure of the variability of the dots around the regression line (average deviation of each data point from the regression line – like standard deviation)
 to make predictions about the predicted variable (dependent) Coefficient of correlation is name for r Coefficient of determination is name for r 2 (remember it is always positive – no direction info) Standard error of the estimate is our measure of the variability of the dots around the regression line (average deviation of each data point from the regression line – like standard deviation)")
57
Correlation: Independent and dependent variables When used for prediction we refer to the predicted variable as the dependent variable and the predictor variable as the independent variable Dependent Variable Dependent Variable Independent Variable Independent Variable What are we predicting?

58
How many dependent variables? Multiple regression equations Prediction line Y = b 1 X 1 + b 0 Prediction line Y = b 1 X 1 + b 2 X 2 + b 0 Prediction line Y = b 1 X 1 + b 2 X 2 + b 3 X 3 + b 0 How many independent variables? 1 How many dependent variables? 1 How many independent variables? 3 We can predict amount of crime in a city from the number of bathrooms in city the amount spent on education in city the amount spent on after-school programs We can predict amount of crime in a city from the number of bathrooms in city the amount spent on education in city We can predict amount of crime in a city from the number of bathrooms in city

59
Multiple regression Used to describe the relationship between several independent variables and a dependent variable. Prediction line Y = b 1 X 1 + b 2 X 2 + b 3 X 3 + b 0 Can we predict amount of crime in a city from the number of bathrooms and the amount of spent on education and on after-school programs? X 1 X 2 and X 3 are the independent variables. Y is the dependent variable (amount of crime) b 0 is the Y-intercept b 1 is the net change in Y for each unit change in X 1 holding X 2 and X 3 constant. It is called a regression coefficient.
 b 0 is the Y-intercept b 1 is the net change in Y for each unit change in X 1 holding X 2 and X 3 constant. It is called a regression coefficient..")
60
Multiple regression will use multiple independent variables to predict the single dependent variable Expenses per year Yearly Income If you spend this much You probably make this much The predicted variable goes on the Y axis and is called the dependent variable. The predictor variable goes on the X axis and is called the independent variable Dependent Variable (Predicted) Independent Variable 1 (Predictor) Independent Variable 2 (Predictor) If you spend this much If you save this much You probably make this much
 Independent Variable 1 (Predictor) Independent Variable 2 (Predictor) If you spend this much If you save this much You probably make this much.")
61
14-60 Regression Plane for a 2-Independent Variable Linear Regression Equation

62
Multiple regression equations Can use variables to predict behavior of stock market probability of accident amount of pollution in a particular well quality of a wine for a particular year which candidates will make best workers

63
14-62 Can we predict heating cost? Three variables are thought to relate to the heating costs: (1) the mean daily outside temperature, (2) the number of inches of insulation in the attic, and (3) the age in years of the furnace. To investigate, Salisbury's research department selected a random sample of 20 recently sold homes. It determined the cost to heat each home last January Multiple Linear Regression - Example
 the mean daily outside temperature, (2) the number of inches of insulation in the attic, and (3) the age in years of the furnace. To investigate, Salisbury s research department selected a random sample of 20 recently sold homes. It determined the cost to heat each home last January Multiple Linear Regression - Example.")
65
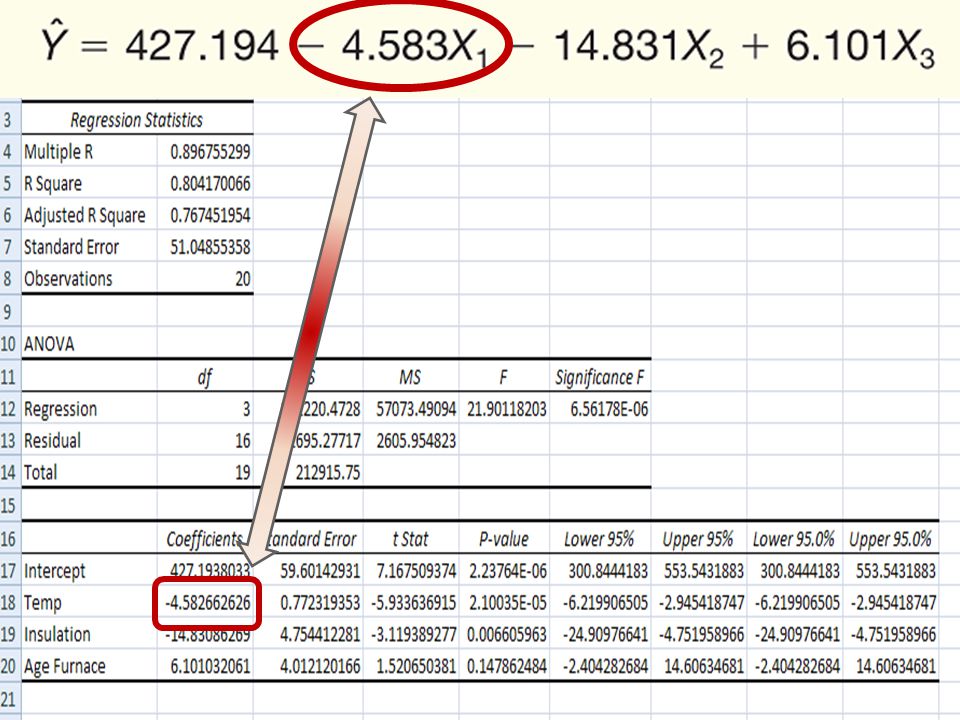
14-64 The Multiple Regression Equation – Interpreting the Regression Coefficients b 1 = The regression coefficient for mean outside temperature (X 1 ) is -4.583. The coefficient is negative and shows a negative correlation between heating cost and temperature. As the outside temperature increases, the cost to heat the home decreases. The numeric value of the regression coefficient provides more information. If we increase temperature by 1 degree and hold the other two independent variables constant, we can estimate a decrease of $4.583 in monthly heating cost.

66
14-65 The Multiple Regression Equation – Interpreting the Regression Coefficients b 2 = The regression coefficient for mean attic insulation (X 2 ) is -14.831. The coefficient is negative and shows a negative correlation between heating cost and insulation. The more insulation in the attic, the less the cost to heat the home. So the negative sign for this coefficient is logical. For each additional inch of insulation, we expect the cost to heat the home to decline $14.83 per month, regardless of the outside temperature or the age of the furnace.

67
14-66 The Multiple Regression Equation – Interpreting the Regression Coefficients b 3 = The regression coefficient for mean attic insulation (X 3 ) is 6.101 The coefficient is positive and shows a negative correlation between heating cost and insulation. As the age of the furnace goes up, the cost to heat the home increases. Specifically, for each additional year older the furnace is, we expect the cost to increase $6.10 per month.

68
Applying the Model for Estimation What is the estimated heating cost for a home if: the mean outside temperature is 30 degrees, there are 5 inches of insulation in the attic, and the furnace is 10 years old?

Similar presentations



















 – The regularly scheduled time Tuesday (12/9/14) – The optional.>")









