Download presentation
Presentation is loading. Please wait.

1
FREQUENCY TABLES, BAR GRAPHS, AND HISTOGRAMS
Handout #5

2
“Results” of Student Survey
ID V1 V2 V3 V4 V5 V6 V7 V8 V9 V10 One can’t just stare at this and grasp what the data is “saying.” The numbers don’t “speak for themselves” even apart from being numerically coded.

3
Data Needs to be “Boiled Down” to Reveal Meaningful Information, Patterns, and Relationships
How you do this depends on the nature of the data, e.g., nominal, ordinal, etc. This “boiling down” is commonly referred to as “number crunching.” This boiling down can now be quickly accomplished for even very large data sets by using computer software such as SPSS. For a small data set like the Student Survey, it is feasible (but still tedious) to do this by hand.
 to do this by hand.")
4
Boiling Down Data (cont.)
One variable at a time (Univariate Analysis) Two variables at a time (Bivariate Analysis) Multiple variables at a time (Multivariate Analysis) Two stages: reduce the data to a single relatively compact table (frequency table, crosstabulation, control table, etc.) or corresponding chart (frequency bar graph, histogram, dot chart, box chart, scattergram, etc.) reduce it further to one or several summary statistical measures (measures of central tendency, dispersion, association, correlation and regression coefficients, etc.). We first look at the process of boiling univariate data down to frequency tables, frequency bar graphs, and histograms. Then (univariate) measures of central tendency and dispersion.
 Two variables at a time (Bivariate Analysis) Multiple variables at a time (Multivariate Analysis) Two stages: reduce the data to a single relatively compact table (frequency table, crosstabulation, control table, etc.) or corresponding chart (frequency bar graph, histogram, dot chart, box chart, scattergram, etc.) reduce it further to one or several summary statistical measures (measures of central tendency, dispersion, association, correlation and regression coefficients, etc.). We first look at the process of boiling univariate data down to frequency tables, frequency bar graphs, and histograms. Then (univariate) measures of central tendency and dispersion.")
5
Constructing Frequency Tables for Discrete Variables in the Student Survey Data
Recall that the first question in the Student Survey was the following: Generally speaking, do you think of yourself as a Republican, a Democrat, an Independent, or what? (1) Democrat (2) Independent (3) Republican (4) Other; minor party (5) Don't know [Above is from the Questionnaire/Codebook]
 Democrat. (2) Independent. (3) Republican. (4) Other; minor party. (5) Don t know. [Above is from the Questionnaire/Codebook]")
6
Frequency Table Worksheet
FREQUENCY TABLE OF PARTY ID (V1) Value Code Tallies IDs Abs Freq Rel Freq Adj Rel Freq Dem Ind Rep Other DK NA Total________________________________________________________ ID V1 ID V1 Some data from an earlier semester
 Value Code Tallies IDs Abs Freq Rel Freq Adj Rel Freq. Dem. 1. Ind. 2. Rep. 3. Other 4. DK 5. NA 9. Total________________________________________________________. ID V1 ID V1. Some data from an earlier semester")
7
Frequency Table Worksheet (cont.)
ID V1 ID V1

8
Absolute (Cases Counts) vs. Relative (Percentages) Frequencies
Count up tallies to get absolute frequencies. Use relative frequencies (percentages) to make valid comparisons across data sets of different size: e.g., one student survey with another or (especially) student survey with national data. Relative Frequency (%) = Absolute Frequency × 100% Total N of Cases Also, probably set aside missing data, including “don’t know,” “no opinion,” “other,” etc., cases. Adjusted Rel. Frequency (%) = Absolute Frequency × 100% N of Cases - N of Missing/Invalid Cases
 to make valid comparisons across data sets of different size: e.g., one student survey with another or (especially) student survey with national data. Relative Frequency (%) = Absolute Frequency × 100% Total N of Cases. Also, probably set aside missing data, including don’t know, no opinion, other, etc., cases. Adjusted Rel. Frequency (%) = Absolute Frequency × 100% N of Cases - N of Missing/Invalid Cases.")
9
Frequency Table Worksheet (cont.)
FREQUENCY TABLE OF PARTY ID (V1) Values Code Tallies IDs Abs Freqs Rel Freqs Adj Rel. Freqs. Dem % % Ind [not % % Rep % % Other shown] % DK % NA % Total % % Percentages have been rounded to nearest whole percent. (SPSS rounds to the nearest tenth of a percent.) Rounding may produce rounding error, so that a total that should come out to precisely 100% may actually add up to 101% or 99.9%, etc.
 Values Code Tallies IDs Abs Freqs. Rel Freqs. Adj Rel. Freqs. Dem % 49% Ind. 2 [not 12 28% 29% Rep % 22% Other 4 shown] 0 0% DK 5 2 5% NA 9 0 0% Total % 100% Percentages have been rounded to nearest whole percent. (SPSS rounds to the nearest tenth of a percent.) Rounding may produce rounding error, so that a total that should come out to precisely 100% may actually add up to 101% or 99.9%, etc.")
10
A “Presentation Grade” Frequency Table
PARTY IDENTIFICATION AMONG POLI 300 STUDENTS, FALL 2006 Democratic 49% Independent 29% Republican 22% Total 100% (n = 41) Source: POLI 300 Student Political Attitudes Survey, Fall 2006 Table 1
 Source: POLI 300 Student Political Attitudes Survey, Fall Table 1.")
11
FREQUENCY TABLE OF DEMOCRATIC PARTY THERMOMETER SCALE (V15)
Another Example FREQUENCY TABLE OF DEMOCRATIC PARTY THERMOMETER SCALE (V15) Value Code Abs. Freqs. Rel. Freqs. Adj. Rel. Freqs Cum Rel. Freqs. % 19% % % % 9% % % % 37% % % % % % % % % % % Missing % Total % % Note that V15 is (at least) ordinal in nature. The list of values should follow the natural ordering. If the ordering runs from “Low” to “High,” the lowest value is conventionally put at the top of the list and the highest value at the bottom (illogical though this may seem). There is no missing data, so Adjusted Relative Frequency = Relative Frequency. In this table, we have shown one other type of percentage — namely, cumulative (adjusted relative) frequencies, where the cumulation can proceed either downward or upward. Thus the “61-80" row of the table shows that 19% of the respondents have 61 to 80 degrees of “warmth” toward the Democratic Party, 84% have this level of warmth or cooler (i.e., 80 degrees or less), and 35% have this level of warmth or warmer (i.e., 61 degrees or more). Cumulative frequencies make no sense if the variable in question is merely nominal in nature (or if the table does not list ordinal values in their natural order).
 Value Code Abs. Freqs. Rel. Freqs. Adj. Rel. Freqs. Cum Rel. Freqs % 19% 19% 100% % 9% 28% 81% % 37% 65% 72% % 19% 84% 35% % 16% 100% 16% Missing 9 0 0% Total % 100% Note that V15 is (at least) ordinal in nature. The list of values should follow the natural ordering. If the ordering runs from Low to High, the lowest value is conventionally put at the top of the list and the highest value at the bottom (illogical though this may seem). There is no missing data, so Adjusted Relative Frequency = Relative Frequency. In this table, we have shown one other type of percentage — namely, cumulative (adjusted relative) frequencies, where the cumulation can proceed either downward or upward. Thus the row of the table shows that 19% of the respondents have 61 to 80 degrees of warmth toward the Democratic Party, 84% have this level of warmth or cooler (i.e., 80 degrees or less), and 35% have this level of warmth or warmer (i.e., 61 degrees or more). Cumulative frequencies make no sense if the variable in question is merely nominal in nature (or if the table does not list ordinal values in their natural order).")
12
SPSS Frequency Tables for ANES Discrete Variables
V25 DEMOCRATIC CANDIDATE THERMOMETER SCORE ( ) Code Freq. Percent Valid Percent Cum Percent Valid Total Missing NA Total SPSS uses somewhat different labels for different types of frequencies: Frequency = Absolute Frequency Percent = Relative Frequency Valid Percent = Adjusted Relative Frequency Cum Percent: SPSS cumulates downwards only
 Code Freq. Percent Valid Percent Cum Percent. Valid Total Missing NA Total SPSS uses somewhat different labels for different types of frequencies: Frequency = Absolute Frequency. Percent = Relative Frequency. Valid Percent = Adjusted Relative Frequency. Cum Percent: SPSS cumulates downwards only.")
13
SPSS Frequency Tables for ANES Discrete Variables (cont.)
V30 MOST IMPORTANT NATIONAL PROBLEM ( ) Code Freq. Percent Valid % Cum % Valid economy foreign affairs social welfare crime, public order other Total Missing NA Total Note: SPSS calculates and displays cumulative frequencies auto-matically, even when they make no substantive sense (as with the nominal variable MOST IMPORTANT NATIONAL PROBLEM). SPSS doesn’t “know better”: it operates on the code values and cannot tell the difference between different types of variables.
 Code Freq. Percent Valid % Cum % Valid economy foreign affairs social welfare crime, public order other Total Missing NA Total Note: SPSS calculates and displays cumulative frequencies auto-matically, even when they make no substantive sense (as with the nominal variable MOST IMPORTANT NATIONAL PROBLEM). SPSS doesn’t know better : it operates on the code values and cannot tell the difference between different types of variables.")
14
Frequency Charts Frequency distribution information is often presented by a bar chart. To construct a frequency bar chart, first draw a horizontal line and place tick marks at equal intervals along the line. Each tick mark represents a possible value of the (qualitative or discrete) variable. If the variable is ordinal, the marks should follow the natural ordering of the values. Conventionally (and plausibly), values increase from left to right. Usually missing data is excluded. We then erect a vertical axis that represents (absolute or relative) frequency. The vertical axis can be calibrated in terms of either absolute or relative frequencies. Relative frequencies are more typically displayed, especially with data from surveys (where the actual number of cases depends on sample size and is of no special interest). It is possible, of course, to have two axes (e.g., one at the left and the other at the right edge of the chart) displaying both absolute and relative frequencies. Above each tick mark, we erect a bar with some standard width and the height of which is proportional to the frequency of that value. Conventionally the sides of the bars do not touch each other, representing the fact that the values of the variable are discrete.
 variable. If the variable is ordinal, the marks should follow the natural ordering of the values. Conventionally (and plausibly), values increase from left to right. Usually missing data is excluded. We then erect a vertical axis that represents (absolute or relative) frequency. The vertical axis can be calibrated in terms of either absolute or relative frequencies. Relative frequencies are more typically displayed, especially with data from surveys (where the actual number of cases depends on sample size and is of no special interest). It is possible, of course, to have two axes (e.g., one at the left and the other at the right edge of the chart) displaying both absolute and relative frequencies. Above each tick mark, we erect a bar with some standard width and the height of which is proportional to the frequency of that value. Conventionally the sides of the bars do not touch each other, representing the fact that the values of the variable are discrete.")
15
Bar Chart Work Sheet

16
SPSS Frequency Tables for ANES Discrete Variables
V25 DEMOCRATIC CANDIDATE THERMOMETER SCORE ( ) Code Freq. Percent Valid Percent Cum Percent Valid Total Missing NA Total
 Code Freq. Percent Valid Percent Cum Percent. Valid Total Missing NA Total")
17
FREQUENCY BAR CHART

20
Average Over Eight Years of an Administration Hides Trends Within Each Administration

21
SPSS Frequency Tables for ANES Discrete Variables (cont.)
V30 MOST IMPORTANT NATIONAL PROBLEM Code Freq. Percent Valid % Cum % Valid economy foreign affairs social welfare crime, public order other Total Missing NA Total

22
FREQUENCY BAR CHART (cont.)
")
23
PIE CHARTS Since pie charts do not show values in a linear order, they are especially appropriate for displaying frequencies of nominal variables Since such charts show how a “pie” is “divided up,” they are also especially appropriate for displaying “shares,” such as how parties divide up popular votes, electoral votes, or seats in a legislature, or how a budget is divided up among different spending categories. Using different colors (or hatching) for each slice can help the reader quickly grasp the information in the chart.
 for each slice can help the reader quickly grasp the information in the chart.")
24
But pie charts are not helpful if there are many unordered categories – Just show the quantities in tabular form

25
But then the Pie Chart Is Irrelevant

26
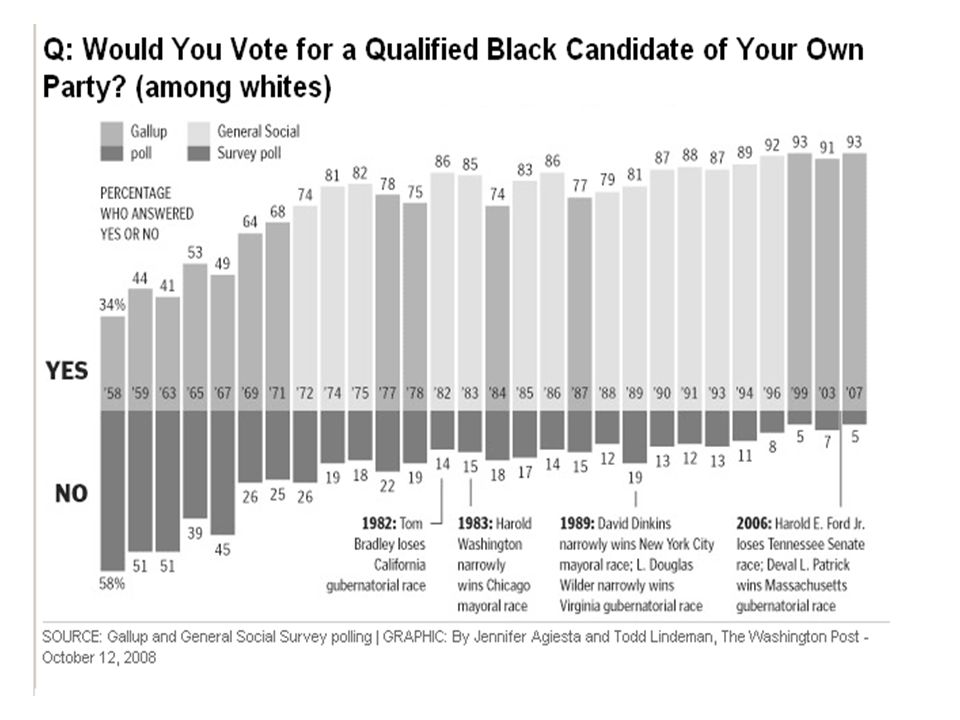
Is Picture Worth a Thousand Words?
Not Always: Sixty eight senators voted for the bill and thirty two voted against.

27
A Picture Worth a Book?

28
Comparing Frequency Distributions for Subsets of Cases, for Different (but “comparable”) Variables, or from different Data Sets (e.g., Student Survey and SETUPS/ANES) Clearly merged or clustered bar graphs like these should display relative frequencies if the data sets (or subsets) being compared are of different size. You might merge (hand drawn) bar graphs in this manner when you compare Student Survey and SETUPS/ANES data in Problem Set #5A.
 being compared are of different size. You might merge (hand drawn) bar graphs in this manner when you compare Student Survey and SETUPS/ANES data in Problem Set #5A.")
29
“Stacked” Bar Graphs Another way to compress and merge bar graphs is to “stack” all the bars of an ordinary bar graph on top of one another to form a single bar representing 100% of the (valid) cases. We can then combine nine such stacked bars to “tell the story” of the changing perceived importance of different types of issues in Presidential elections over the last 33 years.
 cases. We can then combine nine such stacked bars to tell the story of the changing perceived importance of different types of issues in Presidential elections over the last 33 years.")
31
“Cute” Bar Charts This is a bar chart; height represents frequency.
But, as the heights of the “bars” (bullets) vary, their widths also vary propor-tionately. The eye then tends to compare areas rather than heights, producing distinctly misleading impressions. The U.S. has only about twice as many firearms per capita as Switzerland or Finland but its bullet is about four times as large as theirs. This problem is mitigated by the fact that the actual numerical values of firearms per capita is shown
 vary, their widths also vary propor-tionately. The eye then tends to compare areas rather than heights, producing distinctly misleading impressions. The U.S. has only about twice as many firearms per capita as Switzerland or Finland but its bullet is about four times as large as theirs. This problem is mitigated by the fact that the actual numerical values of firearms per capita is shown.")
32
“Cute” Bar Charts (cont.)
Popular newspapers (especially USA Today), magazines, advertise-ments, etc., like to present bar graphs but usually can’t resist the temptation of making them “cute” by letting figures of one sort or other take the place of simple bars. Often, as the heights of the figures vary, their widths also vary in a proportionate manner. The eye then tends to compare areas rather than heights, producing distinctly misleading impressions. Cuteness trumps clarity.
, magazines, advertise-ments, etc., like to present bar graphs but usually can’t resist the temptation of making them cute by letting figures of one sort or other take the place of simple bars. Often, as the heights of the figures vary, their widths also vary in a proportionate manner. The eye then tends to compare areas rather than heights, producing distinctly misleading impressions. Cuteness trumps clarity.")
33
Frequencies of Continuous Variables
Remember: the first step in constructing a frequency table is to list all possible values of the variable. But we cannot do this if the variable of interest is quantitative and continuous in nature, because such a variable has an infinite number of possible values. Remember that all points along (some interval of) the real number line represent possible values of a continuous (and interval) variable One way to proceed is to divide the line representing values of the variable up into a (relatively small) number of segments called class intervals.
 the real number line represent possible values of a continuous (and interval) variable. One way to proceed is to divide the line representing values of the variable up into a (relatively small) number of segments called class intervals.")
34
Class Intervals We noted in Problem Set #3B that some of the variables in the SETUPS/NES data are “truly continuous” in nature but have in effect been turned into discrete variables. This was accomplished by creating class intervals for such variable as V60 (AGE), V65B-E (DOLLAR INCOME), and all the “Thermometer Scales.” Once such class intervals have been created, we can proceed to create frequency tables and charts in the same manner as with discrete variables. Indeed, we have already done this with respect to V25 DEMOCRATIC CANDIDATE THERMOMETER SCORE.
, V65B-E (DOLLAR INCOME), and all the Thermometer Scales. Once such class intervals have been created, we can proceed to create frequency tables and charts in the same manner as with discrete variables. Indeed, we have already done this with respect to V25 DEMOCRATIC CANDIDATE THERMOMETER SCORE.")
36
States by Percent of Population Aged 65 or Older
Note: The data is not recorded entirely precisely; it is obviously rounded off to the nearest one-tenth of one percent. For example, IL, IN, and MS (all recorded as 12.1%) almost certainly have different values on the variable. To boil the data down to a frequency table or graph, we might create class intervals one percentage point wide, i.e., 0-1%, 1-2%, etc. We need some rule (disclosed to readers) about whether (for example) a case with a rounded value of 1.0% goes into the 0-1% or 1-2% interval.) The numerical bounds on adjacent intervals must “touch” each other so that every possible value is included in some interval. [See =>] Note: The AGE intervals in the SETUPS/NES Codebook appear not to “touch” in this way. Presumably the interval actually includes everyone who has not yet turned 25 (and so would be better be written as 17-25), and likewise for other AGE intervals. The following slide shows an SPSS histogram for this data with class intervals one percentage point wide. The intervals are % and so forth and the value labels are the whole numbers at the mid-point of these intervals. You can verify that the 11.5 [e.g., MI] and 12.5 [e.g., OH] observations are included in the and intervals respectively.
 almost certainly have different values on the variable. To boil the data down to a frequency table or graph, we might create class intervals one percentage point wide, i.e., 0-1%, 1-2%, etc. We need some rule (disclosed to readers) about whether (for example) a case with a rounded value of 1.0% goes into the 0-1% or 1-2% interval.) The numerical bounds on adjacent intervals must touch each other so that every possible value is included in some interval. [See =>] Note: The AGE intervals in the SETUPS/NES Codebook appear not to touch in this way. Presumably the interval actually includes everyone who has not yet turned 25 (and so would be better be written as 17-25), and likewise for other AGE intervals. The following slide shows an SPSS histogram for this data with class intervals one percentage point wide. The intervals are % and so forth and the value labels are the whole numbers at the mid-point of these intervals. You can verify that the 11.5 [e.g., MI] and 12.5 [e.g., OH] observations are included in the and intervals respectively.")
37
SETUPS Codebook

38
Histogram of Percent of Population 65+
That there are outliers becomes immediately apparent. This histogram is logically equivalent to a frequency bar chart, with the merely cosmetic difference that the bars touch each other (reflecting the continuous nature of the variable).
.")
39
Histogram vs. Frequency Bar Graph
The preceding histogram is essentially no different from a frequency bar chart because all class intervals all have the same width (in this case,1 percentage point wide). Otherwise (i.e., if the class intervals are not all of equal width), a bar chart and a histogram of the same data may look quite different, in which event the bar chart presents a misleading picture of the data, while the histogram presents a more accurate picture. The histogram, unlike the bar chart takes account of the interval property of the variable. This can be illustrated by focusing on the SETUPS/NES variable V65D (DOLLAR INCOME IN 2004), for which unequal class intervals were created.
. Otherwise (i.e., if the class intervals are not all of equal width), a bar chart and a histogram of the same data may look quite different, in which event the bar chart presents a misleading picture of the data, while the histogram presents a more accurate picture. The histogram, unlike the bar chart takes account of the interval property of the variable. This can be illustrated by focusing on the SETUPS/NES variable V65D (DOLLAR INCOME IN 2004), for which unequal class intervals were created.")
40
SPSS Frequency Table for V65D
V65D DOLLAR INCOME (2004) Freq. Percent Valid % Cum. % Valid Less than $15, $15,000 to $25, $25,000 to $35, $35,000 to $50, $50,000 to $80, $80,000 to $120, More than $120, Total Missing NA Total
 Freq. Percent Valid % Cum. % Valid Less than $15, $15,000 to $25, $25,000 to $35, $35,000 to $50, $50,000 to $80, $80,000 to $120, More than $120, Total Missing NA Total")
41
SPSS Bar Chart for V65D The bar chart appears to display a distribution of income that is approxi-mately “uniform” – that is, all bars are approximately the same height, except for a distinctive peak (or “mode”) in the third highest income category. Indeed, the impression the bar graph conveys to the eye is that there are more well-off than not-so-well-off people. However, this impression is quite misleading, as you can begin to under-stand when you look more closely at the income class intervals and notice that they are not of equal width. Here is the histogram of the same INCOME data =>
 in the third highest income category. Indeed, the impression the bar graph conveys to the eye is that there are more well-off than not-so-well-off people. However, this impression is quite misleading, as you can begin to under-stand when you look more closely at the income class intervals and notice that they are not of equal width. Here is the histogram of the same INCOME data =>")
42
Histogram for V65D The fundamental difference between a bar graph and a histogram: in a bar graph, frequency is represented by the height of the bars (all of which have the same width); in a histogram, frequency is represented by the area of the “bars” (which may have different widths, reflecting the different “widths” of the class intervals). With equal class intervals, the area of a bar depends only on its height, so Histogram ≈ Frequency Bar Chart But with unequal class intervals, the area of a bar depends on both its height and its width, so Histogram ≠ Frequency Bar Chart
; in a histogram, frequency is represented by the area of the bars (which may have different widths, reflecting the different widths of the class intervals). With equal class intervals, the area of a bar depends only on its height, so Histogram ≈ Frequency Bar Chart. But with unequal class intervals, the area of a bar depends on both its height and its width, so Histogram ≠ Frequency Bar Chart.")
43
How to Construct the Histogram of V65D
To draw this a histogram, we first draw a horizontal line, i.e., a real number line, representing the possible values of the variable. Since the variable is interval and continuous, we can place tick marks at equal intervals (like inches on a ruler) to mark equal increments in the value of the variable. In the figure above, I have put tick marks at $0K, $20K, $40K, etc., up to $260K for INCOME.
 to mark equal increments in the value of the variable. In the figure above, I have put tick marks at $0K, $20K, $40K, etc., up to $260K for INCOME.")
44
How to Construct the Histogram of V65D (cont.)
Next we put other [red] marks along the scale at the points that separate the class intervals we are using in this case at $0, $15K, $25K, $35K, $50K, $80K, and $120K. Note this problem: the highest class interval has no definite upper bound and thus no definite width. Here I have set an upper bound more or less arbitrarily at $250K. In contrast, the lowest class interval has a definite width, since INCOME is a ratio variable and cannot have values less than 0. We will remove these marks between the class intervals later.

45
How to a Construct Histogram of V65D (cont.)
Next we erect a vertical axis (analogous to the vertical axis that indicates frequency in a bar graph). However, this axis in fact does not indicate frequency and (like the red interval marks) is only temporary “scaffolding” that is erected to help us construct the histogram but which will be taken down once the construction is finished. The scale marked on the vertical axis is drawn (like the frequency scale in a bar chart) to accommodate the height of the “bars” of the histogram. It is essential that the scale begin at zero.
. However, this axis in fact does not indicate frequency and (like the red interval marks) is only temporary scaffolding that is erected to help us construct the histogram but which will be taken down once the construction is finished. The scale marked on the vertical axis is drawn (like the frequency scale in a bar chart) to accommodate the height of the bars of the histogram. It is essential that the scale begin at zero.")
46
Histogram of V65D (cont.) Next we erect a rectangle (a “bar,” if you wish) on each class interval, so that the area [not height] of each rectangle is proportional to the frequency associated with that class interval. How tall should each rectangle be? The width of each rectangle is the width of the class interval, and [from 3rd grade we remember that] Area = Height × Width so Height = Area / Width Since Area here represents Frequency, we have the formula: Height = Frequency / Width, where Width is the width of the class interval.
 on each class interval, so that the area [not height] of each rectangle is proportional to the frequency associated with that class interval. How tall should each rectangle be The width of each rectangle is the width of the class interval, and [from 3rd grade we remember that] Area = Height × Width so Height = Area / Width. Since Area here represents Frequency, we have the formula: Height = Frequency / Width, where Width is the width of the class interval.")
47
Histogram of V65D (cont.) Now we can calculate the following (relative) heights of all the bars/rectangles. (Since only relative magnitudes matter, we can ignore the $000 = $K in INCOME values.) Class Interval Width Freq. Freq/Width Height / = / = / = / = / = / = / = Now we can draw the appropriate scale on the vertical axis. The tallest rectangle has a (relative) height of about 1.14, so the axis should extend a bit higher than this. Having constructed the bars/rectangles, we should remove the vertical axis and scale. Otherwise, readers are likely to (mis)interpret it as representing frequency, like the vertical axis in a bar graph.
 heights of all the bars/rectangles. (Since only relative magnitudes matter, we can ignore the $000 = $K in INCOME values.) Class Interval Width Freq. Freq/Width Height / 15 = / 10 = / 10 = / 15 = / 30 = / 40 = /130 = Now we can draw the appropriate scale on the vertical axis. The tallest rectangle has a (relative) height of about 1.14, so the axis should extend a bit higher than this. Having constructed the bars/rectangles, we should remove the vertical axis and scale. Otherwise, readers are likely to (mis)interpret it as representing frequency, like the vertical axis in a bar graph.")
48
Given that height in a histogram does not represent frequency, what does it represent?
The answer is that height represents density — that is, how densly observed values of cases are “packed into” each class interval. Note that the class interval $50-80K includes about twice as many cases (23.3%) as the interval $15-25K (11.4%). This fact is reflected in the bar graph in Figure 9 by the fact that the bar on the $50-80K interval is about twice as high as the bar over the $15-25K interval. It is reflected in the histogram in Figure 10 by the fact that the “bar” (rectangle) on the $50-80K interval has about twice the area of the bar on the $15-25K interval. But the 23.3% of the cases in the $50-80K interval are spread over an income interval that is three times as wide as the interval into which the 11.4% of the cases in the $15-25K interval are packed, so the height of the former (wide) bar is actually less than the height of the latter (thin) bar.
 as the interval $15-25K (11.4%). This fact is reflected in the bar graph in Figure 9 by the fact that the bar on the $50-80K interval is about twice as high as the bar over the $15-25K interval. It is reflected in the histogram in Figure 10 by the fact that the bar (rectangle) on the $50-80K interval has about twice the area of the bar on the $15-25K interval. But the 23.3% of the cases in the $50-80K interval are spread over an income interval that is three times as wide as the interval into which the 11.4% of the cases in the $15-25K interval are packed, so the height of the former (wide) bar is actually less than the height of the latter (thin) bar.")
49
Areas, Populations, and Population Densities
It might (or might not) be helpful to point out that a histogram type of diagram could be used to display the areas, population, and population density of each U.S. states. Each state would be represented by a segment of the horizontal axis proportional to its area [square miles]. The total population of each state would be represented by the area of the rectangle erected on its interval. The height of the rectangle would represent the state’s population density [people per square mile]. Only if all states had the same area would their populations depend solely on their population densities.
 be helpful to point out that a histogram type of diagram could be used to display the areas, population, and population density of each U.S. states. Each state would be represented by a segment of the horizontal axis proportional to its area [square miles]. The total population of each state would be represented by the area of the rectangle erected on its interval. The height of the rectangle would represent the state’s population density [people per square mile]. Only if all states had the same area would their populations depend solely on their population densities.")
50
Continuous Densities The INCOME histogram was based on a small number of (rather wide) class intervals and a modest number of cases (n = 1212). Remember that INCOME is interval and (essentially) continuous. Suppose we have INCOME data that is recorded very precisely, e.g., to the near dollar or even cent. Suppose also we have a huge --- approaching infinite ---number of cases. We could then refine INCOME into narrower and narrow (i.e., more precise) class intervals, redrawing the histogram accordingly. If we pushed this process to the limit, we would end up with what would be an essentially continuous (and probably fairly smooth) density curve This is illustrated in the following series of charts using a symmetric (“normal’) distribution and equal class intervals that get narrower and narrower (i.e., more precise).
 continuous. Suppose we have INCOME data that is recorded very precisely, e.g., to the near dollar or even cent. Suppose also we have a huge --- approaching infinite ---number of cases. We could then refine INCOME into narrower and narrow (i.e., more precise) class intervals, redrawing the histogram accordingly. If we pushed this process to the limit, we would end up with what would be an essentially continuous (and probably fairly smooth) density curve. This is illustrated in the following series of charts using a symmetric ( normal’) distribution and equal class intervals that get narrower and narrower (i.e., more precise).")
51
Approaching a Continuous Density Curve

52
Cut the width of the Class Intervals in Half

53
Cut the width of the Class Intervals in Half Again

54
And Again

55
And Again

56
We Approach a Continuous Density [Normal] Curve
![We Approach a Continuous Density [Normal] Curve](http://slideplayer.com/slide/1648969/7/images/56/We+Approach+a+Continuous+Density+%5BNormal%5D+Curve.jpg "We Approach a Continuous Density [Normal] Curve")
57
A Continuous Income Density Curve [“Eyeball estimate”]
Contrary to the (hypothetical) continuous density curve for INCOME with Problem Set #5C, the SETUPS/NES data suggests that the distribution of household income has two “peaks” (or modes), one at about $18K and another at about $43K, with a slight “valley” between them. This probably results from the fact that there are two types of households: family or multi-person households (typically two or more adults and often children as well) and single-person households (typically widows/widowers or young adults who have recently “flown the nest” but are not yet married with children). On average, the former type of household has (and needs) higher income than the latter. This tends to produce two peaks in the overall distribution of household income.
![A Continuous Income Density Curve [ Eyeball estimate ]](http://slideplayer.com/slide/1648969/7/images/57/A+Continuous+Income+Density+Curve+%5B+Eyeball+estimate+%5D.jpg "Contrary to the (hypothetical) continuous density curve for INCOME with Problem Set #5C, the SETUPS/NES data suggests that the distribution of household income has two peaks (or modes), one at about $18K and another at about $43K, with a slight valley between them. This probably results from the fact that there are two types of households: family or multi-person households (typically two or more adults and often children as well) and single-person households (typically widows/widowers or young adults who have recently flown the nest but are not yet married with children). On average, the former type of household has (and needs) higher income than the latter. This tends to produce two peaks in the overall distribution of household income.")
58
A Symmetric [Normal] Density Curve
![A Symmetric [Normal] Density Curve](http://slideplayer.com/slide/1648969/7/images/58/A+Symmetric+%5BNormal%5D+Density+Curve.jpg "A Symmetric [Normal] Density Curve")
59
An Asymmetric Density Curve

Similar presentations











 www.csd.abdn.ac.uk/~jhunter/teaching/CS1512/lectures/ © J R W Hunter,>")










