Download presentation
Presentation is loading. Please wait.

2
Mariela Curiel and Guillermo Heuer Simón Bolívar Unirversity, Caracas- Venezuela

3
Basic Definitions Stages in the process of GBLOT Development: First Stage: Generation of synthetic trace Second Stage: Generation of workload to a real blogging system Third Stage: Posts and a distributed architecture Conclusions and Future Work

4
The Workload consists of a list of service requests submitted to a computer system.

5
Workload generator : software tool that generates a synthetic workloads to a benchmark or real application to emulate the behavior of end users. Examples: Surge, httperf. Workload generators are based on workload models that properly emulate users behavior.

6
GBLOT is a generator of workloads for the blogosphere. It is based on analytical models, which can be used to evaluate the short-term behavior of blog hosting sites.

7
The user session model is based on CBMGs (Customer Behavior Model Graphs) (Menascé, 2000). GBLOT was written in C. 76% Start Reading New Blog Continue Reading Same Blog Make Comments Exit 14% 63% 31% 30% 6% 33% 1% 23% 2% 21%

8
The construction of GBLOT was performed in three stages: First Stage: the development of analytical models, Second Stage: the connection with a real blog server and Third Stage: the inclusion of blog posts in a distributed architecture.

9
We describe the entire GBLOT development process and we try to identify the challenges in each stage. The aim is to point possible new problems out related to the development of workload generators to evaluate the performance of Web 2.0 applications

10
The development of statistical models for blog accessesstatistical models for blog accesses The definition of the user session model The construction of software for the generation of synthetic workloads.

11
First, it is necessary to identify and measure those characteristics of the workloads which are important to model: Blog popularity and comment sizes. statistical distributions were obtained from a real workload. real workload

13
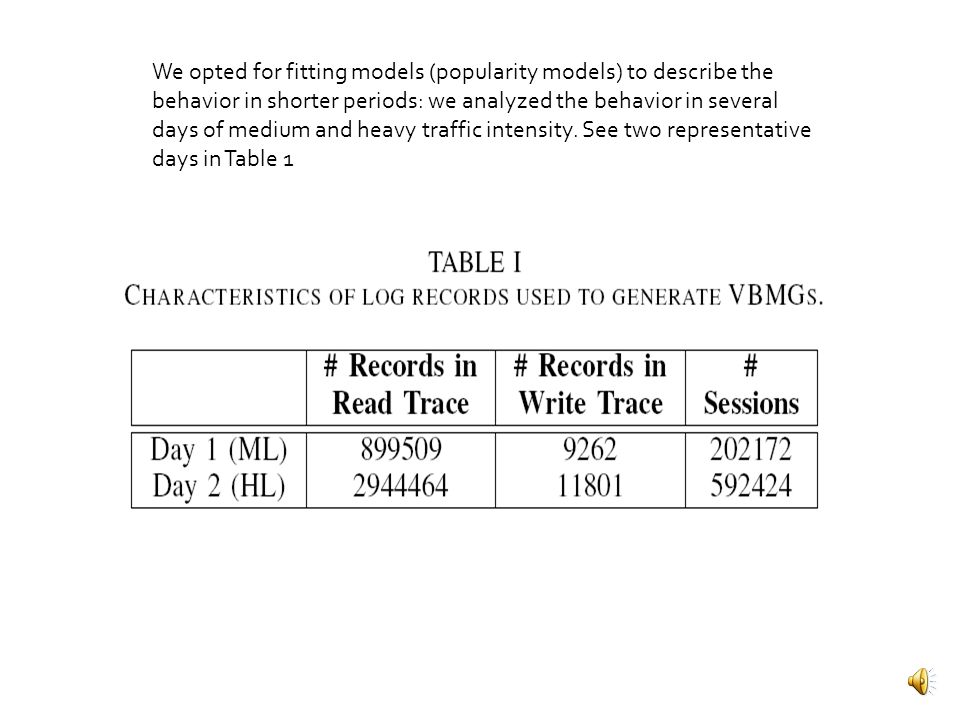
We opted for fitting models (popularity models) to describe the behavior in shorter periods: we analyzed the behavior in several days of medium and heavy traffic intensity. See two representative days in Table 1

14
The popularity of objects in blogspace, follows a general power law with skew parameter alpha. Using the total number of read requests to a blog as indicative of popularity yields a skew of alpha=0.97. Using the total number of posted comments to a blog as indicative of its popularity yields a smaller skew of alpha=0.70. Statistical Models Duarte, F. et al, 2007. Trac Characteristics and Communication Patterns in Blogosphere. International Conference on Weblogs and Social Media. Colorado, USA

15
A Pareto distribution with parameter alpha 1 fits the tail of the transfer size distribution. This result is consistent with what has been observed for traditional web traffic. Statistical Models

16
The development of statistical models for blog accesses The definition of the user session model The definition of the user session model The construction of the workload generator program

17
In order to model the behavior of a blogosphere visitor, we use a Visitor Behavior Model Graph (VBMG). A VBMG is a state-transition graph proposed in [menasce1999]. In this graph, nodes represent possible states. A probability is assigned to each transition between two states. 85% Read a New Blog Continue Reading Blog Make Comments Exit 60% 9% 45% 24% 11% 20% 2% 31% 13% VBMG

18
Start Reading New Blog: A user visits this state either when she/he issues the first request to the blogosphere or when she visits a new blog Continue Reading Same Blog: A user visits this state, if, after reading a blog for a first time during a session, she decides to read other posts in that same blog. The user leaves this state when she either (1) reads a new blog, (2) decides to make a comment, or (3) navigates away by accessing a web page out of the blogspace. Make Comments: A user visits this state when she writes comments on a blog post. 85% Read a New Blog Continue Reading Blog Make Comments Exit 60% 9% 45% 24% 11% 20% 2% 31% 13% VBMG
 reads a new blog, (2) decides to make a comment, or (3) navigates away by accessing a web page out of the blogspace. Make Comments: A user visits this state when she writes comments on a blog post. 85% Read a New Blog Continue Reading Blog Make Comments Exit 60% 9% 45% 24% 11% 20% 2% 31% 13% VBMG.")
19
Based on log analysis it is possible to characterize different types of users using VBMGs that differ in their transition probabilities. Continue Reading Same Blog Start Reading a New Blog Exit 7% 99% 50% 43% 1% 85% Read a New Blog Continue Reading Blog Make Comments Exit 60% 9% 45% 24% 11% 20% 2% 31% 13% VBMG

20
The development of statistical models for blog accesses The definition of the user session model The construction of the workload generator program. The construction of the workload generator program

21
GBLOT Visitor Classes Blog accesses Time of the generation Number of Blogs Summary FileTrace File

22
GBLOT Visitor Classes Summary File ג 1 arrival rate ג 2 arrival rate Other Parameters Trace File

23
GBLOT Time of the generation Number of Blogs Summary FileTrace File Blog accesses Distributional Data

24
*** Sessions From class-4 visitors, 48 sessions were initiated and 47 sessions finished From class-2 visitors, 84 sessions were initiated and 81 sessions finished From class-3 visitors, 142 sessions were initiated and 140 sessions finished From class-1 visitors, 507 sessions were initiated and 507 sessions finished ***Total Number of Requests: 4340 Read requests 4110 (94.70%) Write requests (comments) 230 (5.30%) *** Blog accesses Blog Number of Requests 1166 2146 351 459 551 644 744 845 Summary File
 Write requests (comments) 230 (5.30%) *** Blog accesses Blog Number of Requests Summary File")
26
GBLOT's software architecture consists of three main components: A set of programs to generate distributional data, A master program and A multiprocess-multithreaded program, which, jointly, generate the concurrent visitor sessions that will make up the blogserver's requests. GBLOT's software architecture follows in part the design of Surge HTTP workload generator (Badford, 1998). It consists of three main components: a set of programs to generate distributional data, a master program and a multiprocess-multithreaded program, which, jointly, generate the concurrent visitor sessions that will make up the blogserver's requests. Arquitecture
. It consists of three main components: a set of programs to generate distributional data, a master program and a multiprocess-multithreaded program, which, jointly, generate the concurrent visitor sessions that will make up the blogserver s requests. Arquitecture.")
27
Creates a process for each visitor class. Feeds distributional data into pipes which provide input data to the threads simulating visitor sessions. Interrupts the generation of new sessions (and requests) once the specified time is reached. Master Pipes Data process thread
 once the specified time is reached. Master Pipes Data process thread.")
28
Each g-process implements a visitor class according to its VBMG. To do so, it dynamically creates threads to simulate concurrent sessions submitting requests to the blog server. Master Pipes Data process thread

29
Each thread is created following the session inter- arrival time distribution of the implemented visitor class and it is responsible for generating the requests that compose a single session. The type of request is determined by the VBMG implemented. Master Pipes Data process thread

30
Sesiones Characteristics GBLOT The output is a synthetic trace, there is not communication to a real blog server. The user session model only includes activities related to reading and commenting on the various blogs belonging to the blogosphere. Summary of the Characteristics of the First Version

31
Sesiones(bgclient) Procesos que generan sesiones de un mismo tipo GBLOT Experimentos reales Traza Sintética CPU Disks Client Stations
 Procesos que generan sesiones de un mismo tipo GBLOT Experimentos reales Traza Sintética CPU Disks Client Stations")
32
GBLOT was validated by comparing some of the characteristics of synthetically generated workloads with those observed in the real workload. Characteristics considered in the comparison included not only workload attributes directly used in GBLOT's parameterization, such as blog popularity, but also other attributes that were indirectly derived, such as the inter-read times, inter-comment times, and inter-read times for the most popular blog.

33
The validation process was successful in general: blog popularity, inter-read times, inter-comment times. However, the numbers of generated sessions was 32% smaller than the ones observed in the real traces in heavy loaded days. This was mainly attributed to limitations related to the generation of user sessions from one machine.

35
One of the main challenges is to construct a workload generator capable of communicating with a variety of blogging systems. For web workload generators such as Surge or httperf this task is easier because they interact with the web server using the standard HTTP protocol. The generation of workload to a real blogging system

36
Workload generators for Web 2.0 applications need standardized application level protocols such as the ATOM Publishing protocol. This is an application-level protocol for publishing and editing web resources. Despite it was published as standard in 2007, there are still some barriers to adopt this protocol. The generation of workload to a real blogging system

37
In order to separate the blog server protocol from the workload generative model implemented by GBLOT, we designed a system based on plugins or dynamic libraries Plugin system encapsulates the specific blogserver communication protocol

38
We created an API with the main operations to blog resources (read, comment, create and publish) The plugin contains the implementation of functions that request services to a specific blog server; these functions are attached and detached dynamically. Plugin developers must implement these interfaces. We wrote the plugin for Movable Type publishing system (Movable Type 2011).
..")
39
The XMLgenerator creates and returns XML strings with the information necessary to subsequently construct read or write requests to the blog server. The communicator has two functions: First, It interprets a XML output using a SAX based parser (expat) and fills internal data structures. Second, the communicator uses data stored in the structures to built and send appropriate messages to the blog publishing system. The library curl was used in the communication process.
 and fills internal data structures. Second, the communicator uses data stored in the structures to built and send appropriate messages to the blog publishing system. The library curl was used in the communication process..")
40
GBLOT Visitor Classes Blog accesses Plugin name Time of the generation Number of Blogs Summary File Blog Map Trace File

41
GBLOT Blog Sizes Blog sizes follows statistical distributions. Creation of artificial blogs Blog Map: location of blog files in the blog server 1.We create the artifial blogs in the server and obtain the blog map.

42
2.The blog map is used as input to GBLOT Blog Sizes Blog Map GBLOT 3. The workload generation Process starts.

43
GBLOT Visitor Classes Blog accesses Plugin name Time of the generation Number of Blogs Summary File Blog Map Trace File

44
As a weblog publishing system we choose Movable Type. To test the new version of GBLOT we created 4445 blogs. Once we set the server, we use GBLOT to generate two synthetic workloads representative of medium and heavy load periods, both with durations equal to 1/2 hour.

45
Characteristics of synthetically generated workloads were then compared against the corresponding 1/2-hour real requests and whenever possible with characteristics observed in the complete real trace.

46
The validation of GBLOT outputs with respect to input assumptions is again required.

47
The tail of the transfer size distribution follows a Pareto distribution, with α = 0.96 (very close to 1). This result agrees with result presented in the study of blogosphere traffic.

48
We found that GBLOT could generate loads of what we defined as day of medium load satisfactorily The percentage of error increased in the heavy loaded day: it reached 46.44% for read requests

49
It is important to include the post generation because of its effect on the bandwidth consumption Distributed architecture is necessary if we want to model scenarios happening in days or hours of heavy loads ( flash crowds)
")
50
Blogosphere users should be able to know and access the new posts. This leads to two important challenges: First, when a distributed architecture is implemented, the generator needs group communications primitives, such as multicast or broadcast, to send the access information among simulated users. Second, the popularity of the blog where the new post is inserted could change.

51
Master LAN NETWORK G-process threads Computer 1 Computer 2 Computer N Server

52
Master LAN NETWORK G-process threads Computer 1 Computer 2 Computer N Server New Post

53
Master LAN NETWORK Server New Post Multicast Thread receptor

54
Blogosphere users should be able to know and access the new posts. This leads to two important challenges: First, when a distributed architecture is implemented, the generator needs group communications primitives, such as multicast or broadcast, to send the access information among simulated users. Second, the popularity of the blog where the new post is inserted could change. popularity

55
To properly represent dynamic popularity changes in an analytical workload generator, it is necessary to characterize the behavior of some variables, such as the posts inter-arrival time, post sizes, the access probability with respect to previous entries in the same blog and the distribution of blog access. The lack of data impeded us the fitting of models to represent changes in popularity as a result of the creation of new posts.

56
Third STage

57
GBLOT Visitor Classes Distributional Files: blog accesses, coment sizes, entry sizes Time of the generation Number of Blogs Summary File Blog Map

58
GBLOT Visitor Classes Distributi onal Files Time of the generation Number of Blogs Summary File Blog Map Number of client machines

59
Preliminary tests show that troughput can be improved a 60% with the distributed architecture.

60
We have described the entire development process of GBLOT by especially underlining the challenges. Some of these problems could be extended to other Web 2.0 applications.

61
Standardized application level protocols are necessary to enable the development of workload generators suitable for different platforms. Distributed architecture allows the workload generator to model scenarios happening in days or hours of heavy loads, such as flash crowds.

62
The implementation of group operations is required. In order to access the new content, everyone needs to know it. The introduction of new posts in the blogosphere could influence the popularity of the proprietary blog. So it is necessary to collect data that allow us to model the creation rate and the access pattern to these new objects

63
Inclusion of dynamic popularity models. The extension of GBLOT model to other Web 2.0 based applications.

Similar presentations






















![Introduction Peter Dolog dolog [at] cs [dot] aau [dot] dk 2.2.05 Intelligent Web and Information Systems September 9, 2010.](/11/3031482/big_thumb.jpg "Introduction Peter Dolog dolog [at] cs [dot] aau [dot] dk 2.2.05 Intelligent Web and Information Systems September 9, 2010.>")