Download presentation
Presentation is loading. Please wait.

1
Bayesian network for gene regulatory network construction
Jin Chen CSE 2012 Fall

2
Layout Bayesian network learning Scalability and Precision
Large-scale learning algorithms Integrative approaches

3
Bayesian network - concept
A Bayesian network X is a probabilistic graphical model that represents a set of random variables and their conditional dependencies via a directed acyclic graph nodes variable; edges conditional dependency Disconnected nodes variables are conditionally independent of each other Each node is associated with a probability function that takes as input a set of values for the node's parent and gives the probability of the variable represented by the node X is a Bayesian network with respect to G if its joint probability density function can be written as: adopted from Wikipedia

4
Bayesian network - example
Bayesian network Structure: there are 2 events which could cause grass to be wet: either the sprinkler is on or it's raining. The rain has a direct effect on the use of the sprinkler. The conditional probability tables (CPT) are learned from historical data. Then the joint probability is P(G,S,R) = P(G|S,R)P(S|R)P(R) adopted from Wikipedia
 are learned from historical data. Then the joint probability is P(G,S,R) = P(G|S,R)P(S|R)P(R) adopted from Wikipedia.")
5
Bayesian network - example
What is the probability that it is raining, given the grass is wet? What is the probability that it is raining, given the grass is wet? adopted from Wikipedia

6
Bayesian network – structure learning
In the simplest case, a Bayesian network structure is specified by an expert and is then used to perform inference In the cases that the task of defining the network structure is too complex for humans, the network structure and the parameters of the local distributions must be learned from data Automatically learning the structure of a Bayesian network is a challenge pursued within machine learning Methods of structural learning usually uses optimization based search, which requires a scoring function and a search strategy The time requirement of an exhaustive search returning back a structure that maximizes the score is super-exponential in the number of variables A common scoring function is posterior probability of the structure given the training data.

7
Bayesian network learning for gene regulatory networks
Bayesian networks are well suited to model relationships between genes because: BN uses an acyclic direct graph to denote the relationship between the variables of interest (genes), thus can naturally model causal relationships between genes BN has a solid theoretical foundation and offers a probabilistic approach to accommodate the variations typically observed in microarray experiments BN can accommodate missing data and incorporate prior knowledge through prior distribution of the parameters
, thus can naturally model causal relationships between genes. BN has a solid theoretical foundation and offers a probabilistic approach to accommodate the variations typically observed in microarray experiments. BN can accommodate missing data and incorporate prior knowledge through prior distribution of the parameters.")
8
Gene regulatory network construction
Various GRN structure learning approaches Pair-wise comparison Differential equation estimation Bayesian network learning Common problem: only a relatively small number of genes were included into the network Recent studies have been targeted at deriving the large-scale or even complete networks using heterogeneous functional genomics data as well as gene expression data

10
Gene regulatory network construction
Use a combination of scoring approaches and K2 algorithm to maximize the computational efficiency of network inference Step 1. Construct an undirected network based on mutual information (MI). This allows us to search the best DAG in a reduced space Step 2. Assign directions to the edges. The undirected network is split into sub-networks. Given the node ordering information, the sub-networks are trained with K2 algorithm sequentially. For each sub-network, the directions of edges can be identified based on the BDe score The degree of dependency between random variables will give us an approximate estimate of how the variables in the network are related
. This allows us to search the best DAG in a reduced space. Step 2. Assign directions to the edges. The undirected network is split into sub-networks. Given the node ordering information, the sub-networks are trained with K2 algorithm sequentially. For each sub-network, the directions of edges can be identified based on the BDe score. The degree of dependency between random variables will give us an approximate estimate of how the variables in the network are related.")
11
Constructing undirected networks
Construct undirected networks based on mutual information (MI). MI between two variables X & Y, denoted by I(X; Y), is defined as the amount of information shared between the two variables. It is used to detect general dependencies in data where
. MI between two variables X & Y, denoted by I(X; Y), is defined as the amount of information shared between the two variables. It is used to detect general dependencies in data. where.")
12
Constructing undirected networks
MI measures the dependency between two random variables The greater the MI values I(X; Y), the more closely the two variables are related If there is a direct edge in GRN between X and Y, there exists a strong dependency between X and Y This allows us to search the best DAG only in a reduced space
, the more closely the two variables are related. If there is a direct edge in GRN between X and Y, there exists a strong dependency between X and Y. This allows us to search the best DAG only in a reduced space.")
13
Graph splitting Every node and all its neighbors form a sub-network
For each sub-network, K2 algorithm is used to find the optimal edge orientations that maximize BDe score (Bayesian Dirichlet equivalence) This is reasonable because to maximize the BDe for the whole network, one only need to find all the sub-networks with the best BDe scores Cooper,G.F. and Herskovits,E. (1992) A Bayesian method for the induction of probabilistic networks from data. Mach. Learn., 9, 309–347.
 This is reasonable because to maximize the BDe for the whole network, one only need to find all the sub-networks with the best BDe scores. Cooper,G.F. and Herskovits,E. (1992) A Bayesian method for the induction of probabilistic networks from data. Mach. Learn., 9, 309–347.")
14
Decide the order of sub-networks
In each sub-network, K2 algorithm is run to obtain the best directed sub-network structure The K2 result of one sub-network may affect the topology of other sub-networks. Thus we need to decide the order of the sub-networks for K2 algorithm Ordering: for each node in the whole undirected network, the number of edges connecting to it is counted; nodes are then sorted in descending order

15
K2 algorithm

16
Scoring function

18
Performance Correct Edges Miss Wrong orientation Wrong connection

19
Small network

20
Large network

21
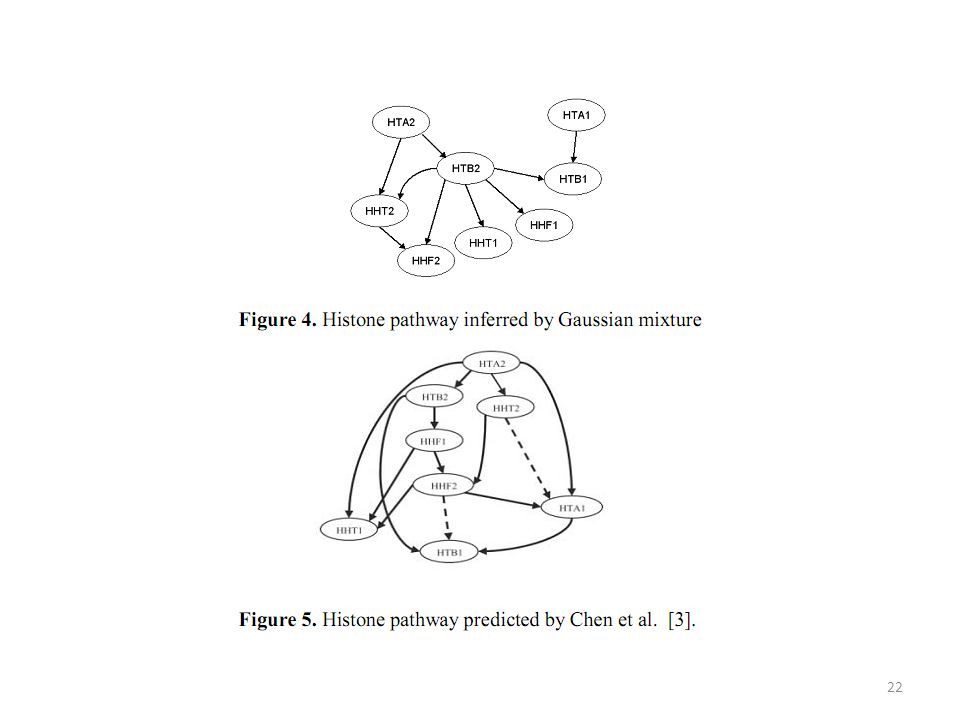
Further improvement Ko et al further developed a new Bayesian network, in which Gaussian mixture models is used to describe continuous gene expression data and learn gene pathways Data discretization is often required since many approaches to learn network structures were developed for binary or discrete input data The discretization of continuous values can result in loss of information and different discretizations can substantially change the input values and the inferred network Ko et al. Inference of Gene Pathways Using Gaussian Mixture Models. IEEE International Conference on Bioinformatics and Biomedicine. pp

24
Integrative approaches
Tamada et al. Bioinformatics Vol. 19 Suppl , pages ii227–ii236

25
Dynamic approaches Reconstruct gene regulatory networks from expression data using dynamic Bayesian network (DBN) Zou M, Conzen SD: A new dynamic Bayesian network (DBN) approach for identifying gene regulatory networks from time course microarray data. Bioinformatics 2005, 21(1):71-79.
 approach for identifying gene regulatory networks from time course microarray data. Bioinformatics 2005, 21(1):")
Similar presentations