Download presentation
Presentation is loading. Please wait.

1
Chapter 4 Describing the Relation Between Two Variables
4.3 Diagnostics on the Least-squares Regression Line

2
The coefficient of determination, R2, measures the percentage of total variation in the response variable that is explained by least-squares regression line. The coefficient of determination is a number between 0 and 1, inclusive. That is, 0 < R2 < 1. If R2 = 0 the line has no explanatory value If R2 = 1 means the line variable explains 100% of the variation in the response variable.

3
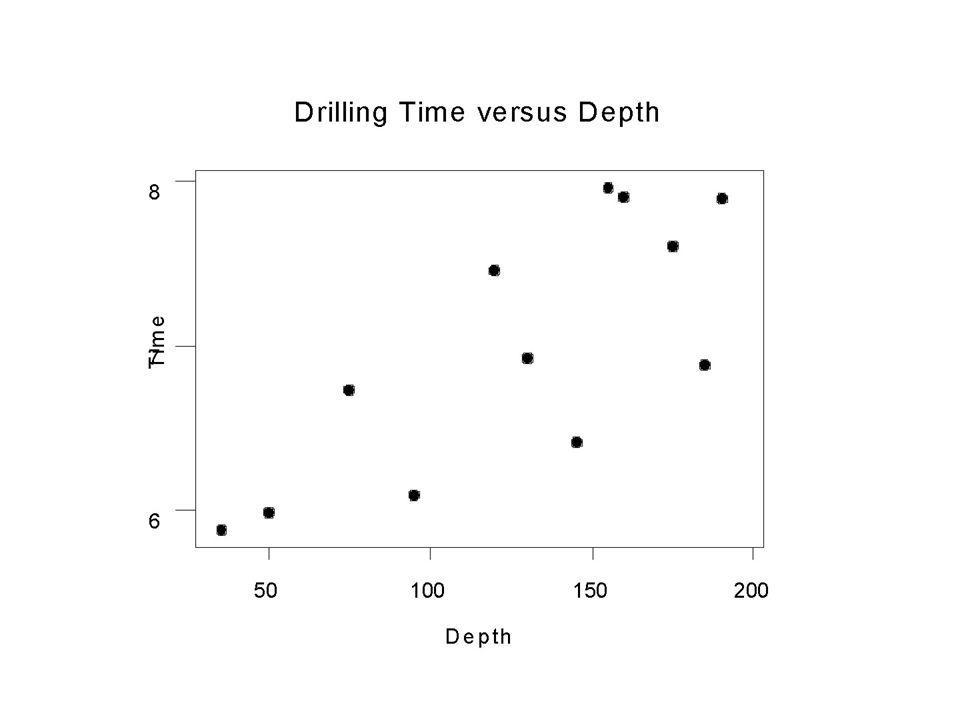
The following data are based on a study for drilling rock
The following data are based on a study for drilling rock. The researchers wanted to determine whether the time it takes to dry drill a distance of 5 feet in rock increases with the depth at which the drilling begins. So, depth at which drilling begins is the predictor variable, x, and time (in minutes) to drill five feet is the response variable, y. Source: Penner, R., and Watts, D.G. “Mining Information.” The American Statistician, Vol. 45, No. 1, Feb. 1991, p. 6.
 to drill five feet is the response variable, y. Source: Penner, R., and Watts, D.G. Mining Information. The American Statistician, Vol. 45, No. 1, Feb. 1991, p. 6.")
6
Mean Standard Deviation Depth 126.2 52.2 Time 6.99 0.781
Sample Statistics Mean Standard Deviation Depth Time Correlation Between Depth and Time: 0.773 Regression Analysis The regression equation is Time = Depth

7
Suppose we were asked to predict the time to drill an additional 5 feet, but we did not know the current depth of the drill. What would be our best “guess”?

8
Suppose we were asked to predict the time to drill an additional 5 feet, but we did not know the current depth of the drill. What would be our best “guess”? ANSWER: The mean time to drill an additional 5 feet: 6.99 minutes.

9
Now suppose that we are asked to predict the time to drill an additional 5 feet if the current depth of the drill is 160 feet?

10
Now suppose that we are asked to predict the time to drill an additional 5 feet if the current depth of the drill is 160 feet? ANSWER: Our “guess” increased from 6.99 minutes to 7.39 minutes based on the knowledge that drill depth is positively associated with drill time.

11
The difference between the predicted drill time of 6
The difference between the predicted drill time of 6.99 minutes and the predicted drill time of 7.39 minutes is due to the depth of the drill. In other words, the difference in our “guess” is explained by the depth of the drill. The difference between the predicted value of 7.39 minutes and the observed drill time of 7.92 minutes is explained by factors other than drill time.

13
The difference between the observed value of the response variable and the mean value of the response variable is called the total deviation and is equal to

14
The difference between the predicted value of the response variable and the mean value of the response variable is called the explained deviation and is equal to

15
The difference between the observed value of the response variable and the predicted value of the response variable is called the unexplained deviation and is equal to

17
Total Deviation = Unexplained Deviation + Explained Deviation

18
Total Variation = Unexplained Variation + Explained Variation

19
+ = 1 – Total Variation = Unexplained Variation + Explained Variation
1 = + Total Variation Total Variation Explained Variation Unexplained Variation = 1 – Total Variation Total Variation

20
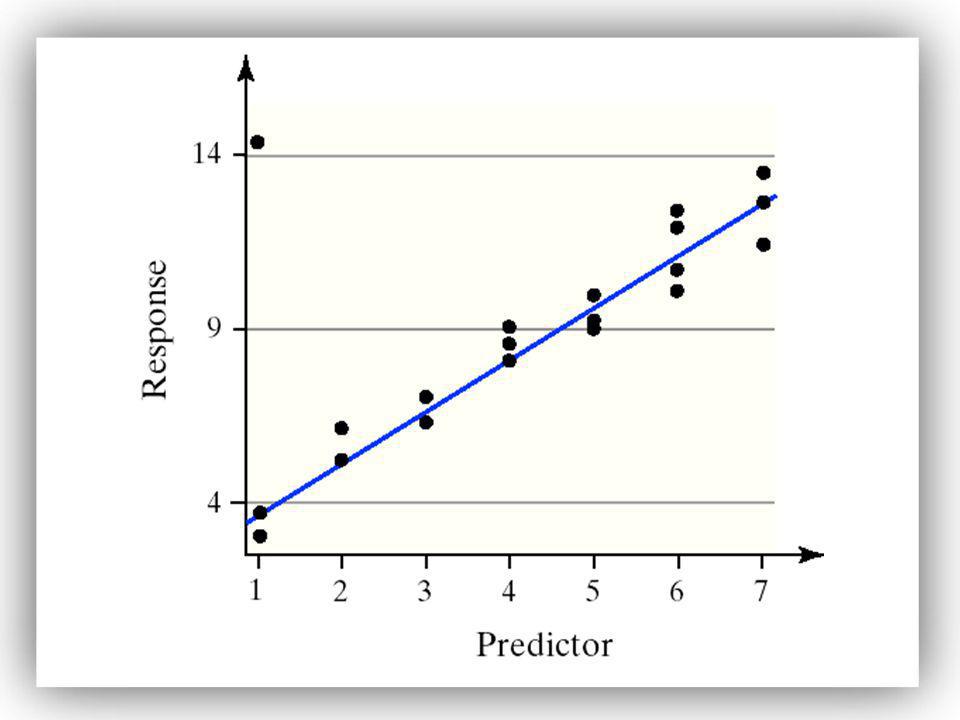
To determine R2 for the linear regression model simply square the value of the linear correlation coefficient.

21
EXAMPLE Determining the Coefficient of Determination
Find and interpret the coefficient of determination for the drilling data.

22
EXAMPLE Determining the Coefficient of Determination
Find and interpret the coefficient of determination for the drilling data. Because the linear correlation coefficient, r, is 0.773, we have that R2 = = = 59.75%. So, 59.75% of the variability in drilling time is explained by the least-squares regression line.

23
Draw a scatter diagram for each of these data sets
Draw a scatter diagram for each of these data sets. For each data set, the variance of y is

24
Data Set A, R2 = 100% Data Set B, R2 = 94.7% Data Set C, R2 = 9.4%

25
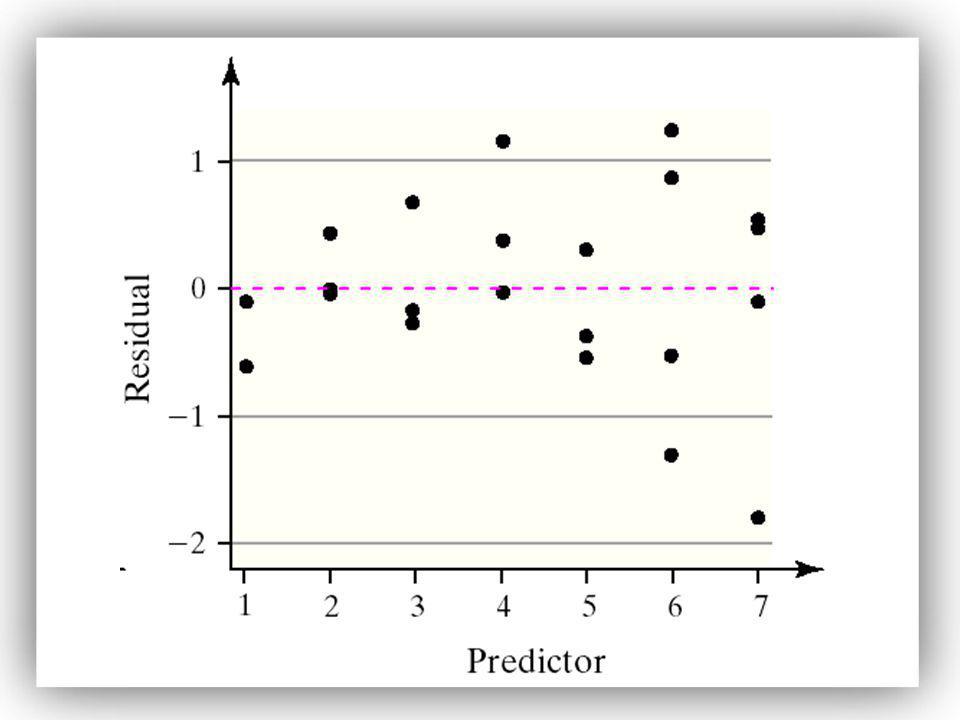
Residuals play an important role in determining the adequacy of the linear model. In fact, residuals can be used for the following purposes: To determine whether a linear model is appropriate to describe the relation between the predictor and response variables. To determine whether the variance of the residuals is constant. To check for outliers.

26
If a plot of the residuals against the predictor variable shows a discernable pattern, such as curved, then the response and predictor variable may not be linearly related.

29
A chemist as a 1000-gram sample of a radioactive material
A chemist as a 1000-gram sample of a radioactive material. She records the amount of radioactive material remaining in the sample every day for a week and obtains the following data. Day Weight (in grams)
")
30
Linear correlation coefficient: -0.994

32
Linear model not appropriate

33
If a plot of the residuals against the predictor variable shows the spread of the residuals increasing or decreasing as the predictor increases, then a strict requirement of the linear model is violated. This requirement is called constant error variance. The statistical term for constant error variance is homoscedasticity

36
A plot of residuals against the predictor variable may also reveal outliers. These values will be easy to identify because the residual will lie far from the rest of the plot.

38
-5

39
We can also use a boxplot of residuals to identify outliers.

40
EXAMPLE Residual Analysis
Draw a residual plot of the drilling time data. Comment on the appropriateness of the linear least-squares regression model.

42
Boxplot of Residuals for the Drilling Data

43
An influential observation is one that has a disproportionate affect on the value of the slope and y-intercept in the least-squares regression equation.

44
Case 2 Case 1 (outlier) Case 3 (influential) Influential observations typically exist when the point is large relative to its X value.
 Case 3 (influential) Influential observations typically exist when the point is large relative to its X value.")
45
EXAMPLE Influential Observations
Suppose an additional data point is added to the drilling data. At a depth of 300 feet, it took minutes to drill 5 feet. Is this point influential?

48
With influential Without influential

49
As with outliers, influential observations should be removed only if there is justification to do so. When an influential observation occurs in a data set and its removal is not warranted, there are two courses of action: (1) Collect more data so that additional points near the influential observation are obtained, or (2) Use techniques that reduce the influence of the influential observation (such as a transformation or different method of estimation - e.g. minimize absolute deviations).
 Collect more data so that additional points near the influential observation are obtained, or. (2) Use techniques that reduce the influence of the influential observation (such as a transformation or different method of estimation - e.g. minimize absolute deviations).")
50
Chapter Four Describing the Relation Between Two Variables
Section 4.4 Nonlinear Regression: Transformations

54
EXAMPLE Using the Definition of a Logarithm
Rewrite the logarithmic expressions to an equivalent expression involving an exponent. Rewrite the exponential expressions to an equivalent logarithmic expression. (a) log315 = a (b) 45 = z
 log315 = a (b) 45 = z.")
55
loga (MN) = loga M + loga N
In the following properties, M, N, and a are positive real numbers, with a 1, and r is any real number. loga (MN) = loga M + loga N loga Mr = r loga M
 = loga M + loga N. loga Mr = r loga M.")
56
EXAMPLE Simplifying Logarithms
Write the following logarithms as the sum of logarithms. Express exponents as factors. (a) log2 x4 (b) log5(a4b)
 log2 x4 (b) log5(a4b)")
57
If a = 10 in the expression y = logax, the resulting logarithm, y = log10x is called the common logarithm. It is common practice to omit the base, a, when it is equal to 10 and write the common logarithm as y = log x

58
EXAMPLE Evaluating Exponential and Logarithmic Expressions
Evaluate the following expressions. Round your answers to three decimal places. (a) log 23 (b) 102.6
 log 23 (b)")
59
Y = A + B x where y = abx Exponential Model
log y = log (abx) Take the common logarithm of both sides log y = log a + log bx log y = log a + x log b Y = A + B x where b = 10B a = 10A
 Take the common logarithm of both sides. log y = log a + log bx. log y = log a + x log b. Y = A + B x where. b = 10B a = 10A.")
60
EXAMPLE 4 Finding the Curve of Best Fit to an Exponential Model
Day Weight (in grams) A chemist as a 1000-gram sample of a radioactive material. She records the amount of radioactive material remaining in the sample every day for a week and obtains the following data.
 A chemist as a 1000-gram sample of a radioactive material. She records the amount of radioactive material remaining in the sample every day for a week and obtains the following data.")
61
(a) Draw a scatter diagram of the data treating the day, x, as the predictor variable.
(b) Determine Y = log y and draw a scatter diagram treating the day, x, as the predictor variable and Y = log y as the response variable. Comment on the shape of the scatter diagram. (c) Find the least-squares regression line of the transformed data. (d) Determine the exponential equation of best fit and graph it on the scatter diagram obtained in part (a). (e) Use the exponential equation of best fit to predict the amount of radioactive material is left after 8 days.
 Determine Y = log y and draw a scatter diagram treating the day, x, as the predictor variable and Y = log y as the response variable. Comment on the shape of the scatter diagram. (c) Find the least-squares regression line of the transformed data. (d) Determine the exponential equation of best fit and graph it on the scatter diagram obtained in part (a). (e) Use the exponential equation of best fit to predict the amount of radioactive material is left after 8 days.")
64
y = axb Power Model log y = log (axb) Take the common logarithm of both sides log y = log a + log xb log y = log a + b log x Y = A + b X where a = 10A

65
EXAMPLE Finding the Curve of Best Fit to a Power Model
Distance Intensity Cathy wishes to measure the relation between a light bulb’s intensity and the distance from some light source. She measures a 40-watt light bulb’s intensity 1 meter from the bulb and at 0.1-meter intervals up to 2 meters from the bulb and obtains the following data.

66
(a) Draw a scatter diagram of the data treating the distance, x, as the predictor variable.
(b) Determine X = log x and Y = log y and draw a scatter diagram treating the day, X = log x, as the predictor variable and Y = log y as the response variable. Comment on the shape of the scatter diagram. (c) Find the least-squares regression line of the transformed data. (d) Determine the power equation of best fit and graph it on the scatter diagram obtained in part (a). (e) Use the power equation of best fit to predict the intensity of the light if you stand 2.3 meters away from the bulb.
 Determine X = log x and Y = log y and draw a scatter diagram treating the day, X = log x, as the predictor variable and Y = log y as the response variable. Comment on the shape of the scatter diagram. (c) Find the least-squares regression line of the transformed data. (d) Determine the power equation of best fit and graph it on the scatter diagram obtained in part (a). (e) Use the power equation of best fit to predict the intensity of the light if you stand 2.3 meters away from the bulb.")
69
Modeling is not only a science but also an art form
Modeling is not only a science but also an art form. Selecting an appropriate model requires experience and skill in the field in which you are modeling. For example, knowledge of economics is imperative when trying to determine a model to predict unemployment. The main reason for this is that there are theories in the field that can help the modeler to select appropriate relations and variables.

Similar presentations