Download presentation
Presentation is loading. Please wait.

1
The Marginal Utility of Income Richard Layard* Guy Mayraz* Steve Nickell** * CEP, London School of Economics ** Nuffield College, Oxford

2
The marginal utility of income is a central concept in public economics The rate at which it declines is a very important number Given a CRRA utility function: the parameter ρ (the coefficient of risk aversion) is a measure of this rate of decline. Our purpose is to estimate ρ Goal

3
Our method is very simple. First, treat answers (on a 1-10 scale) to the question Taking all things into account, how happy are you these day? as a measure of utility. Second, relate these answers to income in a cross-section or time-series analysis, and estimate the relevant parameters. Of course, the basic problem is how to persuade people that this procedure generates the parameters of interest. Method
 to the question Taking all things into account, how happy are you these day. as a measure of utility. Second, relate these answers to income in a cross-section or time-series analysis, and estimate the relevant parameters. Of course, the basic problem is how to persuade people that this procedure generates the parameters of interest. Method.")
4
Alternative Methods Our method is based on attempting to measure ex-post experienced utility, which is what is required in this context. Alternative methods of estimating are based on studies of behaviour. a)choice under uncertainty or b) intertemporal choice. Behaviour is assumed to be based on a decision function involving the weighted addition of ex-ante decision utility in different states or future time periods.
choice under uncertainty or b) intertemporal choice. Behaviour is assumed to be based on a decision function involving the weighted addition of ex-ante decision utility in different states or future time periods..")
5
Problems with Alternative Methods Ex-ante decision utility often turns out to be systematically different from ex-post experienced utility. These methods involve dubious extraneous assumptions eg. Intertemporal additivity or expected utility maximization. Not surprisingly, they yield a very wide range of estimates of ρ - eg. Those based on choice under uncertainty range from 0 to 10.

6
First, the use of overall judgment type questions (i.e. how happy or satisfied are you, all things considered?) may be questioned. The day reconstruction method (DRM) is an alternative (DRM involves dividing a day into episodes and in each, provide a rating on happiness, worry, frustration, etc. Then aggregate these into a combined score). Each has advantages and disadvantages. The measure we use is consistent with other meaningful measures of utility. Measuring utility
 may be questioned. The day reconstruction method (DRM) is an alternative (DRM involves dividing a day into episodes and in each, provide a rating on happiness, worry, frustration, etc. Then aggregate these into a combined score). Each has advantages and disadvantages. The measure we use is consistent with other meaningful measures of utility. Measuring utility.")
7
Second, what is the relationship between reported happiness, h, and true utility, u ? Normalising u so that 0 is the bottom level (extremely unhappy) and 10 is the top level (extremely happy), suppose h=f(u). Assume f>0. Now consider three possibilities: True utility and reported happiness
 and 10 is the top level (extremely happy), suppose h=f(u). Assume f>0. Now consider three possibilities: True utility and reported happiness.")
8
Each individual has their own idiosyncratic interpretation of the scale. Thus the replies are not comparable: h i = f i (u i ) If true, it is hard to see how cross-sections yield rather precise relationships between h and variables such as income, employment status etc. Also, it is hard to see how, when person dummies are introduced into panel data (thus concentrating on time-series variation for each person), one obtains results which are similar to those generated by a cross-section. The relationship between u and h First possibility
 If true, it is hard to see how cross-sections yield rather precise relationships between h and variables such as income, employment status etc. Also, it is hard to see how, when person dummies are introduced into panel data (thus concentrating on time-series variation for each person), one obtains results which are similar to those generated by a cross-section. The relationship between u and h First possibility.")
9
Individuals use the scale in the same way, but potentially it reflects some non linear transformation of true utility: h i = f(u i ) The relationship between u and h Second possibility Third possibility We investigate this, but initially we assume the third possibility. h i = u i Same linear scale:

10
Data We use happiness scores or life satisfaction scores. We renormalise, if necessary, onto a 0-10 scale. If a survey contains both, we average. The income variable is total real household income, not equivalised, and sample members are restricted to those aged 30-55.

11
Reported happiness histogram

12
Data (cont.) We use multiple years of four cross-section surveys: –The US General Social Survey (GSS) –European Social Survey (ESS) –European Quality of Life Survey (EQLS) –World Values Survey (WVS) In addition we use two panel surveys: –German Socio-Economic Panel (GSOEP) –British Household Panel Survey (BHPS)
 We use multiple years of four cross-section surveys: –The US General Social Survey (GSS) –European Social Survey (ESS) –European Quality of Life Survey (EQLS) –World Values Survey (WVS) In addition we use two panel surveys: –German Socio-Economic Panel (GSOEP) –British Household Panel Survey (BHPS)")
13
Data (cont.) Because we are estimating a direct utility function, we must include an hours of work variable. In addition we include standard controls: –Sex –Age (years + quadratic) –Education (years + quadratic or attainment level dummies) –Marital status dummies –Employment status dummies –Country Dummies –Year dummies
 –Education (years + quadratic or attainment level dummies) –Marital status dummies –Employment status dummies –Country Dummies –Year dummies.")
14
Strategy Maintained model

15
Strategy (cont.) Assuming h it = u it –Cross-section analysis (assuming ρ=1) –Panel analysis (assuming ρ=1) –Estimation of ρ Investigation of the form of f
 Assuming h it = u it –Cross-section analysis (assuming ρ=1) –Panel analysis (assuming ρ=1) –Estimation of ρ Investigation of the form of f")
16
Fig. 2: The simple cross-sectional relationship between reported happiness and income in the US General Social Survey.

17
h vs. log y in cross-sections The result is that reported happiness is approximately linear in log income. Subjects with extreme incomes (5% on either side) deviate from general relationship, but this may reflect yearly blips or measurement problems. If we exclude observations with sharp change in reported income, the remaining observations fit the linear relationship well. However, introducing a quadratic term suggests a further degree of concavity. Panel analysis with fixed effects yields similar results.
 deviate from general relationship, but this may reflect yearly blips or measurement problems. If we exclude observations with sharp change in reported income, the remaining observations fit the linear relationship well. However, introducing a quadratic term suggests a further degree of concavity. Panel analysis with fixed effects yields similar results..")
18
Fig. 3: The partial relationship between reported happiness (y-axis) and log income (x-axis). FE indicates person fixed-effects were included in the regression. The graphs show a consistent near-linear relationship, with some variation in the slopes.

20
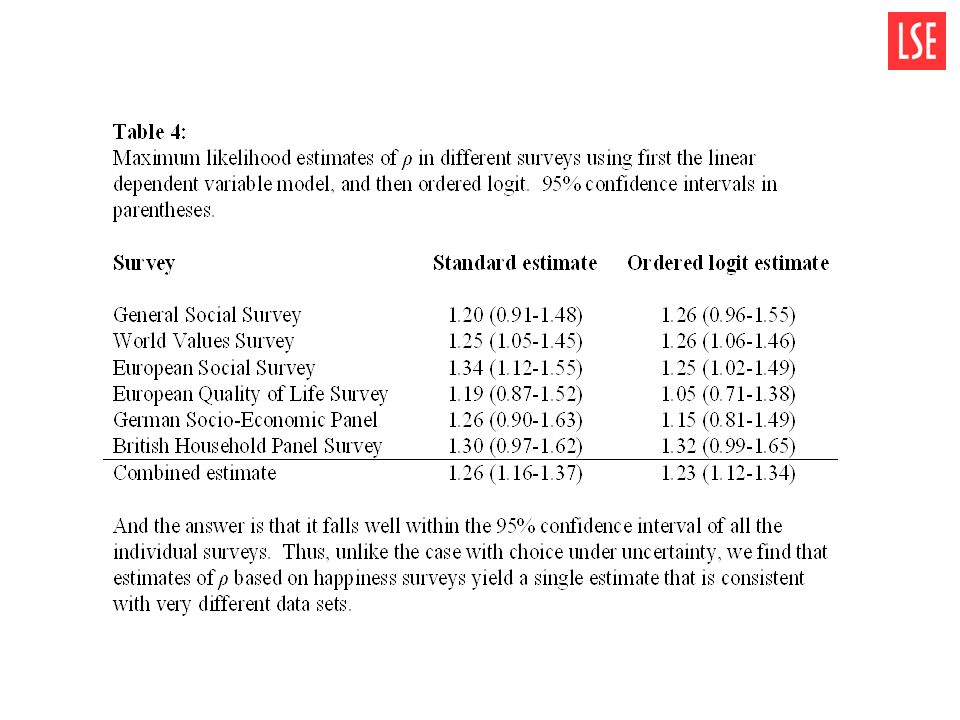
Estimating ρ Reported happiness is modelled as linear in a CRRA function with parameter ρ (see eq. 7) We plot the log likelihood of the observations as a function of ρ. We combine the datasets to produce the overall maximum likelihood estimate of ρ. MLE is ρ = 1.26.
 We plot the log likelihood of the observations as a function of ρ. We combine the datasets to produce the overall maximum likelihood estimate of ρ. MLE is ρ =")
23
Non-linearity of the h-u relationship Our results indicate that, under the assumption that h=u, the estimate of ρ is 1.26. This will be an over-estimate if and f>0, f<0, because true utility is then a convex function of reported utility. So, true utility will be a less concave function of income than reported utility.

24
Non-linearity of the h-u relationship Indeed, in theory this effect could be so large that true utility could even be convex in income. How can we investigate the curvature of f ? We focus on the equation

25
The shape of ƒ(u), I We use three methods. (i)Ordered Logit. The ordered logit estimate of ρ is 1.23. The cut points are slightly curved, consistent with slight curvature of ƒ. This method relies on the assumption that ε has a symmetric distribution.

26
Fig. 4: Evidence for the concavity of h = f(u) using the German Socio-Economic panel. (i) The top left panel
 The top left panel.")
27
The shape of ƒ(u), II (ii)Variance of the Residuals. Assume true utility, u, has a scale with a constant standard error for test-retest mistakes. Reported happiness, һ, has variable units proportional to measured standard errors based on repeated observations on same person in GSOEP.

28
The shape of ƒ(u), III Estimate Subst. (2) into (1) and integrate Plotted in bottom left panel in Fig. 4. Use this to correct ρ. After correction, ρ = 1.24.
 into (1) and integrate Plotted in bottom left panel in Fig. 4. Use this to correct ρ. After correction, ρ =")
29
The shape of ƒ(u), IV (iii)The Spline Test. If ƒ is concave, if we combine the regressors into a single prediction variable,, by running a linear regression and then run separate regressions of reported happiness on the prediction variable in each half of the sample, the slope should be higher for low values of than for high values of This can be used to compute a measure of the curvature of ƒ. The corrected measure of ρ is 1.25.

30
Conclusions 1.We have estimated the elasticity of marginal utility of income with respect to income (ρ) based on measure of experienced utility. 2.We have used six different surveys. 3.We have attempted to investigate the extent to which the results are distorted because reported happiness is non-linear function of true utility. 4.Under our assumptions, ρ is around 1.24.

Similar presentations







 Inferences from multiple regression analysis.>")














