Download presentation
Presentation is loading. Please wait.

1
Naive Bayes (Generative Classifier) vs. Logistic Regression (Discriminative Classifier) 2008. 2. 19. Minkyoung Kim

2
Contents 1.Naive Bayes Classifier 1.Supervised Learning based on Bayes Rule (Impractical) 2.Conditionally Independence 3.Naive Bayes Classifier: Discrete-Valued Input 4.Naive Bayes Classifier: Continuous-Valued Input (GNB) 2.Logistic Regression 1.Supervised Learning using a parametric model 2.Logistic Regression from GNB 3.Regularization in Logistic Regression 3.Naive Bayes Classifier vs. Logistic Regression

3
Naive Bayes classifier

4
Supervised Learning Training Examples Supervised Learning Target Function SampleAnswer

6
Learning based on Bayes Rule Training Examples Supervised Learning Target Function SampleAnswer Bayes Rule Likelihood Prior

7
XYSum RuleTotal # of Params for estimating P(X|Y) of Bayes When Let’s count the number of parameters of Impractical!
 of Bayes When Let’s count the number of parameters of Impractical!")
10
XiXi YSum RuleTotal # of Params for estimating P(X|Y) of Naive Bayes When Let’s count the number of parameters of
 of Naive Bayes When Let’s count the number of parameters of")
11
Naive Bayes Algorithm When Bayes Conditional Independence Naive Bayes Naive Bayes classifier Then, the most probable value of Y (Answer) is Since the denominator does not depend on y k, simply ① likelihood ② prior
 is Since the denominator does not depend on y k, simply ① likelihood ② prior")
12
Naive Bayes for Discrete-Valued Input When ① Likelihood Let’s count the number of parameters of XiXi YSum RuleTotal ② Prior Let’s count the number of parameters of YSum RuleTotal

13
Training: Maximum likelihood estimates (relative frequencies) ① Likelihood smoothing ② Prior smoothing
 ① Likelihood smoothing ② Prior smoothing")
14
Naive Bayes for Continuous Input - Gaussian Naive Bayes classifier When ① Likelihood In order to train likelihood, we must estimate the mean and standard deviation. 1.Gaussian: X i is generated by a mixture of class-conditional Gaussian (i.e. dependent on the value of the class variable Y) 2.Naive Bayes: The attribute values X i are conditionally independent of one another. Total ② Prior Total
 2.Naive Bayes: The attribute values X i are conditionally independent of one another. Total ② Prior Total.")
15
Training: Maximum likelihood estimates (relative frequencies) ① Likelihood ② Prior smoothing : training examples in the case of Minimum variance unbiased estimator (MVUE)
 ① Likelihood ② Prior smoothing : training examples in the case of Minimum variance unbiased estimator (MVUE)")
16
Logistic Regression

17
Supervised Learning using a parametric model Training Examples Supervised Learning Target Function SampleAnswer Bayes Rule Params

18
Logistic Regression for Boolean Label When ① Parametric model (logistic function) ② We assign the label, if, and assigns, otherwise. This leads to a simple linear expression for classification!

19
Logistic Regression from GNB

20
Logistic Regression from GNB Conditional Independence Bayes Naive Bayes

21
Logistic Regression from GNB Gaussian

22
Logistic Regression from GNB GNB, where, Also we have Thus,

23
Training: Choosing W that maximize the conditional data log likelihood We choose parameters W that satisfy Equivalently, we can work with the log of the conditional likelihood:

24
Training: Choosing W that maximize the conditional data log likelihood Here, we introduce the logistic model Then,

25
Training: Choosing W that maximize the conditional data log likelihood Prediction error: we want this to be zero! Predicted prob. Responsibility for this prediction Observed Y l

26
Training: Gradient ascent rule to optimize the weights W Step 1: Step 2: For all training examples, repeatedly update the weights in the direction of the gradient,, where : step size : lth training example Because the conditional log likelihood is a concave function in W, this gradient ascent procedure will converge to a global maximum.

27
Regularization in Logistic Regression Overfitting problem especially when data is very high dimensional and training data is sparse. One approach to reducing overfitting is regularization in which we create a modified “penalized log likelihood function”, which penalizes large values of W., where : strength of penalty The derivative of this penalized log likelihood function,

28
Regularization in Logistic Regression The penalty term can be interpreted as the result of imposing a Normal prior on W, with zero mean, and whose variance is related to 1/λ.

29
Training: Modified gradient ascent rule to optimize the weights W Step 1: Step 2: Repeatedly update the weights in the direction of the gradient,, where : step size Because the conditional log likelihood is a concave function in W, this gradient ascent procedure will converge to a global maximum.

30
Logistic Regression for Discrete Label When ① Parametric model (logistic function) ② Gradient descent rule with regularization, Previous case is a special case of this new learning rule, when K=2.
 ② Gradient descent rule with regularization, Previous case is a special case of this new learning rule, when K=2.")
31
Naive Bayes classifier vs. Logistic Regression

32
Naive Bayes Classifier vs. Logistic Regression (Naive) Bayes ClassifierLogistic Regression Nick name Generative classifier: We can view the distribution P(X|Y) as describing how to generate random instances X conditioned on the target attribute Y. Discriminative classifier: We can view the distribution P(Y|X) as directly discriminating the value of the target value Y for any given instance X. Assumpti on Naive Bayes classifier: all attributes of X are conditionally independent given Y. ⇒ reduces # of params dramatically Function approximation with logistic function y=1/(1+exp(-x)) Choice GNB = LR when l →∞, provided the Naive Bayes assumptions hold. GNB converges in order logn, whereas LR does in order n. GNB outperforms LR when training data is scarce, vice versa. NB has greater bias but lower variance than LR.
 Bayes ClassifierLogistic Regression Nick name Generative classifier: We can view the distribution P(X|Y) as describing how to generate random instances X conditioned on the target attribute Y. Discriminative classifier: We can view the distribution P(Y|X) as directly discriminating the value of the target value Y for any given instance X. Assumpti on Naive Bayes classifier: all attributes of X are conditionally independent given Y. ⇒ reduces # of params dramatically Function approximation with logistic function y=1/(1+exp(-x)) Choice GNB = LR when l →∞, provided the Naive Bayes assumptions hold. GNB converges in order logn, whereas LR does in order n. GNB outperforms LR when training data is scarce, vice versa. NB has greater bias but lower variance than LR..")
Similar presentations

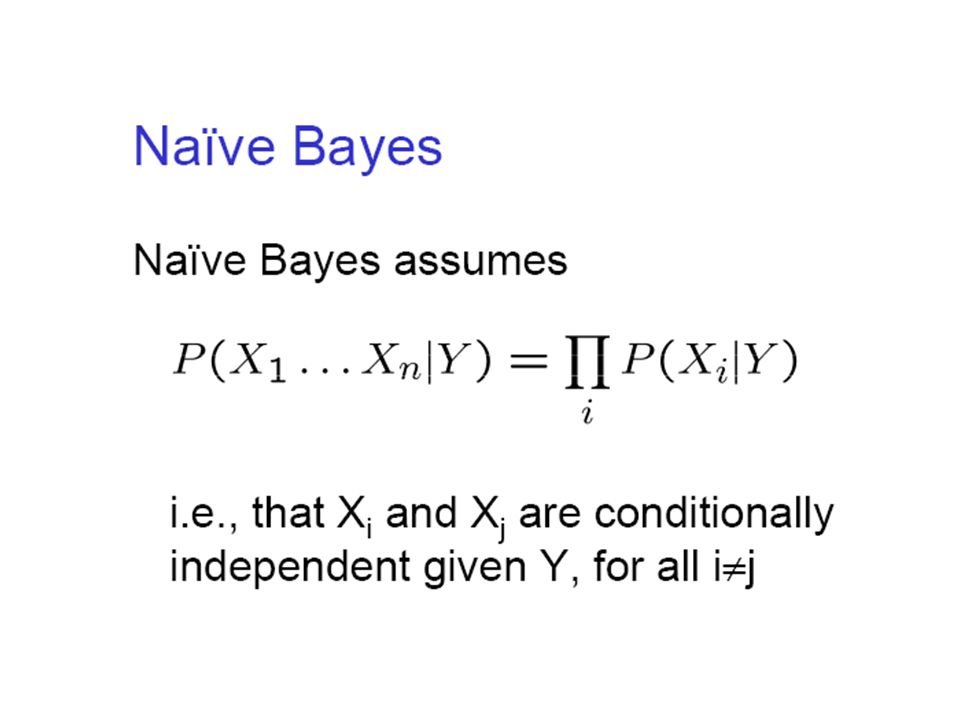





, take home, turn in at noon time of 03/02 (Friday)>")





 Project proposal is due on 03/02.>")

 Female: Gaussian distribution N(>")


>")



