Download presentation
Presentation is loading. Please wait.

1
Big Data Yuan Xue (yuan.xue@vanderbilt.edu) CS 292 Special topics on

2
Part II NoSQL Database (Overview) Yuan Xue (yuan.xue@vanderbilt.edu)
 Yuan Xue")
3
Outline From SQL to NoSQL Motivation Challenges Approaches Notable NoSQL systems Database User/Application Developer: How to use? (Logic) data model and CRUD operations Database System Designer: How to design? Under the hood: (Physical) data model and distribution algorithm Database Designer: How to link application needs with database design Schema design Summary and Moving forward Summary of NoSQL Data Modeling Techniques Summary of NoSQL Data Distribution Models/Algorithms Limits of NoSQL NewSQL Data Model Column Family Key-value Document
 data model and CRUD operations Database System Designer: How to design. Under the hood: (Physical) data model and distribution algorithm Database Designer: How to link application needs with database design Schema design Summary and Moving forward Summary of NoSQL Data Modeling Techniques Summary of NoSQL Data Distribution Models/Algorithms Limits of NoSQL NewSQL Data Model Column Family Key-value Document.")
4
From SQL to NoSQL Relational Database Review Persistent data storage Transaction support ACID Concurrency control + recovery Standard data interface for data sharing SQL Conceptual Design Data model mapping Entity/Relationship model Logic Design Logical Schema] Normalization Normalized Schema Physical Design Physical (Internal) Schema DesignOperation SQL query
![From SQL to NoSQL Relational Database Review Persistent data storage Transaction support ACID Concurrency control + recovery Standard data interface for data sharing SQL Conceptual Design Data model mapping Entity/Relationship model Logic Design Logical Schema] Normalization Normalized Schema Physical Design Physical (Internal) Schema DesignOperation SQL query](http://images.slideplayer.com/37/10744422/slides/slide_4.jpg "From SQL to NoSQL Relational Database Review Persistent data storage Transaction support ACID Concurrency control + recovery Standard data interface for data sharing SQL Conceptual Design Data model mapping Entity/Relationship model Logic Design Logical Schema] Normalization Normalized Schema Physical Design Physical (Internal) Schema DesignOperation SQL query")
5
Meta-data SQL Review -- Putting Things Together Application Program/Queries Users Query Processing Data access (Database Engine) Data DBMS system http://www.dbinfoblog.com/post/24/the-query-processor/
 Data DBMS system")
6
From SQL to NoSQL Motivation I Scaling (up/out) SQL database Web-based application with SQL database as backend High Web traffic large volume of transactions More users large amount of data Solution 1: cache E.g. memcached, Only handle read traffic Solution 2: Scale up (vertically) Add more resources to a single node Solution 3: Scale out (horizontally) Add more nodes to the DB system Data distribution among multiple nodes non-trivial
 Add more resources to a single node Solution 3: Scale out (horizontally) Add more nodes to the DB system Data distribution among multiple nodes non-trivial.")
7
Scale out SQL database – Techniques and Challenges Two Techniques Replication Sharding Replication Master-Slave All writes are written to the master All reads performed against the replicated slave databases Critical reads may be incorrect as writes may not have been propagated down Large data sets can pose problems as master needs to duplicate data to slaves Peer-to-peer Writes can happen at any nodes Inconsistent write (which can be persistent) Sharding (Partition the dataset to multiple nodes) Scales well for both reads and writes Not transparent, application needs to be partition-aware Can no longer have relationships/joins across partitions Loss of referential integrity across shards Duplication facilitates read Data consistency problem arises Partition facilitates write/read lost transaction support across partition SQL and multi-node cluster do not go well
 Sharding (Partition the dataset to multiple nodes) Scales well for both reads and writes Not transparent, application needs to be partition-aware Can no longer have relationships/joins across partitions Loss of referential integrity across shards Duplication facilitates read Data consistency problem arises Partition facilitates write/read lost transaction support across partition SQL and multi-node cluster do not go well")
8
From SQL to NoSQL Motivation II Limits in Relational Data Model Impedance Mismatch Difference between in-memory data structures and relational model Predefined schema Join operation Not appropriate for Graph data Geographical data Unstructured data

9
From SQL to NoSQL Google: Search Engine Store billions document Bigtable + Google File System Amazon: Online Shopping Shopping cart management dynamo Foundation Open source DBMS Cloud-hosted managed DBMS Amazon DynamoDB Amazon SimpleDB … HBase + HDFS Cassandra Riak Redis MongoDB … Supported by many social media sites with large data needs facebook twitter Utilized by companies imdb startups..

10
What is NoSQL Stands for Not Only SQL: Not relational database Umbrella term for many different types of data stores (database) Different Types of Data Model Key va lue DB, Column Family DB Document DB Graph DB Just as there are different programming languages, NoSQL provides different data storage tools in the toolbox Polyglot Persistence
 Different Types of Data Model Key va lue DB, Column Family DB Document DB Graph DB Just as there are different programming languages, NoSQL provides different data storage tools in the toolbox Polyglot Persistence")
11
What is the Magic? Logic Data Model: From Table to Aggregate Diverse data models Column Family Key-value Document Graph No schema predefined allows an attribute/field to be added at run-time Still need to consider how to define “key” “column family” Giving up build-in Joins Physical Data Handling: From ACID to BASE (CAP theorem coming up) No full transaction support Support at Aggregate level Support both replication and sharding (automatically) Relax one or more of the ACID properties Aggregate
 No full transaction support Support at Aggregate level Support both replication and sharding (automatically) Relax one or more of the ACID properties Aggregate.")
12
NoSQL Database Classification -- Data Model View Key Value Store Dynamo Riak Redis Memcached (in memory) Column Family Hbase (BigTable) Cassandra Document MongoDB Terrastore Graph FlockDB Neo4J
 Column Family Hbase (BigTable) Cassandra Document MongoDB Terrastore Graph FlockDB Neo4J")
13
Transaction Review ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties that guarantee that database transactions are processed reliably. Atomicity: "all-or-nothing" proposition Each work unit performed in a database must either complete in its entirety or have no effect whatsoever Consistency: database constraints conformation Each client, each transaction, Can assume all constraints hold when transaction begins Must guarantee all constraints hold when transaction ends Isolation: serial equivalency Operations may be interleaved, but execution must be equivalent to some sequential (serial) order of all transactions. Durability: durable storage. If system crashes after transaction commits, all effects of transaction remain in database
 order of all transactions. Durability: durable storage. If system crashes after transaction commits, all effects of transaction remain in database.")
14
ACID and Transaction Support in Distributed Environment Recall -- scaling out database Distributed environment with multiple nodes Data are distributed across nodes via Replication Sharding Concerns from Distributed Networking Environment Message Loss/Delay Network partition Can ACID property still hold for database in distributed environment? CAP theorem comes as a guideline

15
CAP Theorem Start with three properties for distributed systems: Consistency: All nodes see the same data at the same time Availability: Every request to a non- failing node in the system returns a response about whether it was successful or failed. Partition Tolerance: System properties (consistency and/or availability) hold even when the system is partitioned (communicate lost) Consistency Partition tolerance Availability
 hold even when the system is partitioned (communicate lost) Consistency Partition tolerance Availability.")
16
CAP Theorem Consistency – Atomic data object Consistency Partition tolerance Availability As in ACID 1.In a distributed environment, multiple copies of a data item may exist on different nodes. 2.Consistency requires that all operations towards a data item are executed as if they are performed over a single instant Data item X Copy 1 Data item X Copy 2 Clients Data item X

17
CAP Theorem Availability – Available data object Requests to data -- Read/write, always succeed. 1.All (non-failing ) nodes remain able to read and write even when network is partitioned. 2.A system that keeps some, but not all, of its nodes able to read and write is not Available in the CAPsense, even if it remains available to clients and satisfies its SLAs for high availalbility Consistency Partition tolerance Availability Reference: https://foundationdb.com/white-papers/the-cap-theorem
 nodes remain able to read and write even when network is partitioned. 2.A system that keeps some, but not all, of its nodes able to read and write is not Available in the CAPsense, even if it remains available to clients and satisfies its SLAs for high availalbility Consistency Partition tolerance Availability Reference:")
18
CAP Theorem Partition Tolerance Consistency Partition tolerance Availability 1.The network will be allowed to lose arbitrarily many messages sent from one node to another. 2.When network is partitioned, all messages from one component to another will get lost. Under Partition Tolerance Consistency requirement implies that every data operation will be atomic, even though arbitrary messages may get lost. Availability requirement implies that every nodes receiving a request from a client must respond, even though arbitrary messages may get lost.

19
CAP Theorem You can have at most two of these three properties for any shared-data system Consistency, availability and partition tolerance To scale out, you have to support partition tolerant NoSQL: either consistency or availability to choose from under network partition Consistency Partition tolerance Availability Pick one side NoSQL SQL

20
NoSQL Database Classification -- View from CAP Theorem ConsistencyPartition tolerance Availability Relational: MySQL, PostgreSQL Relational: MySQL BigTable and its derivatives: HBase, Redis, MongoDB Dynamo and its derivatives: Cassandra, Riak

21
More on Consistency Question: in AP system, if consistency property can not be hold, what property can be claimed? Example Data item X is replicated on nodes M and N Client A writes X to node N Some period of time t elapses. Client B reads X from node M Does client B see the write from client A? From client’s perspective, two kinds of consistency: Strong consistency (as C in CAP): any subsequent access is guaranteed to return the updated value Weak consistency: subsequent access is not guaranteed to return the updated value Inconsistency window: The period between the update and the moment when it is guaranteed that any observer will always see the updated value Consistency is a continuum with tradeoffs Multiple consistency models Client A write read Data item X Copy 1 Data item X Copy 2 MN Client B
: any subsequent access is guaranteed to return the updated value Weak consistency: subsequent access is not guaranteed to return the updated value Inconsistency window: The period between the update and the moment when it is guaranteed that any observer will always see the updated value Consistency is a continuum with tradeoffs Multiple consistency models Client A write read Data item X Copy 1 Data item X Copy 2 MN Client B.")
22
Eventual Consistency Eventual consistency a specific form of weak consistency When no updates occur for a long period of time, eventually all updates will propagate through the system and all the nodes will be consistent all accesses will return the last updated value. For a given accepted update and a given node, eventually either the update reaches the node or the node is removed from service Based on CAP SQL NoSQL ACID BASE (Basically Available, Soft state, Eventual consistency) Basically Available - system seems to work all the time Soft State - it doesn't have to be consistent all the time Eventually Consistent - becomes consistent at some later time
 Basically Available - system seems to work all the time Soft State - it doesn t have to be consistent all the time Eventually Consistent - becomes consistent at some later time.")
23
References and Additional Reading for CAP http://en.wikipedia.org/wiki/CAP_theorem http://en.wikipedia.org/wiki/CAP_theorem Formal proof for CAP theorem: Brewer's Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services by Seth Gilbert and Nancy LynchBrewer's Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services by Seth Gilbert and Nancy Lynch Graphical illustration of CAP theorem: http://www.julianbrowne.com/article/viewer/brewers-cap-theorem http://www.julianbrowne.com/article/viewer/brewers-cap-theorem Recent post from Brewer: CAP Twelve Years Later: How the "Rules" Have ChangedCAP Twelve Years Later: How the "Rules" Have Changed Eventually Consistent by Werner VogelsWerner Vogels

24
Part II NoSQL Database (Overview) Yuan Xue (yuan.xue@vanderbilt.edu)
 Yuan Xue")
25
BigTable and Hbase

26
Introduction BigTable Background Development began in 2004 at Google (published 2006) need to store/handle large amounts of (semi)-structured data Many Google projects store data in BigTable Google’s web crawl Google Earth Google Analytics HBase Background open-source implementation of BigTable built on top of HDFS Initial HBase prototype in 2007 Hadoop become Apache top-level project and HBase becomes subproject in 2008
 need to store/handle large amounts of (semi)-structured data Many Google projects store data in BigTable Google’s web crawl Google Earth Google Analytics HBase Background open-source implementation of BigTable built on top of HDFS Initial HBase prototype in 2007 Hadoop become Apache top-level project and HBase becomes subproject in 2008")
27
Road Map Database User/Application Developer: How to use? (Logic) data model and CRUD operations Database System Designer: How to design? Under the hood: (Physical) data model and distribution algorithm Database Designer: How to link application needs with database design Schema design
 data model and CRUD operations Database System Designer: How to design. Under the hood: (Physical) data model and distribution algorithm Database Designer: How to link application needs with database design Schema design.")
28
Data Model A sparse, distributed, persistent multidimensional sorted map Map indexed by a row key, column key, and a timestamp (row:string, column:string, time:int64) uninterpreted byte array Rows maintained in sorted lexicographic order based on row key A row key is an arbitrary string Every read or write of data under a single row is atomic. Row ranges dynamically partitioned into tablets Unit of distribution and load balancing Applications can exploit this property for efficient row scans

29
Data Model A sparse, distributed, persistent multidimensional sorted map Map indexed by a row key, column key, and a timestamp (row:string, column:string, time:int64) uninterpreted byte array Columns grouped into column families Column key = family:qualifier Column family must be created before data can be stored in a column key. Column families provide locality hints Unbounded number of columns

30
Data Model A sparse, distributed, persistent multidimensional sorted map Map indexed by a row key, column key, and a timestamp (row:string, column:string, time:int64) uninterpreted byte array Timestamps 64 bit integers, Assigned by: Bigtable: real-time in microseconds, Client application: when unique timestamps are a necessity. Items in a cell are stored in decreasing timestamp order. Application specifies how many versions (n) of data items are maintained in a cell. Bigtable garbage collects obsolete versions.
 of data items are maintained in a cell. Bigtable garbage collects obsolete versions..")
31
Data Model – MiniTwitter Example

32
View as a Map of Map

33
Operations & APIs in Hbase Create and delete tables and column families; Modify meta-data Operations are based on row keys Single-row operations: Put Get Delete Multi-row operations: Scan MultiPut Atomic R-M-W sequences on data stored in a single row key (No support for transactions across multiple rows). No built-in joins Can be done in the application Using scan() and get() operations Using MapReduce
 and get() operations Using MapReduce.")
34
Creating a Table HBaseAdmin admin= new HBaseAdmin(config); HColumnDescriptor []column; column= new HColumnDescriptor[2]; column[0]=new HColumnDescriptor("columnFamily1:"); column[1]=new HColumnDescriptor("columnFamily2:"); HTableDescriptor desc= new HTableDescriptor(Bytes.toBytes("MyTable")); desc.addFamily(column[0]); desc.addFamily(column[1]); admin.createTable(desc); 34
![Creating a Table HBaseAdmin admin= new HBaseAdmin(config); HColumnDescriptor []column; column= new HColumnDescriptor[2]; column[0]=new HColumnDescriptor( columnFamily1: ); column[1]=new HColumnDescriptor( columnFamily2: ); HTableDescriptor desc= new HTableDescriptor(Bytes.toBytes( MyTable )); desc.addFamily(column[0]); desc.addFamily(column[1]); admin.createTable(desc); 34](http://images.slideplayer.com/37/10744422/slides/slide_34.jpg "Creating a Table HBaseAdmin admin= new HBaseAdmin(config); HColumnDescriptor []column; column= new HColumnDescriptor[2]; column[0]=new HColumnDescriptor( columnFamily1: ); column[1]=new HColumnDescriptor( columnFamily2: ); HTableDescriptor desc= new HTableDescriptor(Bytes.toBytes( MyTable )); desc.addFamily(column[0]); desc.addFamily(column[1]); admin.createTable(desc); 34")
35
Altering a Table 35 Disable the table before changing the schema

36
Single-row operations: Put() Insert a new record (with a new key), Or Insert a record for an existing key 36 Implicit version number (timestamp) Explicit version number
 Insert a new record (with a new key), Or Insert a record for an existing key 36 Implicit version number (timestamp) Explicit version number")
37
Put() in MiniTwitter
 in MiniTwitter")
38
Update information

39
Single-row operations: Get() Given a key return corresponding record For each value return the highest version 39 Can control the number of versions you want
 Given a key return corresponding record For each value return the highest version 39 Can control the number of versions you want")
40
Get() in MiniTwitter
 in MiniTwitter")
41
Single-row operations: Delete() Marking table cells as deleted Multiple levels Can mark an entire column family as deleted Can make all column families of a given row as deleted 41 Delete d = new Delete(Bytes.toBytes(“rowkey”)); userTable.delete(d); Delete d = new Delete(Bytes.toBytes(“rowkey”)); d.deleteColumns( Bytes.toBytes(“cf”), Bytes.toBytes(“attr”)); userTable.delete(d);
 Marking table cells as deleted Multiple levels Can mark an entire column family as deleted Can make all column families of a given row as deleted 41 Delete d = new Delete(Bytes.toBytes( rowkey )); userTable.delete(d); Delete d = new Delete(Bytes.toBytes( rowkey )); d.deleteColumns( Bytes.toBytes( cf ), Bytes.toBytes( attr )); userTable.delete(d);")
42
Multi-row operations: Scan() 42
 42")
43
Road Map Database User/Application Developer: How to use? (Logic) data model and CRUD operations Database System Designer: How to design? Under the hood: (Physical) data model and distribution algorithm Single Node Write, Read, Delete Distributed System Database Designer: How to link application needs with database design Schema design
 data model and CRUD operations Database System Designer: How to design. Under the hood: (Physical) data model and distribution algorithm Single Node Write, Read, Delete Distributed System Database Designer: How to link application needs with database design Schema design.")
44
Basics Terms BigTableHbase SSTableHFile memtableMemStore tabletregion tablet serverRegionServer

45
HFile/SSTable Basic building block of Bigtable Persistent, ordered immutable map from keys to values Stored in GFS Sequence of blocks on disk plus an index for block lookup Can be completely mapped into memory Supported operations: Look up value associated with key Iterate key/value pairs within a key range Index 64K block SSTable BigTableHbase SSTableHFile memtableMemStore tabletregion tablet serverRegionServer

46
HDFS: Hadoop Distributed File Systems Client requests meta data about a file from namenode Data is served directly from datanode

47
47 File Read/Write in HDFS data node DataNode data node DataNode data node DataNode data node DataNode data node DataNode data node DataNode name node NameNode name node NameNode HDFS client Distributed FileSystem FSData InputStream client node client JVM HDFS client Distributed FileSystem FSData OutputStream client node client JVM File Read File Write 1. create2. create 3. write 5. write packet6. ack packet 7. close 8. complete 1. open 2. get block locations 3. read 6. close 4. read from the closest node 5. read from the 2nd closest node 4. get a list of 3 data nodes If a data node crashed, the crashed node is removed, current block receives a newer id so as to delete the partial data from the crashed node later, and Namenode allocates an another node.

48
Hbase: Logic storage vs Physical storage

49
Region/Tablet Dynamically partitioned range of rows Built from multiple SSTables Column-Family oriented storage Index 64K block SSTable Index 64K block SSTable Tablet Start:Alice00End:Dave11 BigTableHbase SSTableHFile memtableMemStore tabletregion tablet serverRegionServer

50
Table (HTable) Multiple tablets make up the table The entire BigTable is split into tablets of contiguous ranges of rows Approximately 100MB to 200MB each Tablets are split as their size grows SSTables can be shared SSTable Tablet Alice00 Dave11 Tablet Darth Emily Source: Graphic from slides by Erik Paulson BigTableHbase SSTableHFile memtableMemStore tabletregion tablet serverRegionServer Tablet 1 Tablet 2 HTable Each column family is stored in a separate file Key & Version numbers are replicated with each column family Empty cells are not stored
 Multiple tablets make up the table The entire BigTable is split into tablets of contiguous ranges of rows Approximately 100MB to 200MB each Tablets are split as their size grows SSTables can be shared SSTable Tablet Alice00 Dave11 Tablet Darth Emily Source: Graphic from slides by Erik Paulson BigTableHbase SSTableHFile memtableMemStore tabletregion tablet serverRegionServer Tablet 1 Tablet 2 HTable Each column family is stored in a separate file Key & Version numbers are replicated with each column family Empty cells are not stored")
51
Table to Region

52
Physical Storage: MiniTwitter Example HTable

53
Write Path in HBase Hlog (append only WAL on HDFS One per RS)
")
54
Read Path in Hbase

55
Deletion and Compaction in HBase Delete() will mark the record for deletion A new “tombstone” record is written for that value BigTableHbase Merging compaction Minor compaction flush Major compaction
 will mark the record for deletion A new tombstone record is written for that value BigTableHbase Merging compaction Minor compaction flush Major compaction")
56
Announcement Lab 1 Due Lab 2 Release (team up) Project team up Quiz 1 graded
 Project team up Quiz 1 graded")
57
Data Distribution and Serving -- Big Picture 57

58
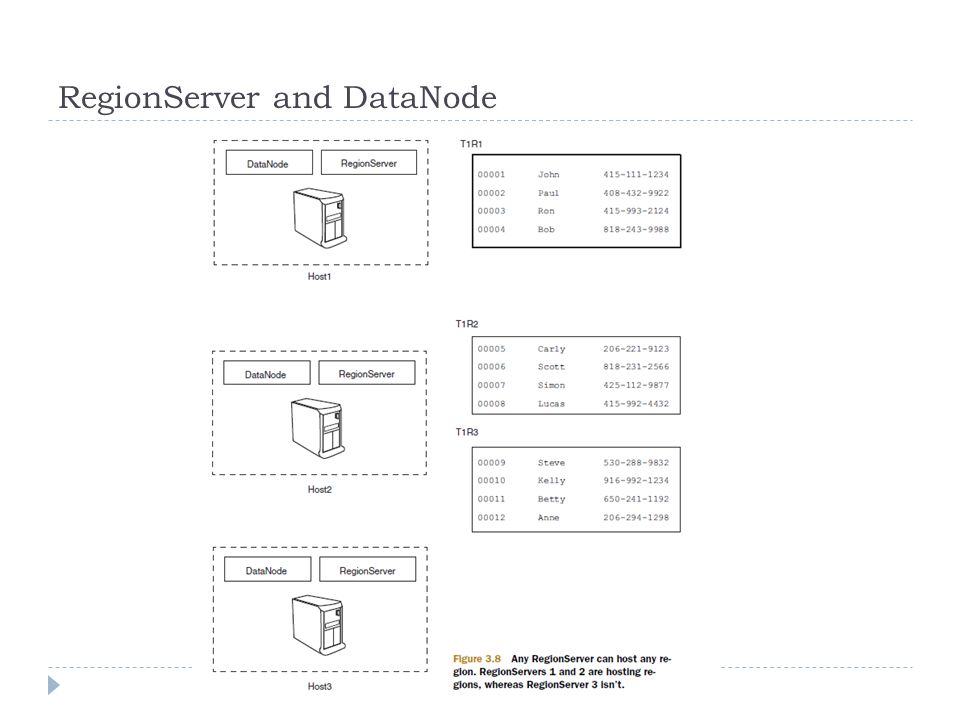
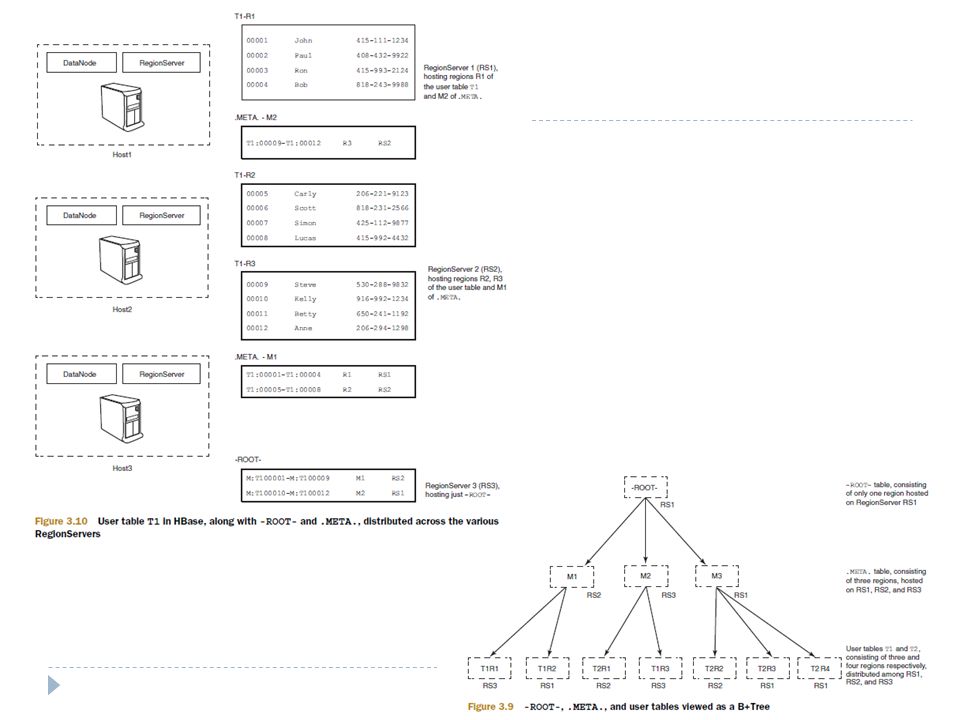
Placement of Tablets and Data Serving A tablet is assigned to one tablet server at a time. Metadata for tablet locations and start/end row are stored in a special Bigtable cell Master maintains: The set of live tablet servers, Current assignment of tablets to tablet servers (including the unassigned ones)
.")
59
RegionServer and DataNode

62
Interacting with Hbase

63
Hbase Schema Design How many column families should the table have? What data goes into what column family? How many columns should be in each column family? What should the column names be? Although column names don’t have to be defined on table creation, you need to know them when you write or read data. What information should go into the cells? How many versions should be stored for each cell? What should the rowkey structure be, and what should it contain?

64
MiniTwitter Review Read operation Whom does TheFakeMT follow? Does TheFakeMT follow TheRealMT? Who follows TheFakeMT? Does TheRealMT follow TheFakeMT? Write operation A user follows someone A user unfollows someone

65
MiniTwitter- Version 1

66
Version 2 Read operation How many people a user follows? Atomic operation!

67
Version 3 Get rid of the counter Problem Row access overhead

68
Version 4 Wide table vs tall table

69
Version 4 – client code

70
Version 5 Trick with hash code

71
Normalization vs Denormalization

72
CourseIDCourseNameHourDescription CS292Special Topics on Big Data3large-scale data processing CS283Computer networks3Networking technology ClassIDCourseIDSemesterInstructorIDClassroomTime 2014CS292CS292S2014xuey1FGH134Tue/Th 1:10-2:25 2014CS283CS283S2014jmattFGH236Tue/Th 1:10-2:25 ClassIDStudentIDGrade 2014CS292balice1NULL Registration ClassSchedule Course VUNetIDFirstNameLastNameEmail xuey1YuanXue Yuan.xue balice1AliceBurch Alice.burch VandyUser

73
ClassIDCourseIDSectionIDSemesterInstructorIDClassroomTime 2014CS29201CS29201S2014xuey1FGH134Tue/Th 1:10-2:25 2014CS283CS28301S2014jmattFGH236Tue/Th 1:10-2:25 ClassSchedule

Similar presentations