Download presentation
Presentation is loading. Please wait.

1
Machine Learning in Practice Lecture 9 Carolyn Penstein Rosé Language Technologies Institute/ Human-Computer Interaction Institute

2
Plan for the Day Announcements Questions? Assignment 4 Quiz Today’s Data Set: Speaker Identification Weka helpful hints Visualizing Errors for Regression Problems Alternative forms of cross-validation Creating Train/Test Pairs Intro to Evaluation

3
Speaker Identification

4
Today’s Data Set – Speaker Identification

5
Preprocessing Speech Record speech to WAV files. Extract a variety of acoustic and prosodic features.

6
Predictions: which algorithm will perform better? What previous data set does this remind you of? J48.53 Kappa SMO.37 Kappa Naïve Bayes.16 Kappa

7
Notice Ranges and Contingencies

8
Most Predictive Feature

9
Least Predictive Feature

10
What would 1R do?

11
.16 Kappa

12
Weka Helpful Hints

13
Evaluating Numeric Prediction: CPU data

14
Visualizing Classifier Errors for Numeric Prediction

15
Creating Train/Test Pairs First click here

16
Creating Train/Test Pairs If you pick unsupervised, you’ll get non-stratified folds, otherwise you’ll get stratified folds.

17
Stratified versus Non-Stratified Weka’s standard cross-validation is stratified Data is randomized before dividing it into folds Preserves distribution of class values across folds Reduces variance in performance Unstratified cross-validation means there is no randomization Order is preserved Advantage for matching predictions with instances in Weka

18
Stratified versus Non-Stratified Leave-one-out cross validation Train on all but one instance Iterate over all instances Extreme version of unstratified cross-validation If test set only has one instance, the distribution of class values cannot be preserved Maximizes amount of data used for training on each fold

19
Stratified versus Non-Stratified Leave-one-subpopulation out If you have several data points from the same subpopulation Speech data from the same speaker May have data from same subpopulation in train and test over-estimates overlap between train and test When is this not a problem? You can manually make sure that won’t happen You have to do that by hand

20
Creating Train/Test Pairs If you pick unsupervised, you’ll get non-stratified folds, otherwise you’ll get stratified folds.

21
Creating Train/Test Pairs Now click here

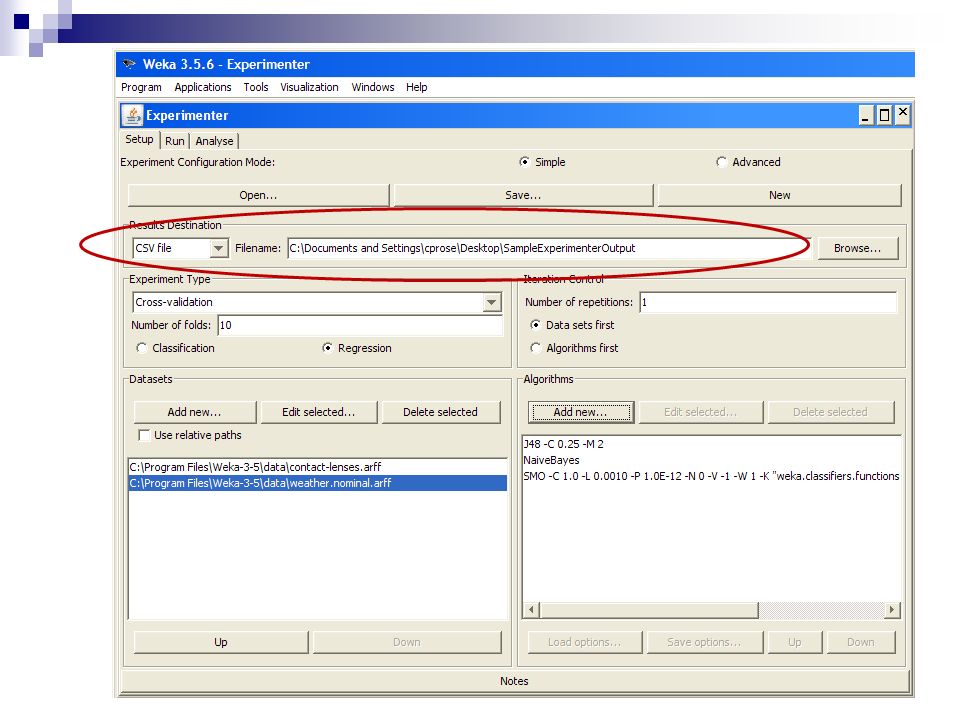
22
Creating Train/Test Pairs

23
You’re going to run this filter 20 times altogether. twice for every fold.

24
Creating Train/Test Pairs True for Train, false for Test

25
Creating Train/Test Pairs If you’re doing Stratified, make sure you have to class attribute selected here.

26
Creating Train/Test Pairs 1. Click Apply

27
Creating Train/Test Pairs 2. Save the file

28
Creating Train/Test Pairs 3. Undo before you create the next file

29
Doing Manual Train/Test * First load the training data on the Preprocess tab

30
Doing Manual Train/Test * Now select Supplied Test Set as the Test Option

31
Doing Manual Train/Test Then Click Set

32
Doing Manual Train/Test * Next Load the Test set

33
Doing Manual Train/Test * Then you’re all set, so click on Start

34
Evaluation Methodology

35
Intro to Chapter 5 Many techniques illustrated in Chapter 5 (ROC curves, recall-precision curves) don’t show up in applied papers They are useful for showing trade-offs between properties of different algorithms You see them in theoretical machine learning papers
 don’t show up in applied papers They are useful for showing trade-offs between properties of different algorithms You see them in theoretical machine learning papers")
36
Intro to Chapter 5 Still important to understand what they represent The thinking behind the techniques will show up in your papers You need to know what your numbers do and don’t demonstrate They give you a unified framework for thinking about machine learning techniques There is no cookie cutter for a good evaluation

37
Confidence Intervals Mainly important if there is some question about whether your data set is big enough You average your performance over 10 folds, but how certain can you be that the number you got is correct? We saw before that performance varies from fold to fold 010203040 ()
.")
38
Confidence Intervals We know that the distribution of categories found in the training set and in the testing set affects the performance Performance on two different sets will not be the same Confidence intervals allow us to say that the probability of the real performance value being within a certain range from the observed value is 90% 010203040 ()
")
39
Confidence Intervals Confidence limits come from the normal distribution Computed in terms of number of standard deviations from the mean If the data is normally distributed, there is a 15% chance of the real value being more than 1 standard deviation above the mean

40
What is a significance test? How likely is it that the difference you see occurred by chance? How could the difference occur by chance? 010203040 (()) If the mean of one distribution is within the confidence interval of another, the difference you observe could be by chance. If you want p<.05, you need the 90% confidence intervals. Find the corresponding Z scores from a standard normal distribution table.
) If the mean of one distribution is within the confidence interval of another, the difference you observe could be by chance. If you want p<.05, you need the 90% confidence intervals. Find the corresponding Z scores from a standard normal distribution table..")
41
Computing Confidence Intervals 90% confidence interval corresponds to z=1.65 5% chance that a data point will occur to the right of the rightmost edge of the interval f = percentage of successes N = number of trials p = (f + z 2 /2N +or- z(squrt(f/N – f 2 /N + z 2 /4N 2 )))/(1 + z 2 /N) f=75%, N=1000, c=90% -> [0.727,0.773]
![Computing Confidence Intervals 90% confidence interval corresponds to z=1.65 5% chance that a data point will occur to the right of the rightmost edge of the interval f = percentage of successes N = number of trials p = (f + z 2 /2N +or- z(squrt(f/N – f 2 /N + z 2 /4N 2 )))/(1 + z 2 /N) f=75%, N=1000, c=90% -> [0.727,0.773]](http://images.slideplayer.com/32/10032787/slides/slide_41.jpg "Computing Confidence Intervals 90% confidence interval corresponds to z=1.65 5% chance that a data point will occur to the right of the rightmost edge of the interval f = percentage of successes N = number of trials p = (f + z 2 /2N +or- z(squrt(f/N – f 2 /N + z 2 /4N 2 )))/(1 + z 2 /N) f=75%, N=1000, c=90% -> [0.727,0.773]")
42
Significance Tests If you want to know whether the difference in performance between Approach A and Approach B is significant Get performance numbers for A and B on each fold of a 10-fold cross validation You can use the Experimenter or you can do the computation in Excel or Minitab If you use exactly the same “folds” across approaches you can use a paired t-test rather than an unpaired t-test

43
Significance Tests Don’t forget that you can get a significant result by chance! The Experimenter corrects for multiple comparisons Significance tests are less important if you have a large amount of data and the difference in performance between approaches is large

44
Using the Experimenter * First click New

45
Using the Experimenter Make sure Simple is selected

46
Using the Experimenter Select.csv as the output file format and click on Browse Enter file name Click on Add New

47
Using the Experimenter Load data set

48
Using the Experimenter 10 repetitions is better than 1, but 1 is faster.

49
Using the Experimenter Click on Add New to add algorithms

50
Using the Experimenter Click Choose to select algorithm

51
Using the Experimenter You should add Naïve Bayes, SMO, and J48

52
Using the Experimenter Then click on the Run tab

53
Using the Experimenter Click on Start

54
Using the Experimenter When it’s done, Click on Analyze

55
Using the Experimenter Click File to load the results file you saved

56
Using the Experimenter

57
Do Analysis * Explicitly select default settings here * Then select Kappa Here * Then select Perform Test

58
Do Analysis * Base case is what you are comparing with

60
CSV Output

61
Analyze with Minitab

62
More Complex Statistical Analyses I put a Minitab manual in the Readings folder on Blackboard.

63
Take Home Message We focused on practical, methodological aspects of the topic of Evaluation We talked about the concept of a confidence interval and significance tests We learned how to create Train/Test pairs for manual cross-validation, which is useful for preparing for an error analysis We also learned how to use the Experimenter to do experiments and run significance tests

Similar presentations

 Computer Science cpsc502, Lecture 15 Nov, 1, 2011 Slide credit: C. Conati, S.>")






. 2 Predicting performance Assume the estimated error rate is 25%. How close is this to the true error rate? Depends on the amount.>")

>")




. After treatment, the.>")



