Download presentation
Presentation is loading. Please wait.

1
Machine Learning in Practice Lecture 7 Carolyn Penstein Rosé Language Technologies Institute/ Human-Computer Interaction Institute

2
Plan for the Day Announcements No new homework this week No quiz this week Project Proposal Due by the end of the week Naïve Bayes Review Linear Model Review Tic Tac Toe across models X X OX O O X X O

3
Project proposals If you are using one of the prefabricated projects on blackboard, let me know which one Otherwise, tell me what data you are using Number of instances What you’re predicting What features you are working with Short description of what your ideas are for improving performance If convenient, let me know what the baseline performance is Note: you can use your own data for the assignments from now on….

4
Example of ideas: How could you expand on what’s here?

5
Add features that describe the source

6
Example of ideas: How could you expand on what’s here? Add features that describe things that were going on during the time when the poll was taken

7
Example of ideas: How could you expand on what’s here? Add features that describe personal characteristics of the candidates

8
Getting the Baseline Performance Percent correct Percent correct, controlling for correct by chance Performance on individual categories Confusion matrix * Right click in Result list and select Save Result Buffer to save performance stats.

9
Clarification about Cohen’s Kappa A B AB 52 18 7 9 106 16 OverallTotal Total agreements = 13 Percent agreement = 13/16 =.81 Agreement by chance = i (Row i *Col i )/OverallTotal = 7*6/16 + 9*10/16 = 2.63 + 5.63 = 8.3 Kappa = (TotalAgreement – Agreement by Chance)/ (Overall Total – Agreement by Chance) = (13 – 8.3)/(16 – 8.3) = 4.7 / 7.7 =.61 Assume 2 coders were assigning instances to category A or category B, and you want to measure their agreement. Coder 1’s Codes Coder 2’s Codes

10
Naïve Bayes Review

11
Naïve Bayes Simulation You can modify the Class counts and Counts for each attribute value within each class. You can also turn smoothing on or off. Finally, you can manipulate the attribute values for the instance you want to classify with your model.

12
Naïve Bayes Simulation You can modify the Class counts and Counts for each attribute value within each class. You can also turn smoothing on or off. Finally, you can manipulate the attribute values for the instance you want to classify with your model.

13
Naïve Bayes Simulation You can modify the Class counts and Counts for each attribute value within each class. You can also turn smoothing on or off. Finally, you can manipulate the attribute values for the instance you want to classify with your model.

14
Linear Model Review

15
Remember this: What do concepts look like?

16
What are we learning? We’re learning to draw a line through a multidimensional space Really a “hyperplane” Each function we learn is like single split in a decision tree But it can take many features into account at one time rather than just one F(x) = C 0 + C 1 X 1 + C 2 X 2 + C 3 X 3 X 1 -X n are our attributes C 0 -C n are coefficients We’re learning the coefficients, which are weights
 = C 0 + C 1 X 1 + C 2 X 2 + C 3 X 3 X 1 -X n are our attributes C 0 -C n are coefficients We’re learning the coefficients, which are weights.")
17
What do linear models do? Notice that what you want to predict is a number You use the number to order instances You want to learn a function that can get the same ordering Linear models literally add evidence Result = 2*A - B - 3*C Actual values between 2 and -4, rather than between 1 and 5, but order is the same. Order affects correlation, actual value affects absolute error.

18
What do linear models do? If what you want to predict is a category, you can assign values to ranges Sort instances based on predicted value Cut based on threshold i.e., Val1 where f(x) < 0, Val2 otherwise Result = 2*A - B - 3*C Actual values between 2 and -4, rather than between 1 and 5, but order is the same.
 < 0, Val2 otherwise Result = 2*A - B - 3*C Actual values between 2 and -4, rather than between 1 and 5, but order is the same..")
19
What do linear models do? F(x) = C 0 + C 1 X 1 + C 2 X 2 + C 3 X 3 X 1 -X n are our attributes C 0 -C n are coefficients We’re learning the coefficients, which are weights Think of linear models as imposing a ranking on instances Features associated with one class get negative weights Features associated with the other class get positive weights
 = C 0 + C 1 X 1 + C 2 X 2 + C 3 X 3 X 1 -X n are our attributes C 0 -C n are coefficients We’re learning the coefficients, which are weights Think of linear models as imposing a ranking on instances Features associated with one class get negative weights Features associated with the other class get positive weights.")
20
More on Linear Regression Linear regressions try to minimize the sum of the squares of the differences between predicted values and actual values for all training instances Sum over all instances [ Square(predicted value of instance – actual value of instance) ] Note that this is different from back propagation for neural nets that minimize the error at the output nodes considering only one training instance at a time What is learned is a set of weights (not probabilities!)
![More on Linear Regression Linear regressions try to minimize the sum of the squares of the differences between predicted values and actual values for all training instances Sum over all instances [ Square(predicted value of instance – actual value of instance) ] Note that this is different from back propagation for neural nets that minimize the error at the output nodes considering only one training instance at a time What is learned is a set of weights (not probabilities!)](http://images.slideplayer.com/14/4312789/slides/slide_20.jpg "More on Linear Regression Linear regressions try to minimize the sum of the squares of the differences between predicted values and actual values for all training instances Sum over all instances [ Square(predicted value of instance – actual value of instance) ] Note that this is different from back propagation for neural nets that minimize the error at the output nodes considering only one training instance at a time What is learned is a set of weights (not probabilities!)")
21
Limitations of Linear Regressions Can only handle numeric attributes What do you do with your nominal attributes? You could turn them into numeric attributes For example: red = 1, blue = 2, orange = 3 But is red really less than blue? Is red closer to blue than it is to orange? If you treat your attributes in an unnatural way, your algorithms may make unwanted inferences about relationships between instances Another option is to turn nominal attributes into sets of binary attributes Note: Some people said linear models don’t handle nominal attributes on the homework and I disagreed – the reason I disagreed is because you CAN have nominal attributes, you just have to represent them in a way the model can deal with.

22
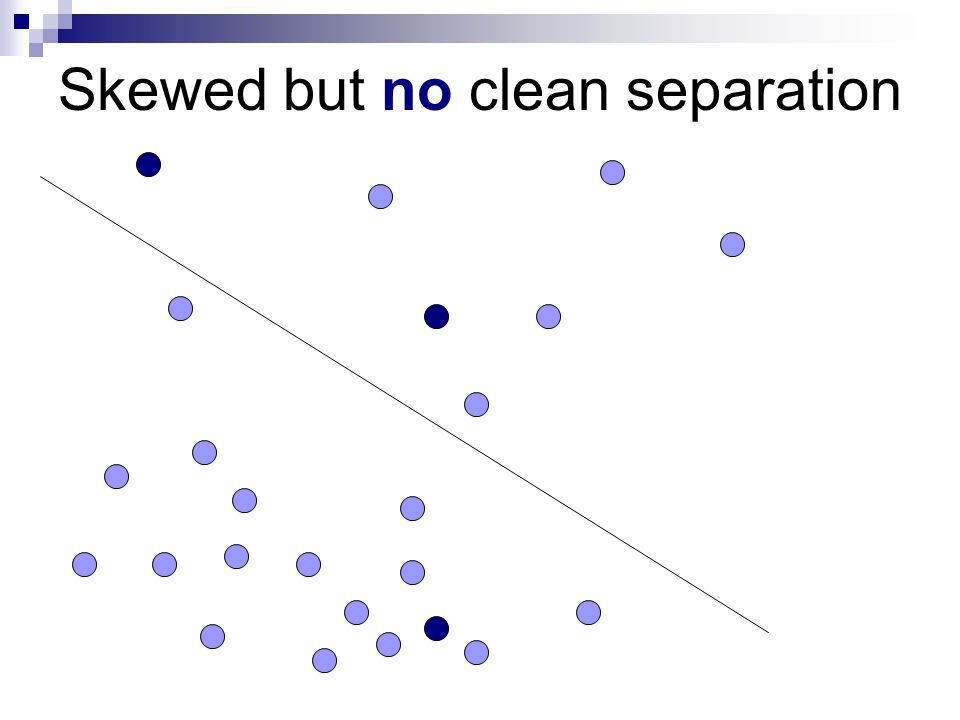
Performing well with skewed class distributions Naïve Bayes has trouble with skewed class distributions because of the contribution of prior probabilities Remember our math problem case Linear models can compensate for this They don’t have any notion of prior probability per se If they can find a good split on the data, they will find it wherever it is Problem if there is not a good split

23
Skewed but clean separation

25
Skewed but no clean separation

27
Taking a Step Back Linear models have rules composed of numbers So they “look” more like Naïve Bayes than like Decision Trees But the numbers are obtained through a focus on achieving accuracy So the learning process is more like Decision Trees Given these two properties, what can you say about assumptions about the form of the solution and assumptions about the world that are made?

28
Tic Tac Toe

29
What algorithm do you think would work best? How would you represent the feature space? What cases do you think would be hard? X X OX O O X X O

30
Tic Tac Toe X X OX O O X X O

31
Decision Trees:.67 Kappa SMO:.96 Kappa Naïve Bayes:.28 Kappa What do you think is different about what these algorithms is learning? X X OX O O X X O

32
Decision Trees

33
Naïve Bayes Each conditional probability is based on each square in isolation Can you guess which square is most informative? X X OX O O X X O

34
Linear Function Counts every X as evidence of winning If there are more X’s, then it’s a win for X Usually right, except in the case of a tie X X OX O O X X O

35
Take Home Message Naïve Bayes is affected by prior probabilities in two places Note that prior probabilities have an indirect effect on all conditional probabilities Linear functions are not directly affected by prior probabilities So sometimes they can perform better on skewed data sets Even with the same data representation, different algorithms learn something different Naïve Bayes learned that the center square is important Decision trees memorized important trees Linear function counted Xs

Similar presentations









>")
 Dealing with Indefinite Representations in Pattern Recognition.>")
>")

 Mathematics is a language. It is used to describe the world around us. Can.>")
 Given -> A set of classified examples “instances” Produce -> A way of classifying new examples.>")
>")




