Download presentation
Presentation is loading. Please wait.

1
mednlp@us.ibm.com MedKAT Medical Knowledge Analysis Tool December 2009

2
Overview ✤ MedKAT and MedKAT/p ✤ Developed at IBM, donated to OHNLP with Apache license V2.0 ✤ Goal: ✤ Identification of concepts and their attributes based on a standard or proprietary terminology/ontology ✤ “/p” adaptation to pathology reports – relation extraction ✤ UIMA-based, Modular, Generic, Expandable ✤ Terminology agnostic: able to plug in any terminology ✤ Easy adaptation to specific corpus and conventions ✤ Integration into institutional system ✤ Ongoing commitment to Research and Development

3
3 Core Components ✤ Document structure ✤ Syntactic tools (tokenization.. shallow parsing) ✤ Negation ✤ Concept identification ✤ Relationship extraction
 ✤ Negation ✤ Concept identification ✤ Relationship extraction.")
4
4 Core Components ✤ Document structure ✤ Syntactic tools (tokenization.. shallow parsing) ✤ Negation ✤ Concept identification ✤ Relationship extraction
 ✤ Negation ✤ Concept identification ✤ Relationship extraction.")
5
Document Structure ✤ Plain text or XML (e.g., CDA) ✤ Processes specific document section types (e.g., diagnosis) ✤ Detection of enumerated subsections (e.g., lists) ✤ Detection of formatting (e.g. bullets) ✤ Detection of relations between sections (e.g., coreference between corresponding lists appearing in different document sections) ✤ Making implicit conventions explicit (e.g. meaning of title)
 ✤ Detection of relations between sections (e.g., coreference between corresponding lists appearing in different document sections) ✤ Making implicit conventions explicit (e.g. meaning of title).")
6
Document Structure Annotators

7
7 Document Structure 16 Multiple document sections

8
8 Document Structure 17 Corresponding document subsections

9
9 Document Structure 18 Need to know document structure to be able to compute concept coreference during relation extraction

10
10 Core Components ✤ Document structure ✤ Syntactic tools (tokenization.. shallow parsing) ✤ Negation ✤ Concept identification ✤ Relationship extraction
 ✤ Negation ✤ Concept identification ✤ Relationship extraction.")
11
Syntactic Structure Annotators

12
Tokenization Basic building block for subsequent annotators. The text: poorly-differentiated/undifferentiated could be tokenized as 1, 3, or 5 tokens:

13
Part of Speech Tagger ✤ OpenNLP POS tagger with standard models ✤ Domain adaptation: ✤ Entries from lexicon are pre-tagged ✤ Rule-based overwriting of tags for specific cases

14
14 Shallow Parser 32

15
Merging NP Types The shallow parser defines three types of noun phrase: 1. NP 2. NPP 3. NPList

16
Merging NP Types The NPMerger module creates NPCombined annotations to cover all types of noun phrases.

17
17 Core Components ✤ Document structure ✤ Syntactic tools (tokenization.. shallow parsing) ✤ Negation ✤ Concept identification ✤ Relationship extraction
 ✤ Negation ✤ Concept identification ✤ Relationship extraction.")
18
Negation Annotators

19
Negation ✤ Keyword and syntactic analysis driven ✤ Set of keywords configurable via dictionary ✤ Type of syntactic phrase used to determine context is configurable

20
20 Core Components ✤ Document structure ✤ Syntactic tools (tokenization.. shallow parsing) ✤ Negation ✤ Concept identification ✤ Relationship extraction
 ✤ Negation ✤ Concept identification ✤ Relationship extraction.")
21
Concept Identification Annotators

22
Concept Identification ✤ Lexicon entries can be added, changed, deleted ✤ Lexicon entry attributes can be added, changed, deleted ✤ Search parameters can be modified ✤ Post processing filters ✤ Tokenization of text and lexicon should be the same

23
Lexicon Entries ✤ A sample lexicon entry. The variant elements define all of the synonyms that can be matched during lookup. Attributes associated with “token” element apply to all variants, but can be overridden within individual variants (e.g., the “POS” attribute in some of these variant entries). <token canonical="colon, nos" CodeType="ICDO" CodeValue="C18.9" SemClass="Site" POS="NN">
. <token canonical= colon, nos CodeType= ICDO CodeValue= C18.9 SemClass= Site POS= NN >.")
24
Concept Identification Configuration ✤ Configured to find all matched entries, not just longest match, even if overlapping ✤ Case-insensitive ✤ Token order independent matching performed, e.g.: A B C = C A B ✤ Subsequent filtering used to remove unnecessary over-generated results

25
Concept Filters ✤ Remove: ✤ any duplicates over a single span ✤ generic terms like “tumor” if part of a longer term ✤ terms that contain other terms that were previously marked, such as a modifier

26
26 Core Components ✤ Document structure ✤ Syntactic tools (tokenization.. shallow parsing) ✤ Negation ✤ Concept identification ✤ Relationship extraction
 ✤ Negation ✤ Concept identification ✤ Relationship extraction.")
27
Relationship Extraction Annotators

28
Relationship Extraction ✤ Find coreferences of both anatomical sites and histological diagnoses across document sections ✤ Discover relationships between named entities and build knowledge model: ✤ Tumors (primary, metastatic) ✤ Gross description ✤ Lymph nodes
 ✤ Gross description ✤ Lymph nodes")
29
Knowledge Model ✤ Benefits ✤ Summarization ✤ Comparison ✤ Change detection ✤ Temporal progression of disease ✤ Validation ✤ Manual annotation of pathology reports and clinical notes

31
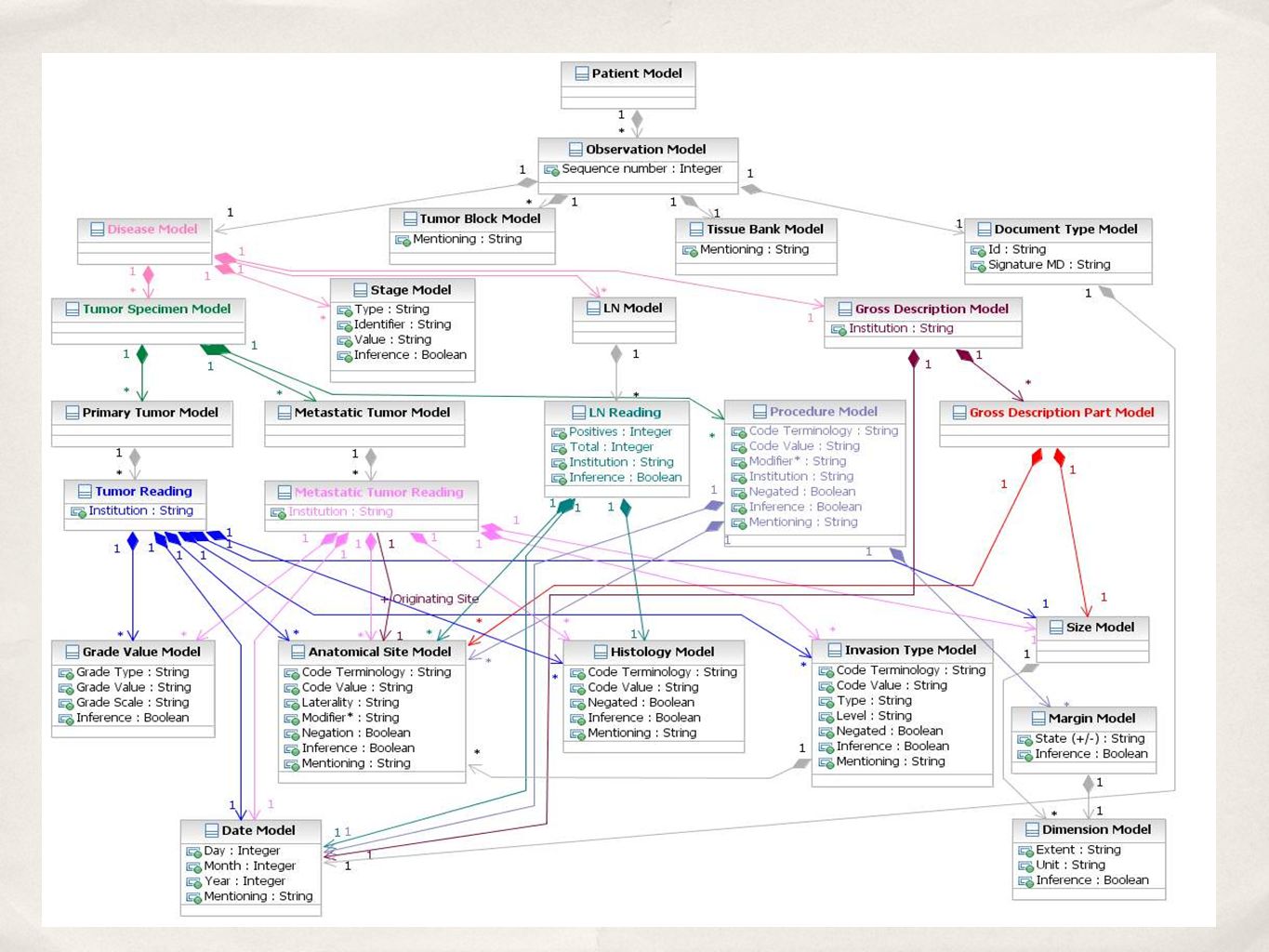
The MedKAT/p Pipeline

32
MedKAT/p Annotator Pipeline

33
MedKAT/p Pipeline ✤ The full processing pipeline brings together all of the MedKAT components ✤ Used a manually annotated gold standard corpus of 302 documents: 201 documents for training, 101 for testing ✤ UIMA CAS can be output as database load file, XML, or other format using a UIMA CAS Consumer module

34
Concept Extraction Results Training Instances Test Instances F-Score Anatomical Site 1,5987820.95 Histology6703360.98 Size9424711.00 Date145881.00 Grade2461240.98

35
Model Extraction Results Training Instances Test Instances F-Score Gross Description 2771370.80 Lymph Nodes 117590.81 Primary Tumor 2351260.82 Metastatic Tumor 33190.65

36
Summary ✤ MedKAT and MedKAT/p were developed at IBM, donated to OHNLP with Apache license V2.0 ✤ Apache UIMA based solution for flexible, expandable system ✤ Concepts are identified, with their associated attributes, based on a standard or proprietary terminology/ontology ✤ The “/p” version has additional components for processing pathology reports

Similar presentations


 Martin Bryan Convenor, JTC1/SC18 WG1.>")






![Biomedical Information Extraction. Outline Intro to biomedical information extraction PASTA [Demetriou and Gaizauskas] Biomedical named entities Name.](/16/5069742/big_thumb.jpg "Biomedical Information Extraction. Outline Intro to biomedical information extraction PASTA [Demetriou and Gaizauskas] Biomedical named entities Name.>")









