Download presentation
Presentation is loading. Please wait.

1
ΕΠΛ 605: Προχωρημένη Αρχιτεκτονική Υπολογιστών Piranha: A Scalable Architecture Based on Single-Chip Multiprocessing Luiz André Barroso, Kourosh Gharachorloo, Robert McNamara, Andreas Nowatzyk, Shaz Qadeer, Barton Sano, Scott Smith, Robert Stets, and Ben Verghese In Proceedings of the 27th Annual International Symposium on Computer Architecture, June 2000

2
Piranha: A Scalable Architecture Based on Single-Chip Multiprocessing Problem: complex processors are ill-suited for commercial applications Solution: CMP approach Piranha System: -research prototype developed at COMPAQ -Exploits CMP, intergrades 8 simple Alpha processor cores with 2-level cache hierarchy on a single chip Piranha unique design choices: -shared second level cache with no inclusion -Highly optimized cache coherence protocol -Novel I/O architecture

3
Piranha: A Scalable Architecture Based on Single-Chip Multiprocessing Different behavior of commercial workloads relative to technical workloads -large memory stalls -Data-dependent nature of the computation & lack of ILP -No use of high-performance FP and multimedia functionality Techniques: -SMT -CMT Goal of Piranha: build a system to achieve superior performance on commercial workloads

4
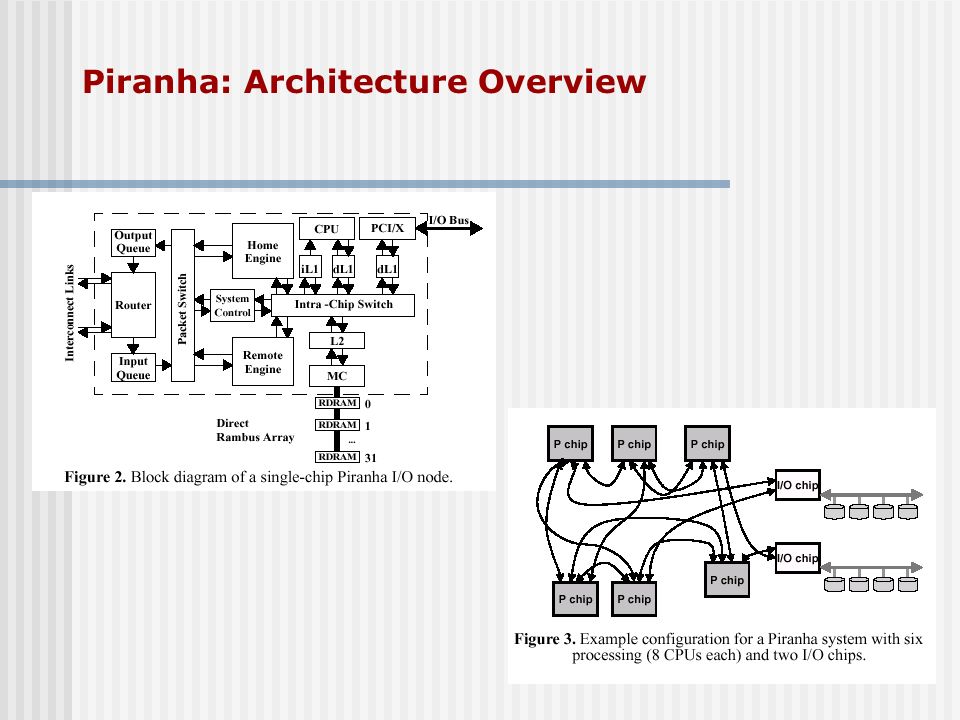
Piranha: Architecture Overview

6
Alpha CPU Core and L1 Caches CPU Single issue, in order design capable of executing Alpha ISA 500 MHZ pipelined datapath Performance enhancing features: branch target buffer, pre-compute logic for branch predictions, fully by-passed datapath L1 caches 64KB two-way set associative blocking caches 2-bit state field per cache line-> 4 stages in a typical MESI protocol I and D-cache are kept coherent by hardware

7
Intra-Chip Switch Uses bidirectional, push-only interface Initiator sources data, if destination ready then ICS schedules the data transfer. A grant is issued to the initiator to commense data transfer. The destination receives a request signal: ID of initiator and type of transfer Each port to ICS consists of 2 independent datapaths Implemented by a set of 8 internal datapaths Supports 2 logical lanes (low and high priority)
.")
8
Second - Level Cache 1MB unified I/O cache, physically partitioned into 8 banks Each bank 8-way set associative and uses round robin replacement policy L2 controllers responsible for intra-chip coherence and cooperate with engines to to enforce inter-chip coherence Non-inclusive on-chip cache: Keep a duplicate copy of the L1 tags and state at the L2 controllers L1 misses that also miss in L2 are filled directly from memory. L2 behaves as victim cache The duplicate L1 state is extended to include “ownership” Intra-chip coherence protocol L2 controllers are responsible Similarities to a full map centralized directory based protocol

9
Piranha architecture Does not have direct access to ICS, is controlled by and routed through L2 controller Two parts: 1) RAC and 2) Memory Controller Engine Memory controller Protocol Engines Home Engine: responsible for exporting memory whose home is at the local node Remote Engine: imports memory whose hoem is remote
 RAC and 2) Memory Controller Engine Memory controller Protocol Engines Home Engine: responsible for exporting memory whose home is at the local node Remote Engine: imports memory whose hoem is remote")
10
Inter-node Coherence Protocol Invalidation-based directory protocol Support for 4 request types: read, read-exclusive, exclusive, exclusive-without-data Support features: clean-exclusive optimization, reply forwarding from remote owner, eager exclusive replies Unique property: avoids NAK Unique techniques: 1) Network uses “hot potato” routing, 2)Buffer space is shared among all lanes 3)Cruise-missile-invalidates (CMI)
 Network uses hot potato routing, 2)Buffer space is shared among all lanes 3)Cruise-missile-invalidates (CMI)")
11
System Interconnect OO Output queue: accepts packets via the packet switch from the protocol engines or from the system controller Router: transmits and receives packets to and from other nodes IQ Input queue: receives packets that are addressed to the local node and forwards them to the target module via the packet switch

12
Reliability Features RAS features: redundancy on all memory components, CRC protection on most datapaths, redundant datapaths, protocol error recovery, error logging, hot-swappable links and in-band system reconfiguration support

13
Evaluation Workloads DSS workload with TCP-D benchmark OLTP workload with TCP-B benchmark Simulation environment Use of SinOS Alpha environment:simulates hardware components of Alpha based multiprocessors Simulated architectures

14
Performance Evaluation of Piranha

15
Conclusions Use of CMP in future multiprocessor designs Piranha: from evaluation: outperforms other designs

Similar presentations