Download presentation
Presentation is loading. Please wait.

1
Algorithms for MAP estimation in Markov Random Fields Vladimir Kolmogorov University College London

2
Energy function p q unary terms (data) pairwise terms (coherence) - x p are discrete variables (for example, x p {0,1}) - p ( ) are unary potentials - pq (, ) are pairwise potentials
 pairwise terms (coherence) - x p are discrete variables (for example, x p {0,1}) - p ( ) are unary potentials - pq (, ) are pairwise potentials")
3
Minimisation algorithms Min Cut / Max Flow [Ford&Fulkerson ‘56] [Grieg, Porteous, Seheult ‘89] : non-iterative (binary variables) [Boykov, Veksler, Zabih ‘99] : iterative - alpha-expansion, alpha-beta swap, … (multi-valued variables) + If applicable, gives very accurate results – Can be applied to a restricted class of functions BP – Max-product Belief Propagation [Pearl ‘86] + Can be applied to any energy function – In vision results are usually worse than that of graph cuts – Does not always converge TRW - Max-product Tree-reweighted Message Passing [Wainwright, Jaakkola, Willsky ‘02], [Kolmogorov ‘05] + Can be applied to any energy function + For stereo finds lower energy than graph cuts + Convergence guarantees for the algorithm in [Kolmogorov ’05]
![Minimisation algorithms Min Cut / Max Flow [Ford&Fulkerson ‘56] [Grieg, Porteous, Seheult ‘89] : non-iterative (binary variables) [Boykov, Veksler, Zabih ‘99] : iterative - alpha-expansion, alpha-beta swap, … (multi-valued variables) + If applicable, gives very accurate results – Can be applied to a restricted class of functions BP – Max-product Belief Propagation [Pearl ‘86] + Can be applied to any energy function – In vision results are usually worse than that of graph cuts – Does not always converge TRW - Max-product Tree-reweighted Message Passing [Wainwright, Jaakkola, Willsky ‘02], [Kolmogorov ‘05] + Can be applied to any energy function + For stereo finds lower energy than graph cuts + Convergence guarantees for the algorithm in [Kolmogorov ’05]](http://images.slideplayer.com/26/8299251/slides/slide_3.jpg "Minimisation algorithms Min Cut / Max Flow [Ford&Fulkerson ‘56] [Grieg, Porteous, Seheult ‘89] : non-iterative (binary variables) [Boykov, Veksler, Zabih ‘99] : iterative - alpha-expansion, alpha-beta swap, … (multi-valued variables) + If applicable, gives very accurate results – Can be applied to a restricted class of functions BP – Max-product Belief Propagation [Pearl ‘86] + Can be applied to any energy function – In vision results are usually worse than that of graph cuts – Does not always converge TRW - Max-product Tree-reweighted Message Passing [Wainwright, Jaakkola, Willsky ‘02], [Kolmogorov ‘05] + Can be applied to any energy function + For stereo finds lower energy than graph cuts + Convergence guarantees for the algorithm in [Kolmogorov ’05]")
4
Main idea: LP relaxation Goal: Minimize energy E(x) under constraints x p {0,1} In general, NP-hard problem! Relax discreteness constraints: allow x p [0,1] Results in linear program. Can be solved in polynomial time! Energy function with discrete variables LP relaxation E E E tight not tight

5
Solving LP relaxation Too large for general purpose LP solvers (e.g. interior point methods) Solve dual problem instead of primal: –Formulate lower bound on the energy –Maximize this bound –When done, solves primal problem (LP relaxation) Two different ways to formulate lower bound –Via posiforms: leads to maxflow algorithm –Via convex combination of trees: leads to tree-reweighted message passing Lower bound on the energy function E Energy function with discrete variables E E LP relaxation
 Solve dual problem instead of primal: –Formulate lower bound on the energy –Maximize this bound –When done, solves primal problem (LP relaxation) Two different ways to formulate lower bound –Via posiforms: leads to maxflow algorithm –Via convex combination of trees: leads to tree-reweighted message passing Lower bound on the energy function E Energy function with discrete variables E E LP relaxation.")
6
Notation and Preliminaries

7
Energy function - visualisation 0 4 0 1 3 02 5 node p edge (p,q) node q label 0 label 1 0
 node q label 0 label 1 0")
8
0 4 0 1 3 02 5 node p edge (p,q) node q label 0 label 1 Energy function - visualisation 0 vector of all parameters
 node q label 0 label 1 Energy function - visualisation 0 vector of all parameters")
9
0 0 4 4 1 1 2 5 0 0 + 1 Reparameterisation

10
0 0 3 4 1 0 2 5 Definition. is a reparameterisation of if they define the same energy: 4 -1 1 -1 0 +1 Maxflow, BP and TRW perform reparameterisations 1

11
Part I: Lower bound via posiforms ( maxflow algorithm)
")
12
non-negative - lower bound on the energy: maximize Lower bound via posiforms [Hammer, Hansen, Simeone’84]
![non-negative - lower bound on the energy: maximize Lower bound via posiforms [Hammer, Hansen, Simeone’84]](http://images.slideplayer.com/26/8299251/slides/slide_12.jpg "non-negative - lower bound on the energy: maximize Lower bound via posiforms [Hammer, Hansen, Simeone’84]")
13
Maximisation algorithm? –Consider functions of binary variables only Maximising lower bound for submodular functions –Definition of submodular functions –Overview of min cut/max flow –Reduction to max flow –Global minimum of the energy Maximising lower bound for non-submodular functions –Reduction to max flow More complicated graph –Part of optimal solution Outline of part I

14
Definition: E is submodular if every pairwise term satisfies Can be converted to “canonical form”: Submodular functions of binary variables 2 1234 1 0 00 5 zero cost

15
Overview of min cut/max flow

16
Min Cut problem source sink 2 1 1 2 3 4 5 Directed weighted graph

17
Min Cut problem sink 2 1 1 2 3 4 5 S = {source, node 1} T = {sink, node 2, node 3} Cut: source

18
Min Cut problem sink 2 1 1 2 3 4 5 S = {source, node 1} T = {sink, node 2, node 3} Cut: Task: Compute cut with minimum cost Cost(S,T) = 1 + 1 = 2 source
 = = 2 source")
19
sink 2 1 1 2 3 4 5 source Maxflow algorithm value(flow)=0
=0")
20
Maxflow algorithm sink 2 1 1 2 3 4 5 value(flow)=0 source
=0 source")
21
Maxflow algorithm sink 1 1 0 3 3 4 4 value(flow)=1 source
=1 source")
22
Maxflow algorithm sink 1 1 0 3 3 4 4 value(flow)=1 source
=1 source")
23
Maxflow algorithm sink 1 0 0 3 4 3 3 value(flow)=2 source
=2 source")
24
Maxflow algorithm sink 1 0 0 3 4 3 3 value(flow)=2 source
=2 source")
25
value(flow)=2 sink 1 0 0 3 4 3 3 source Maxflow algorithm
=2 sink source Maxflow algorithm")
26
Maximising lower bound for submodular functions: Reduction to maxflow

27
2 1234 1 0 00 5 sink 2 1 1 2 3 4 5 source value(flow)=0 0 Maxflow algorithm and reparameterisation
=0 0 Maxflow algorithm and reparameterisation")
28
sink 2 1 1 2 3 4 5 value(flow)=0 2 1234 1 0 00 5 0 source Maxflow algorithm and reparameterisation
= source Maxflow algorithm and reparameterisation")
29
sink 1 1 0 3 3 4 4 value(flow)=1 1 0334 1 0 00 4 1 source Maxflow algorithm and reparameterisation
= source Maxflow algorithm and reparameterisation")
30
sink 1 1 0 3 3 4 4 value(flow)=1 1 0334 1 0 00 4 1 source Maxflow algorithm and reparameterisation
= source Maxflow algorithm and reparameterisation")
31
sink 1 0 0 3 4 3 3 value(flow)=2 1 0343 0 0 00 3 2 source Maxflow algorithm and reparameterisation
= source Maxflow algorithm and reparameterisation")
32
sink 1 0 0 3 4 3 3 value(flow)=2 1 0343 0 0 00 3 2 source Maxflow algorithm and reparameterisation
= source Maxflow algorithm and reparameterisation")
33
value(flow)=2 0 0 0 0 minimum of the energy: 2 0 sink 1 0 0 3 4 3 3 source Maxflow algorithm and reparameterisation
= minimum of the energy: 2 0 sink source Maxflow algorithm and reparameterisation")
34
Maximising lower bound for non-submodular functions

35
Arbitrary functions of binary variables Can be solved via maxflow [Boros,Hammer,Sun’91] –Specially constructed graph Gives solution to LP relaxation: for each node x p {0, 1/2, 1} E LP relaxation non-negative maximize
![Arbitrary functions of binary variables Can be solved via maxflow [Boros,Hammer,Sun’91] –Specially constructed graph Gives solution to LP relaxation: for each node x p {0, 1/2, 1} E LP relaxation non-negative maximize](http://images.slideplayer.com/26/8299251/slides/slide_35.jpg "Arbitrary functions of binary variables Can be solved via maxflow [Boros,Hammer,Sun’91] –Specially constructed graph Gives solution to LP relaxation: for each node x p {0, 1/2, 1} E LP relaxation non-negative maximize")
36
Arbitrary functions of binary variables 0 1 0 1 11/2 Part of optimal solution [Hammer, Hansen, Simeone’84]
![Arbitrary functions of binary variables /2 Part of optimal solution [Hammer, Hansen, Simeone’84]](http://images.slideplayer.com/26/8299251/slides/slide_36.jpg "Arbitrary functions of binary variables /2 Part of optimal solution [Hammer, Hansen, Simeone’84]")
37
Part II: Lower bound via convex combination of trees ( tree-reweighted message passing)
")
38
Goal: compute minimum of the energy for In general, intractable! Obtaining lower bound: –Split into several components: –Compute minimum for each component: –Combine to get a bound on Use trees! Convex combination of trees [Wainwright, Jaakkola, Willsky ’02]

39
graph tree Ttree T’ lower bound on the energy maximize Convex combination of trees (cont’d)
")
40
TRW algorithms Goal: find reparameterisation maximizing lower bound Apply sequence of different reparameterisation operations: –Node averaging –Ordinary BP on trees Order of operations? –Affects performance dramatically Algorithms: –[Wainwright et al. ’02]: parallel schedule May not converge –[Kolmogorov’05]: specific sequential schedule Lower bound does not decrease, convergence guarantees

41
Node averaging 0 1 4 0

42
2 0.5 2
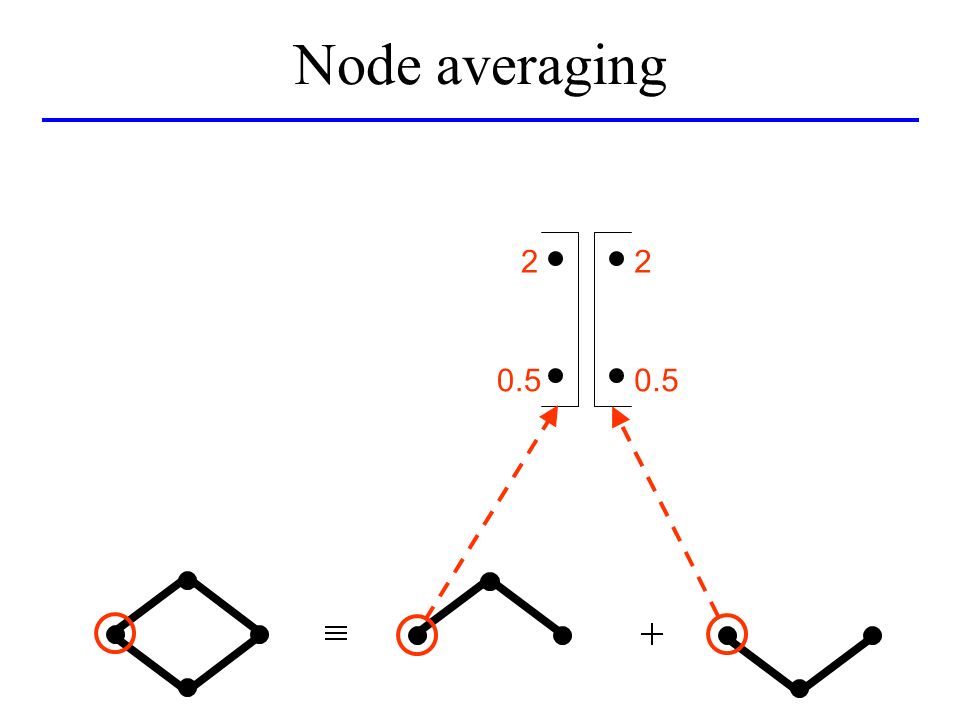
43
Send messages –Equivalent to reparameterising node and edge parameters Two passes (forward and backward) Belief propagation (BP) on trees
 Belief propagation (BP) on trees")
44
3 0 Key property (Wainwright et al.): Upon termination p gives min-marginals for node p:
: Upon termination p gives min-marginals for node p:")
45
TRW algorithm of Wainwright et al. with tree-based updates (TRW-T) Run BP on all trees “Average” all nodes If converges, gives (local) maximum of lower bound Not guaranteed to converge. Lower bound may go down.
 Run BP on all trees Average all nodes If converges, gives (local) maximum of lower bound Not guaranteed to converge. Lower bound may go down..")
46
Sequential TRW algorithm (TRW-S) [Kolmogorov’05] Run BP on all trees containing p “Average” node p Pick node p
![Sequential TRW algorithm (TRW-S) [Kolmogorov’05] Run BP on all trees containing p Average node p Pick node p](http://images.slideplayer.com/26/8299251/slides/slide_46.jpg "Sequential TRW algorithm (TRW-S) [Kolmogorov’05] Run BP on all trees containing p Average node p Pick node p")
47
Main property of TRW-S Theorem: lower bound never decreases. Proof sketch: 0 1 4 0

48
Main property of TRW-S 2 0.5 2 Theorem: lower bound never decreases. Proof sketch:

49
TRW-S algorithm Particular order of averaging and BP operations Lower bound guaranteed not to decrease There exists limit point that satisfies weak tree agreement condition Efficiency?

50
“Average” node p Pick node p inefficient? Efficient implementation Run BP on all trees containing p

51
Efficient implementation Key observation: Node averaging operation preserves messages oriented towards this node Reuse previously passed messages! Need a special choice of trees: –Pick an ordering of nodes –Trees: monotonic chains 456 789 123

52
Efficient implementation 456 789 123 Algorithm: –Forward pass: process nodes in the increasing order pass messages from lower neighbours –Backward pass: do the same in reverse order Linear running time of one iteration

53
Efficient implementation 456 789 123 Algorithm: –Forward pass: process nodes in the increasing order pass messages from lower neighbours –Backward pass: do the same in reverse order Linear running time of one iteration

54
Memory requirements Additional advantage of TRW-S: –Needs only half as much memory as standard message passing! –Similar observation for bipartite graphs and parallel schedule was made in [Felzenszwalb&Huttenlocher’04] standard message passing TRW-S

55
Experimental results: binary segmentation (“GrabCut”) Time Energy average over 50 instances
 Time Energy average over 50 instances")
56
Experimental results: stereo left image ground truth BP TRW-S

57
Experimental results: stereo

58
Summary MAP estimation algorithms are based on LP relaxation –Maximize lower bound Two ways to formulate lower bound Via posiforms: leads to maxflow algorithm –Polynomial time solution –But: applicable for restricted energies (e.g. binary variables) Submodular functions: global minimum Non-submodular functions: part of optimal solution Via convex combination of trees: leads to TRW algorithm –Convergence in the limit (for TRW-S) –Applicable to arbitrary energy function Graph cuts vs. TRW: –Accuracy: similar –Generality: TRW is more general –Speed: for stereo TRW is currently 2-5 times slower. But: 3 vs. 50 years of research! More suitable for parallel implementation (GPU? Hardware?)
 Submodular functions: global minimum Non-submodular functions: part of optimal solution Via convex combination of trees: leads to TRW algorithm –Convergence in the limit (for TRW-S) –Applicable to arbitrary energy function Graph cuts vs. TRW: –Accuracy: similar –Generality: TRW is more general –Speed: for stereo TRW is currently 2-5 times slower. But: 3 vs. 50 years of research. More suitable for parallel implementation (GPU. Hardware ).")
59
Discrete vs. continuous functionals Continuous formulation (Geodesic active contours) Maxflow algorithm –Global minimum, polynomial-time Metrication artefacts? Level sets –Numerical stability? Geometrically motivated –Invariant under rotation Discrete formulation (Graph cuts)
 Maxflow algorithm –Global minimum, polynomial-time Metrication artefacts. Level sets –Numerical stability. Geometrically motivated –Invariant under rotation Discrete formulation (Graph cuts).")
60
Geo-cuts Continuous functional Construct graph such that for smooth contours C Class of continuous functionals? [Boykov&Kolmogorov’03], [Kolmogorov&Boykov’05]: –Geometric length/area (e.g. Riemannian) –Flux of a given vector field –Regional term
 –Flux of a given vector field –Regional term.")
62
TRW formulation where is the collection of all parameter vectors is a fixed probability distribution on trees T

63
Efficient implementation Algorithm: –Forward pass: process nodes in the increasing order pass messages from lower neighbours –Backward pass: do the same in reverse order Linear running time of one iteration 456 789 123 node being processed valid messages

64
Efficient implementation 456 789 123 Algorithm: –Forward pass: process nodes in the increasing order pass messages from lower neighbours –Backward pass: do the same in reverse order Linear running time of one iteration

65
Efficient implementation Algorithm: –Forward pass: process nodes in the increasing order pass messages from lower neighbours –Backward pass: do the same in reverse order Linear running time of one iteration 456 789 123 node being processed valid messages

66
Efficient implementation 456 789 123 valid messages node being processed Algorithm: –Forward pass: process nodes in the increasing order pass messages from lower neighbours –Backward pass: do the same in reverse order Linear running time of one iteration

67
Efficient implementation 456 789 123 node being processed valid messages Algorithm: –Forward pass: process nodes in the increasing order pass messages from lower neighbours –Backward pass: do the same in reverse order Linear running time of one iteration

Similar presentations

>")




>")







>")

>")



