Download presentation
Presentation is loading. Please wait.

1
DCSP-8: Minimal length coding II, Hamming distance, Encryption Jianfeng Feng Jianfeng.feng@warwick.ac.uk http://www.dcs.warwick.ac.uk/~feng/dsp.html

2
Huffman coding The code in Table 1, however, is an instantaneously parsable code. It satisfies the prefix condition.

3
0.729*1+0.081*3*3+0.009*5*3+0.001*5=1. 5980

4
Decoding 1 1 1 0 1 1 0 1 0 1 1 0 0 0 0 0 0 0 0 0 1 Why do we require a code with the shortest average length?

5
The derivation of the Huffman code tree is shown in Fig. and the tree itself is shown in Fig.. In both these figures, the letter A to H have be used in replace of the sequence in Table 2 to make them easier to read.

9
Frequency for alphabetics

10
Turbo coding Using Bayesian theorem to code and decode Bayesian theorem basically said we should employ priori knowledge as much as possible Read yourself

11
Channel coding; Hamming distance The task of source coding is to represent the course information with the minimum of symbols. When a code is transmitted over a channel in the presence of noise, errors will occur. The task of channel coding is to represent the source information in a manner that minimises the error probability in decoding.

12
It is apparent that channel coding requires the use of redundancy. If all possible outputs of the channel correspond uniquely to a source input, this is no possibility of detecting errors in the transmission. To detect, and possibly correct errors, the channel code sequence must be longer than the source sequence.

13
A good channel code is designed so that, if a few errors occur in transmission, the output can still be decoded with the correct input. This is possible because although incorrect, the output is sufficiently similar to the input to be recognisable.

14
The idea of similarity is made more firm by the definition of a Hamming distance. Let x and y be two binary sequence of the same length. The hamming distance between these two codes is the number of symbols that disagree.

15
Two example distances: 0100->1001 has distance 3 (red path); 0110->1110 has distance 1 (blue path)
; 0110->1110 has distance 1 (blue path)")
16
The Hamming distance between 1011101 and 1001001 is 2. The Hamming distance between 2143896 and 2233796 is 3. The Hamming distance between "toned" and "roses" is 3.

17
Suppose the code x is transmitted over the channel. Due to error, y is received. The decoder will assign to y the code x that minimises the Hamming distance between x and y.

18
It can be shown that to detect n bit errors, a coding scheme requires the use of codewords with a Hamming distance of at least n+1. it can be also shown that to correct n bit errors requires a coding scheme with a least a Hamming distance of 2n+1 between the codewords. By designing a good code, we try to ensure that the Hamming distance between possible codewords x is larger than the Hamming distance arising from errors.

19
1111111111 0000000000 0000011111 0100100100
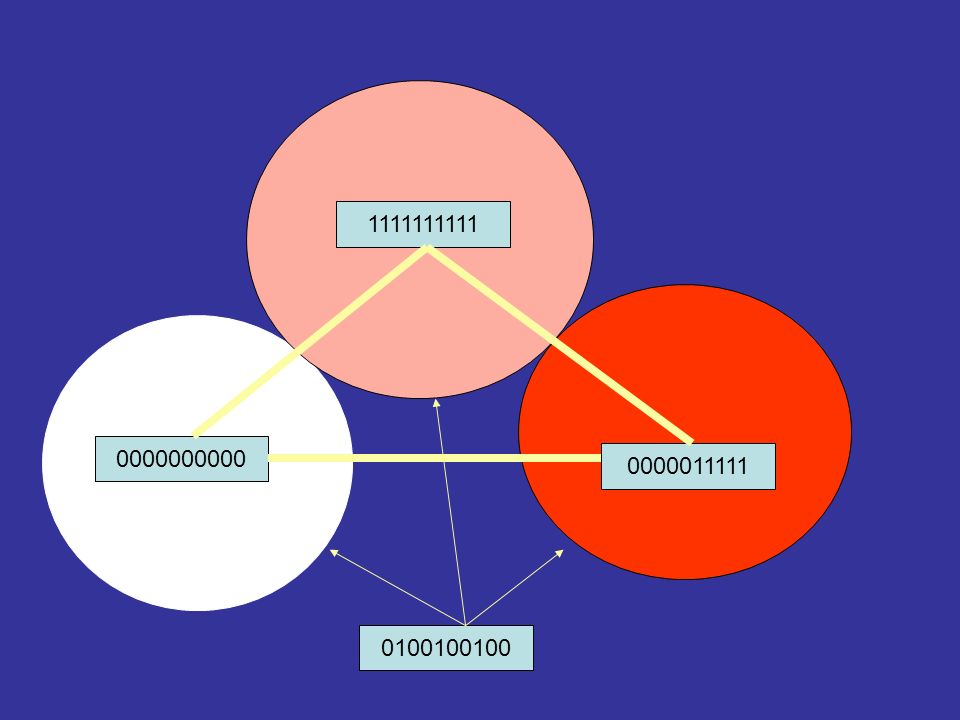
20
Channel Capacity One of the most famous of all results of information theory is Shannon's channel capacity theorem. For a given channel there exists a code that will permit the error-free transmission across the channel at a rate R, provided R<C, the channel capacity.

21
C = B log 2 ( 1 + (S/N) ) b/s
 ) b/s")
22
As we have already noted, the astonishing part of the theory is the existence of a channel capacity. Shannon's theorem is both tantalizing and frustrating.

23
It is offers error-free transmission, but it makes no statements as to what code is required. In fact, all we may deduce from the proof of the theorem is that is must be a long one. No none has yet found a code that permits the use of a channel at its capacity. However, Shannon has thrown down the gauntlet, in as much as he has proved that the code exists.

24
We shall not give a description of how the capacity is calculated. However, an example is instructive. The binary channel is a channel with a binary input and output. Associated with each output is a probability p that the output is correct, and a probability 1-p it is not.

25
For such a channel, the channel capacity turns output to be: C =1+ p log 2 p+ (1-p) log 2 (1-p) Here, p is the bit error probability. If p=0, then C=1. If p=0.5, then C=0. Thus if there is equal of receiving a 1 or 0, irrespective of the signal sent, the channel is completely unreliable and no message can be sent across it.

26
So defined., the channel capacity is a non-dimensional number. We normally quote the capacity as a rate, in bits/second. To do this we relate each output to a change in the signal. For the binary channel we have C = B [1+p log 2 p+(1-p) log 2 (1-p)] We note that C<B, i.e. the capacity is always less than the it rate.
 log 2 (1-p)] We note that C<B, i.e. the capacity is always less than the it rate..")
27
Error detection coding

28
A very common code is the single parity check code.

29
This code appends to each K data bits an additional bit whose value is taken to make the K+1 word even or odd.

30
A very common code is the single parity check code. This code appends to each K data bits an additional bit whose value is taken to make the K+1 word even or odd. Such a choice is said to have even (odd) parity.
 parity..")
31
A very common code is the single parity check code. This code appends to each K data bits an additional bit whose value is taken to make the K+1 word even or odd. Such a choice is said to have even (odd) parity. With even off parity, a single bit error will make the received word odd (even).
 parity. With even off parity, a single bit error will make the received word odd (even)..")
32
To see how the additional of a parity bit can improve error performance, consider the following example.

33
A common choice of code block is eight. Suppose that bit error rate is p=10 -4. Then

34
So, the probability of a transmission with an error is as above. With the additional of a parity error bit we can detect any single bit error.

35
As can be seen the addition of a parity bit has reduced the uncorrected error rate by three orders or magnitude.

36
Single parity bits are common in asynchronous transmission. Where synchronous transmission is used, additional parity symbols are added that check not only the parity of each 8 bit row, but also the parity of each 8 bit column. The column is formed by listing each successive 8 bit word one beneath the other. This type of parity checking is called lock sum checking, and it can correct any single 2 bit error in the transmitted block of rows and columns. However, there are some combinations of errors that will go undetected in such a scheme.

38
Parity checking in this way provides good protection against single and multiple errors when the probability of the errors are independent. However, in many circumstances, errors occur in groups, or bursts. Parity checking the kind just described than provides little protection. In these circumstances, a polynomial code is used.

39
Encryption

40
In all our discussion of coding, we have not mentioned what is popularly supposed to be the purpose of coding: security.

41
Encryption In all our discussion of coding, we have not mentioned what is popularly supposed to be the purpose of coding: security. We have only considered coding as a mechanism for improving the integrity of the communication system in the presence of noise.

42
Encryption In all our discussion of coding, we have not mentioned what is popularly supposed to be the purpose of coding: security. We have only considered coding as a mechanism for improving the integrity of the communication system in the presence of noise. The use of coding for security has a different name: encryption.

43
Encryption In all our discussion of coding, we have not mentioned what is popularly supposed to be the purpose of coding: security. We have only considered coding as a mechanism for improving the integrity of the communication system in the presence of noise. The use of coding for security has a different name: encryption. encryption is the process of obscuring information to make it unreadable without special knowledge The use of digital computers has made highly secure communication a normal occurrence.

45
Enigma machine

46
The basis for key based encryption is that is very much easier to encrypt with knowledge of the key than it is to decipher without knowledge of the key. Secret key cryptography: uses a single secret key for both encryption and decryption.

47
Public key cryptography, also known as matched key cryptography, is a form of cryptography in which a user has a pair of cryptographic keys - a public key and a private key.

48
Public key cryptography, also known as matched key cryptography, is a form of cryptography in which a user has a pair of cryptographic keys - a public key and a private key. The private key is kept secret, while the public key may be widely distributed. The keys are related mathematically, but the private key cannot be practically derived from the public key.

49
Public key cryptography, also known as matched key cryptography, is a form of cryptography in which a user has a pair of cryptographic keys - a public key and a private key. The private key is kept secret, while the public key may be widely distributed. The keys are related mathematically, but the private key cannot be practically derived from the public key. A message encrypted with the public key can only be decrypted with the corresponding private key.

50
This key is use by the sender to encrypt the message. This message is unintelligible to anyone not in possession of the second, private key. In this way the private key need not be transferred. The most famous of such scheme is the public Key mechanism using work of Rivest, Shamir and Adleman (RSA).
..")
51
It is based on the use of multiplying extremely large numbers and, with current technology, is computationally very expensive. Based upon a mathematics branch: Number theory symbol (dictionary)^prime number (mod public key) = encoded symbol encoded symbol (dictionary)^ the other prime number (mod public key) = encoded symbol
^prime number (mod public key) = encoded symbol encoded symbol (dictionary)^ the other prime number (mod public key) = encoded symbol.")
52
RSA numbers are composite numbers having exactly two prime factors that have been listed in the Factoring Challenge of RSA Security® and have been particularly chosen to be difficult to factor. While RSA numbers are much smaller than the largest known primes, their factorization is significant because of the curious property of numbers that proving or disproving a number to be prime ("primality testing") seems to be much easier than actually identifying the factors of a number ("prime factorization").
 seems to be much easier than actually identifying the factors of a number ( prime factorization )..")
53
Thus, while it is trivial to multiply two large numbers and together, it can be extremely difficult to determine the factors if only their product is given. With some ingenuity, this property can be used to create practical and efficient encryption systems for electronic data. RSA Laboratories sponsors the RSA Factoring Challenge to encourage research into computational number theory and the practical difficulty of factoring large integers, and because it can be helpful for users of the RSA encryption public-key cryptography algorithm for choosing suitable key lengths for an appropriate level of security. A cash prize is awarded to the first person to factor each challenge number.

54
RSA numbers were originally spaced at intervals of 10 decimal digits between 100 and 500 digits, and prizes were awarded according to a complicated formula. These original numbers were named according to the number of decimal digits, so RSA-100 was a hundred- digit number. As computers and algorithms became faster, the unfactored challenge numbers were removed from the prize list and replaced with a set of numbers with fixed cash prizes. At this point, the naming convention was also changed so that the trailing number would indicate the number of digits in the binary representation of the number.

55
Hence, RSA-640 has 640 binary digits, which translates to 193 digits in decimal. RSA numbers received widespread attention when a 129- digit number known as RSA-129 was used by R. Rivest, A. Shamir, and L. Adleman to publish one of the first public-key messages together with a $100 reward for the message's decryption (Gardner 1977). Despite widespread belief at the time that the message encoded by RSA-129 would take millions of years to break, it was factored in 1994 using a distributed computation which harnessed networked computers spread around the globe performing a multiple polynomial quadratic sieve (Leutwyler 1994). The corresponding factorization (into a 64-digit number and a 65-digit number) is
. Despite widespread belief at the time that the message encoded by RSA-129 would take millions of years to break, it was factored in 1994 using a distributed computation which harnessed networked computers spread around the globe performing a multiple polynomial quadratic sieve (Leutwyler 1994). The corresponding factorization (into a 64-digit number and a 65-digit number) is.")
56
x

57
RSA-129 is referred to in the Season 1 episode "Prime Suspect" of the television crime drama NUMB3RS. On Feb. 2, 1999, a group led by H. te Riele completed factorization of RSA-140 into two 70- digit primes. In a preprint dated April 16, 2004, Aoki et al. factored RSA-150 into two 75-digit primes. On Aug. 22, 1999, a group led by H. te Riele completed factorization of RSA-155 into two 78- digit primes (te Riele 1999b, Peterson 1999).
..")
58
When the numbers are very large, no efficient, non-quantum integer factorization algorithm is known; an effort concluded in 2009 by several researchers factored a 232-digit number (RSA-768), utilizing hundreds of machines over a span of 2 years. Kleinjung, et al (2010-02-18). Factorization of a 768-bit RSA modulus. International Association for Cryptologic Research
. Factorization of a 768-bit RSA modulus. International Association for Cryptologic Research.")
59
On December 2, Jens Franke circulated an email announcing factorization of the smallest prize number RSA-576 (Weisstein 2003). This factorization into two 87-digit factors was accomplished using a prime factorization algorithm known as the general number field sieve (GNFS). On May 9, 2005, the group led by Franke announced factorization of RSA-200 into two 100-digits primes (Weisstein 2005a), and in November 2005, the same group announced the factorization of RSA-674 (Weisstein 2005b). As the following table shows, RSA-704 to RSA-2048 remain open, carrying awards from ? to ? to whoever is clever and persistent enough to track them down.
. On May 9, 2005, the group led by Franke announced factorization of RSA-200 into two 100-digits primes (Weisstein 2005a), and in November 2005, the same group announced the factorization of RSA-674 (Weisstein 2005b). As the following table shows, RSA-704 to RSA-2048 remain open, carrying awards from . to . to whoever is clever and persistent enough to track them down..")
60
A list of the open Challenge numbers may be downloaded from RSA homepage

61
Number digits prize factored (references) RSA-100 100 Apr. 1991 RSA-110 110 Apr. 1992 RSA-120 120 Jun. 1993 RSA-129 129 Apr. 1994 (Leutwyler 1994, Cipra 1995) RSA-130 130 Apr. 10, 1996 RSA-140 140 Feb. 2, 1999 (te Riele 1999a) RSA-150 150 Apr. 6, 2004 (Aoki 2004) RSA-155 155 Aug. 22, 1999 (te Riele 1999b, Peterson 1999) RSA-160 160 Apr. 1, 2003 (Bahr et al. 2003) RSA-200 200 May 9, 2005 (see Weisstein 2005a) RSA-576 10000 Dec. 3, 2003 (Franke 2003; see Weisstein 2003) RSA-640 20000 Nov. 4, 2005 (see Weisstein 2005b) RSA-704 30000 open RSA-768 50000 open RSA-896 75000 open RSA-102 100000 open RSA-153 150000 open RSA-204 200000 open
 RSA Apr. 10, 1996 RSA Feb. 2, 1999 (te Riele 1999a) RSA Apr. 6, 2004 (Aoki 2004) RSA Aug. 22, 1999 (te Riele 1999b, Peterson 1999) RSA Apr. 1, 2003 (Bahr et al. 2003) RSA May 9, 2005 (see Weisstein 2005a) RSA Dec. 3, 2003 (Franke 2003; see Weisstein 2003) RSA Nov. 4, 2005 (see Weisstein 2005b) RSA open RSA open RSA open RSA open RSA open RSA open.")
62
An Example RSA numbers: 7 and 23 (public key: 55 is found) So, we'll take what's left and create the following character set (dictionary): 2 3 4 6 7 8 9 12 13 14 16 17 18 A B C D E F G H I J K L M 19 21 23 24 26 27 28 29 31 32 34 36 37 N O P Q R S T U V W X Y Z 38 39 41 42 43 46 47 48 49 51 52 53 sp 0 1 2 3 4 5 6 7 8 9 *
 So, we ll take what s left and create the following character set (dictionary): A B C D E F G H I J K L M N O P Q R S T U V W X Y Z sp *")
63
The message we will encrypt is "VENIO" (Latin for "I come"): V E N I O 31 7 19 13 21 To encode it, we simply need to raise each number to the power of P modulo R. V:31^7 (mod 55) = 27512614111 (mod 55) =26 E: 7^7 (mod 55) = 823543 (mod 55) =28 N:19^7 (mod 55) = 893871739 (mod 55) =24 I:13^7 (mod 55) = 62748517 (mod 55) = 7 O:21^7 (mod 55) = 1801088541 (mod 55) =21 So, our encrypted message is 26, 28, 24, 7, 21 -- or "RTQEO" in our personalized character set.
 = (mod 55) =26 E: 7^7 (mod 55) = (mod 55) =28 N:19^7 (mod 55) = (mod 55) =24 I:13^7 (mod 55) = (mod 55) = 7 O:21^7 (mod 55) = (mod 55) =21 So, our encrypted message is 26, 28, 24, 7, or RTQEO in our personalized character set..")
64
When the message "RTQEO" arrives on the other end of our insecure phone line, we can decrypt it simply by repeating the process -- this time using Q, our private key, in place of P. R:26^23 (mod 55) = 350257144982200575261531309080576 (mod 55) =31 T:28^23 (mod 55) =1925904380037276068854119113162752 (mod 55) = 7 Q:24^23 (mod 55) = 55572324035428505185378394701824 (mod 55) =19 E: 7^23 (mod 55) = 27368747340080916343 (mod 55) =13 O:21^23 (mod 55) = 2576580875108218291929075869661 (mod 55) =21 The result is 31, 7, 19, 13, 21 -- or "VENIO", our original message.
 = (mod 55) =31 T:28^23 (mod 55) = (mod 55) = 7 Q:24^23 (mod 55) = (mod 55) =19 E: 7^23 (mod 55) = (mod 55) =13 O:21^23 (mod 55) = (mod 55) =21 The result is 31, 7, 19, 13, or VENIO , our original message..")
Similar presentations





 Are the following sources likely to be stationary and ergodic? (i)Binary source, typical sequence aaaabaabbabbbababbbabbbbbabbbbaabbbbbba......>")
 from {a, b, c, d} encoded using the code shown what is the probability that a randomly chosen.>")





 CS414 – Spring 2007 By Karrie Karahalios, Roger Cheng, Brian Bailey.>")
 MODULE 12 ERROR DETECTION & CORRECTION.>")


 Source Coding and Compression>")



 general problem.>")



