Download presentation
Presentation is loading. Please wait.

1
Text Classification, Active/Interactive learning

2
Text Categorization Categorization of documents, based on topics When the topics are known – categorization (supervised) When the topics are unknown – classification (a.k.a clustering, unsupervised)
 When the topics are unknown – classification (a.k.a clustering, unsupervised)")
3
Supervised learning Training data – documents with their assigned (true) categories Documents are represented by feature vectors x=(x 1, x 2,…,x n )
 categories Documents are represented by feature vectors x=(x 1, x 2,…,x n )")
4
Document features Word frequencies Stems/lemmas Phrases POS tags Semantic features (concepts, named entities) tdidf : tf = term frequency idf = inverse document frequency
 tdidf : tf = term frequency idf = inverse document frequency")
5
TFIDF Weights TFIDF definitions: tf ik : #occurrences of term t k in document D i df k : #documents which contain t k idf k : log(d / df k ) where d is the total number of documents w ik : tf ik idf k term weight Intuition: rare words get more weight, common words less weight
 where d is the total number of documents w ik : tf ik idf k term weight Intuition: rare words get more weight, common words less weight")
6
Naïve Bayes classifier Tightly tied to text categorization Interesting theoretical properties A simple example of an important class of learners based on generative models that approximate how data is produced For certain special cases, NB is the best thing you can do

7
Bayes’ rule

8
Maximum a posteriori hypothesis As P(D) is constant
 is constant")
9
Maximum likelihood hypothesis If all hypotheses are a priori equally likely, we only need to consider the P(D|h) term:
 term:")
10
Naive Bayes classifiers Task: Classify a new instance D based on a tuple of attribute values into one of the classes c j C

11
Naïve Bayes assumption P(c j ) – Can be estimated from the frequency of classes in the training examples. P(x 1,x 2,…,x n |c j ) – O(|X| n |C|) parameters – Could only be estimated if a very, very large number of training examples was available. Naïve Bayes Conditional Independence Assumption: Assume that the probability of observing the conjunction of attributes is equal to the product of the individual probabilities P(x i |c j ).
 – O(|X| n |C|) parameters – Could only be estimated if a very, very large number of training examples was available. Naïve Bayes Conditional Independence Assumption: Assume that the probability of observing the conjunction of attributes is equal to the product of the individual probabilities P(x i |c j )..")
12
Naive Bayes for text categorization Attributes are text positions, values are words Still too many possibilities Assume that classification is independent of the positions of the words –Use same parameters for each position –Result is bag of words model (over tokens not types)
")
13
Text j single document containing all docs j for each word x k in Vocabulary –n k number of occurrences of x k in Text j – Naïve Bayes: learning probabilities From training corpus, extract Vocabulary Calculate required P(c j ) and P(x k | c j ) terms – For each c j in C do docs j subset of documents for which the target class is c j
 and P(x k | c j ) terms – For each c j in C do docs j subset of documents for which the target class is c j")
14
Naïve Bayes: classifying positions all word positions in current document which contain tokens found in Vocabulary Return c NB, where

15
Underflow Prevention

16
Binomial Naïve Bayes One feature X w for each word in dictionary X w = true in document d if w appears in d Naive Bayes assumption: Given the document’s topic, appearance of one word in the document tells us nothing about chances that another word appears

17
Parameter Estimation fraction of documents of topic c j in which word w appears Binomial model: Multinomial model: – Can create a mega-document for topic j by concatenating all documents in this topic – Use frequency of w in mega-document fraction of times in which word w appears across all documents of topic c j

18
Learning probabilities Passive learning – learning from the the annotated corpus Active learning – learning only from the most informative instances (real time annotation) Interactive learning – the annotator can choose to suggest specific features (e.g., playoffs to indicate sports) and not just complete instances
 Interactive learning – the annotator can choose to suggest specific features (e.g., playoffs to indicate sports) and not just complete instances")
19
https://github.com/burrsettles/dualist
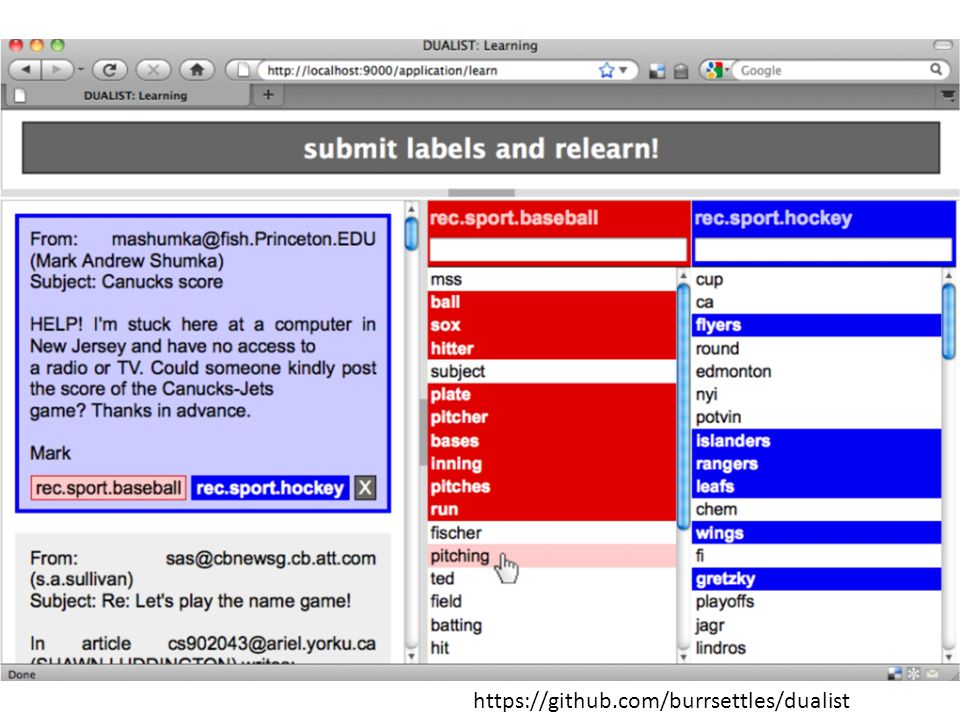
20
{Inter}active learning Available actions: – Annotate an instance with a class – Annotate a feature with a class – Suggest new feature and annotate it with a class

21
Adding prior to features’ max likelihood - Normalization factor (summing over all words)
")
22
Adding prior to classes’ max likelihood - Normalization factor (summing over all classes)
")
23
Semi-supervised (learning from unlabeled data) Learning model probabilities ( ) using only priors Apply the induced classifier on the unlabeled instances Re-estimate the probabilities using the labeled as well as the probabilistically labeled instances (multiply the latters with 0.1 to avoid over whelming the model) Possibly iterating this processes This is actually EM
 Learning model probabilities ( ) using only priors Apply the induced classifier on the unlabeled instances Re-estimate the probabilities using the labeled as well as the probabilistically labeled instances (multiply the latters with 0.1 to avoid over whelming the model) Possibly iterating this processes This is actually EM")
24
Suggesting instances for annotation Use weight function For example, entropy-based uncertainty weight: Then, suggest the top D documents Document d

25
Suggesting features for annotation Using info-gain Then, suggest the top V features for the class with which they occur most

26
Results of 3 annotators, comparing active, interactive and passive learning (Closing the Loop: Fast, Interactive Semi-Supervised Annotation With Queries on Features and Instances, Burr Settles)
")
Similar presentations









: diagnostic probability –P(Evidence | Cause): causal.>")



>")


>")
 Important work: –(Nigam and Ghani, 2000) –(Goldman and Zhou, 2000)>")

