Download presentation
Presentation is loading. Please wait.

1
Eurovoc and parliamentary documents: a semi-automatic classification experience at the Camera dei deputati Calogero Salamone Luxembourg, 19 november 2010

2
General Establishing techniques to allow citizens access to legal information is a matter of primary importance in terms of the fundamentals of public service Classification of parliamentary and legal resources provide an important support for research

3
History In 1969/1970, Italys Chamber of Deputies and Senate began to consider the classification of laws, in the context of early automation projects of the Parliament An Automatic machine dictionary of Italian language (Camera 72) was projected to be used for the information retrieval of legal texts
 was projected to be used for the information retrieval of legal texts")
4
History The project should have included a research system based on the storage of the full text of laws, decrees, treaties etc. dating back to 1848 An accurate legal-linguistic analysis was to establish a classification system to identify and resolve the problems of homographs, polysemy, shifts of meanings This project was abandoned

5
History In 1992 the thesaurus TESEO (TEsauro Senato per lOrganizzazione dei documenti parlamentari) was adopted for the classification of the bills database managed by the Senate The same thesaurus was adopted for the database of parliamentary oversight (Sindacato ispettivo) managed by the Chamber of deputies (questions to the government, motions and resolutions)
 was adopted for the classification of the bills database managed by the Senate The same thesaurus was adopted for the database of parliamentary oversight (Sindacato ispettivo) managed by the Chamber of deputies (questions to the government, motions and resolutions)")
6
History TESEO includes 3650 terms grouped into 45 thematic areas (Top Terms), derived from an old home-made classification system and arranged according to the logical structure of the Universal Decimal Classification (UDC) There are only 358 language equivalent terms (non-descriptors) used for cross-referencing
, derived from an old home-made classification system and arranged according to the logical structure of the Universal Decimal Classification (UDC) There are only 358 language equivalent terms (non-descriptors) used for cross-referencing")
7
From TESEO to EUROVOC The use of TESEO at Chamber of Deputies was overall satisfactory Difficulties were sometimes encountered in some areas due to the vagueness or absence of appropriate descriptors These problems led to creating a supplementary list with additional descriptors

8
From TESEO to EUROVOC In 2005 the Chamber began to consider whether to switch from TESEO to EUROVOC We considered inter alia the advantages of multilingual classification, including the possibility of connecting different legal and social phenomena under a single system of categorization

9
From TESEO to EUROVOC We also considered the larger number of descriptors available and the even bigger number of language equivalent terms (non- descriptors) available for the italian language There are some areas arranged in an EU perspective that can be difficult to use in a national perspective.
 available for the italian language There are some areas arranged in an EU perspective that can be difficult to use in a national perspective.")
10
From TESEO to EUROVOC We hope to gradually extend Classification through Eurovoc thesaurus from policy-setting and oversight documents to the whole information system Thats why we developed a map to match and link the descriptors of Eurovoc to those of TESEO

11
Automatic indexing We know that automatic classification processes do not achieve the same quality as human indexing does They can be efficient enough to be used for specific purposes, e.g. to automatically index documents that otherwise would not be indexed at all, or to support the process of human indexing

12
Automatic indexing The Chamber of deputies chose to test automatic indexing on policy-setting and oversight documents These are texts written in everyday language whose length is usually limited

13
Automatic indexing The application of automatic indexing to the classification of legislative texts is probably more difficult Legislative texts present a higher level of formalization of language and the consistency of documentary units that should be indexed (up to the level of the paragraphs), may probably be too short for the application of automated tools
, may probably be too short for the application of automated tools")
14
Automatic indexing The Chamber of Deputies decision to use an automated classification system was finalised in 2005 In an initial phase we started by testing automatic classification through TESEO descriptors In a second phase started in 2006, the program was set to automatic classification with Eurovoc thesaurus

15
Automatic indexing In 2008, with the beginning of the 16th Parliament, the Eurovoc classification of policy- setting and oversight documents of the Chamber of Deputies and the Senate was launched

16
Automatic indexing We selected a semantic technology solution (COGITO by Expert System), which automatically suggests a set of descriptors to be applied to each document Each document is analyzed and interpreted in order to be archived quickly in the corresponding category
, which automatically suggests a set of descriptors to be applied to each document Each document is analyzed and interpreted in order to be archived quickly in the corresponding category")
17
Automatic indexing The categorizer automatically analyzes each document and suggests a list of descriptors that could be used This list is checked, modified and validated by a professional operator

18
Automatic indexing The current procedure is in fact semi-automatic Automatic suggestions are modified and integrated (amended and supplemented) The operator is responsible for the selection and final results
 The operator is responsible for the selection and final results")
19
Automatic indexing So far, the classification suggested by Cogito categorizer has been used by transferring it manually to another application in order to record Eurovoc descriptors in the database used for research

20
Automatic indexing

25
History A new integrated application, Camer@voc, is now available, which enables the automatic Cogito categorizer to analyse all the texts, and then to revise them, as well as validate and record Eurovoc descriptors

26
History Camer@voc is a Web application created to manage the automatic classification of policy- setting and oversight documents The application also allows the management of various stages of classification and its history

27
History Camer@voc is entirely developed in an open source environment using three-tier architecture Applicative infrastructure is divided into three different modules dedicated respectively to the user interface (View), the functional logic also called business logic (Model) and the data persistence management (Controller)
, the functional logic also called business logic (Model) and the data persistence management (Controller)")
28
Automatic indexing Main functionalities: Sampling of new texts needing to be classified

29
Automatic indexing

30
Main functionalities: Display lists of documents automatically classified, divided by classification status

31
Automatic indexing

32
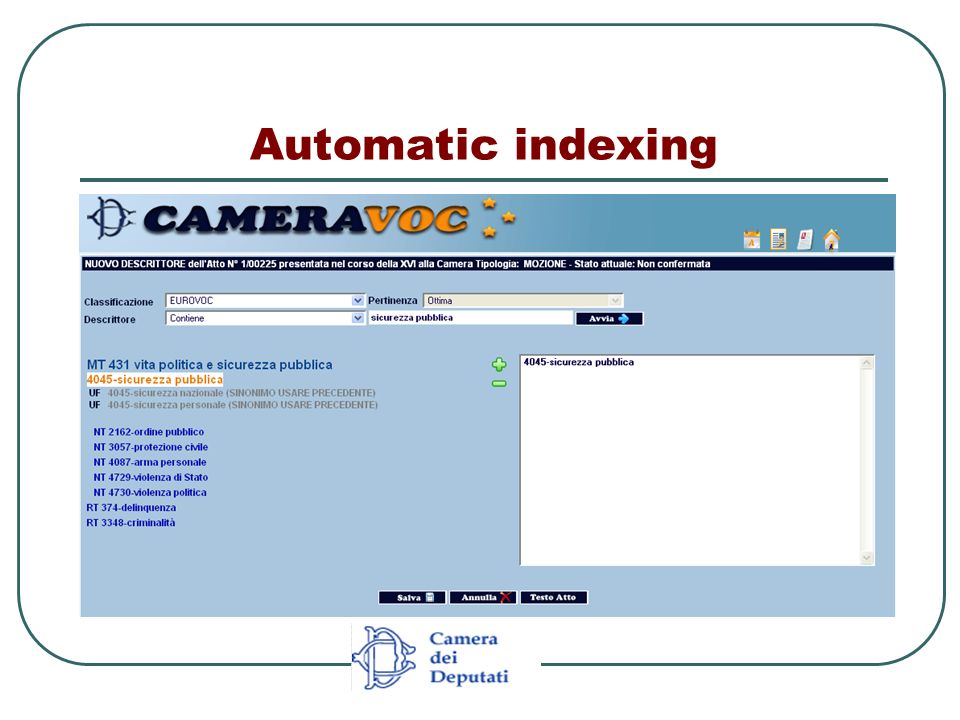
Main functionalities: Viewing and editing the automatic classification of a document; confirmation and subsequent storage of the final classification

33
Automatic indexing

35
Future developments include a phase of extensive and deep fine-tuning The aim is to check whether the system ultimately can lead to a high level of response so that it can be considered acceptable - even temporarily - without human intervention

36
Automatic indexing In case of positive results, we can consider the possibility of publishing automatic classification before revising it Users would be warned about this characteristic by a message like Classification to be reviewed

37
Questions to: salamone_c@camera.it

Similar presentations






 Linking DDC numbers.>")
















![MACHINE TRANSLATION TRANSLATION(5) LECTURE[1-1] Eman Baghlaf.](/19/5859755/big_thumb.jpg "MACHINE TRANSLATION TRANSLATION(5) LECTURE[1-1] Eman Baghlaf.>")