Download presentation
Presentation is loading. Please wait.

1
Decision Tree Evolution using Limited number of Labeled Data Items from Drifting Data Streams Wei Fan 1, Yi-an Huang 2, and Philip S. Yu 1 1 IBM T.J.Watson 2 Georgia Tech

2
Sad life cycle of inductive models Labeled Data Inductive Learner Inductive Model Decision Trees Rules Na ï ve Bayes Credit card transaction -> {fraud, normal} Un-labeled Real-time Streaming Data Predictions God knows the accuracy True Labels Accuracy too low!!!

3
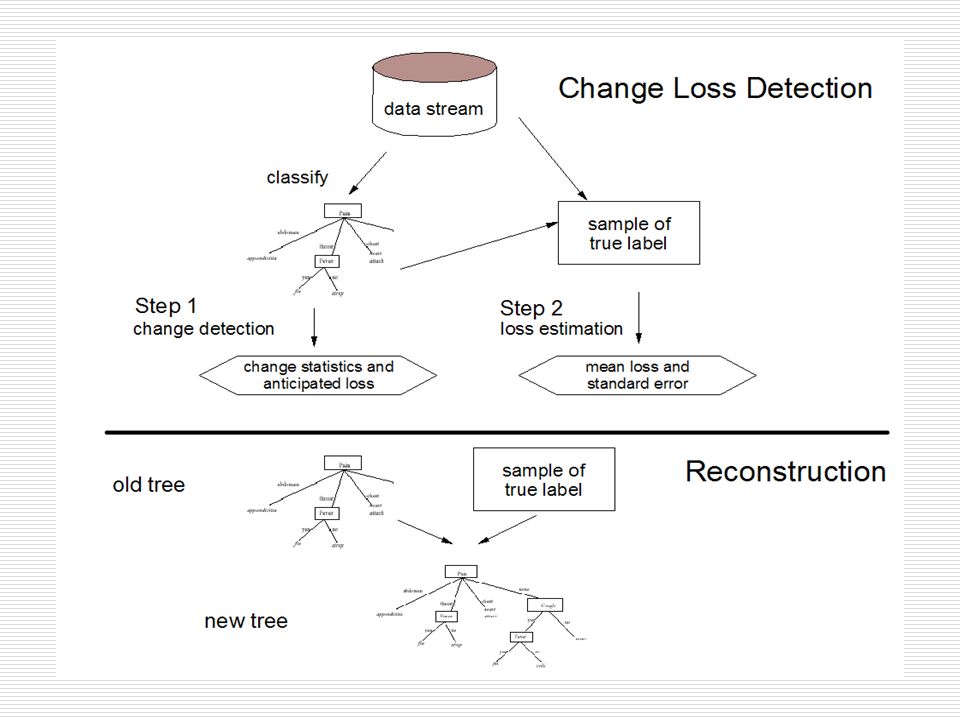
Seen any problems? Problem 1: we have no idea of the accuracy in the streaming environment. Problem 2: how long we can wait and how much we can afford to loose until we get labeled data?

5
Solutions Solution I: error guessing and estimation. Idea 1: using observable statistical traits from the model itself to guess the error on unlabeled streaming data. Idea 2: using very small number of specifically acquired examples to statistically estimate the error – similar to estimate poll to estimate Bush or Kerry will win the presidency. Details: Active Mining of Data Streams by Wei Fan, Yi-an Huang, and Philip S. Yu appearing in SDM 04.

6
Solutions Okay, assuming that we know that our model is too low in accuracy. Obviously, we need more accurate models. Solution II: We need to update our model with limited number of training examples We are interested in decision trees.

7
Decision Tree Example A < 100 B < 50C < 34 Y N +: 100 - : 400 P(+|x) = 0.2 +: 90 - : 10 P(-|x) = 0.1 y N
 = 0.2 +: 90 - : 10 P(-|x) = 0.1 y N")
8
Class Distribution Replacement If a node is considered suspicious using one of our detection techniques, we can perform class distribution replacement. The idea is that:

9
Class Distribution Replacement +: 100 - : 400 P(+|x) = 0.2 A < 100 B < 50C < 34 Y N +: 90 - : 10 P(-|x) = 0.1 y N Using limited number of examples, the new class distribution is P(+|x) = 0.4 P(+|x) = 0.4
 = 0.2 A < 100 B < 50C < 34 Y N +: 90 - : 10 P(-|x) = 0.1 y N Using limited number of examples, the new class distribution is P(+|x) = 0.4 P(+|x) = 0.4")
10
Some Statistics for Significance Test Proportion statistics: formula is in paper and many statistics books. Assume Gaussian distribution and compute significance

11
Leaf Expansion Assume that significance test in leaf expansion fails. Solution: reconstruct the leaf using limited number of examples. Catch: not always possible. If the limited number of examples cannot justify an expansion, just keep the original node.

12
Result on Class Distribution Replacement

13
Result on Leaf Node Expansion

14
More results in the paper Credit card fraud dataset. UCI Adult Dataset.

15
Conclusion Pointed out the gap between data availability and pattern change. Proposed a general framework. Proposed a few methods to update and grow a decision tree from limited number of examples.

Similar presentations