Download presentation
Presentation is loading. Please wait.

1
Inductive learning Simplest form: learn a function from examples
f is the target function An example is a pair (x, f(x)) Problem: find a hypothesis h such that h ≈ f given a training set of examples (This is a highly simplified model of real learning: Ignores prior knowledge Assumes examples are given)
) Problem: find a hypothesis h. such that h ≈ f. given a training set of examples. (This is a highly simplified model of real learning: Ignores prior knowledge. Assumes examples are given)")
2
Inductive learning method
Construct/adjust h to agree with f on training set E.g., curve fitting:

3
Inductive learning method
Construct/adjust h to agree with f on training set E.g., curve fitting:

4
Inductive learning method
Construct/adjust h to agree with f on training set E.g., curve fitting:

5
Inductive learning method
Construct/adjust h to agree with f on training set E.g., curve fitting:

6
Inductive learning method
Construct/adjust h to agree with f on training set E.g., curve fitting:

7
Inductive learning method
Construct/adjust h to agree with f on training set E.g., curve fitting: Ockham’s razor: prefer the simplest hypothesis consistent with data

8
Learning decision trees
Problem: decide whether to wait for a table at a restaurant, based on the following attributes: Alternate: is there an alternative restaurant nearby? Bar: is there a comfortable bar area to wait in? Fri/Sat: is today Friday or Saturday? Hungry: are we hungry? Patrons: number of people in the restaurant (None, Some, Full) Price: price range ($, $$, $$$) Raining: is it raining outside? Reservation: have we made a reservation? Type: kind of restaurant (French, Italian, Thai, Burger) WaitEstimate: estimated waiting time (0-10, 10-30, 30-60, >60)
 Price: price range ($, $$, $$$) Raining: is it raining outside Reservation: have we made a reservation Type: kind of restaurant (French, Italian, Thai, Burger) WaitEstimate: estimated waiting time (0-10, 10-30, 30-60, >60)")
9
Attribute-based representations
Examples described by attribute values (Boolean, discrete, continuous) E.g., situations where I will/won't wait for a table: Classification of examples is positive (T) or negative (F)
 E.g., situations where I will/won t wait for a table: Classification of examples is positive (T) or negative (F)")
10
Decision trees One possible representation for hypotheses
E.g., here is the “true” tree for deciding whether to wait:

11
Expressiveness Decision trees can express any function of the input attributes. E.g., for Boolean functions, truth table row → path to leaf: Trivially, there is a consistent decision tree for any training set with one path to leaf for each example (unless f nondeterministic in x) but it probably won't generalize to new examples Prefer to find more compact decision trees
 but it probably won t generalize to new examples. Prefer to find more compact decision trees.")
12
Hypothesis spaces How many distinct decision trees with n Boolean attributes? = number of Boolean functions = number of distinct truth tables with 2n rows = 22n E.g., with 6 Boolean attributes, there are 18,446,744,073,709,551,616 trees

13
3.1 Decision Trees An Algorithm for Building Decision Trees
1. Let T be the set of training instances. 2. Choose an attribute that best differentiates the instances in T. 3. Create a tree node whose value is the chosen attribute. -Create child links from this node where each link represents a unique value for the chosen attribute. -Use the child link values to further subdivide the instances into subclasses. 4. For each subclass created in step 3: If the instances in the subclass satisfy predefined criteria or if the set of remaining attribute choices for this path is null, specify the classification for new instances following this decision path. -If the subclass does not satisfy the criteria and there is at least one attribute to further subdivide the path of the tree, let T be the current set of subclass instances and return to step 2.

14
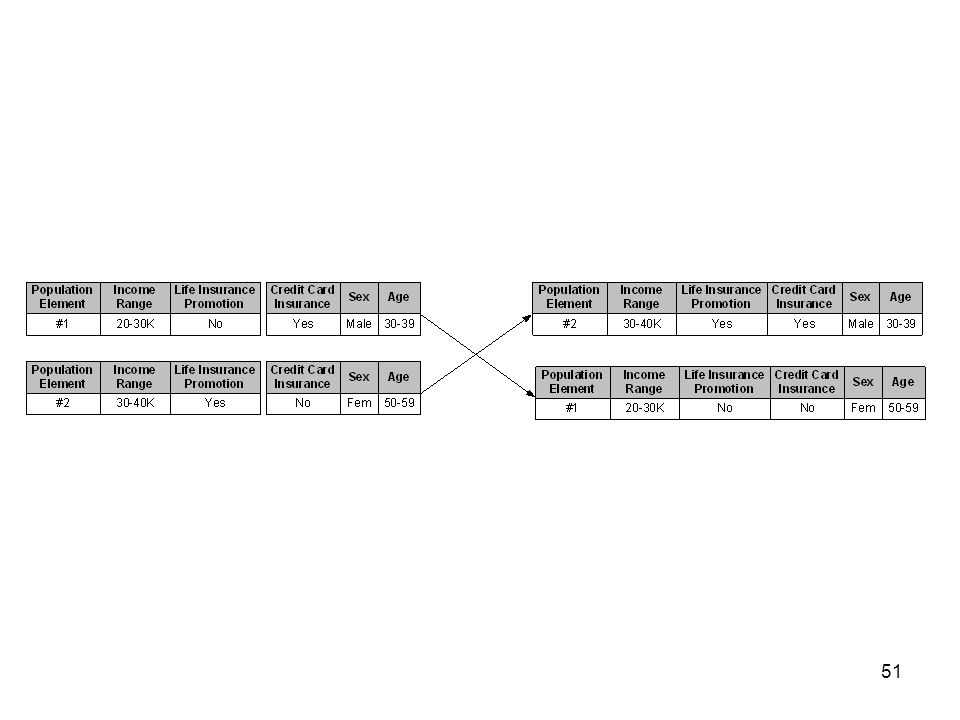
Table 3.1

16
Figure 3.1

19
Decision Trees for the Credit Card Promotion Database
Figure 3.4 Decision Trees for the Credit Card Promotion Database

20
Figure 3.5

22
Decision Tree Rules A Rule for the Tree in Figure 3.4
IF Age <=43 & Sex = Male & Credit Card Insurance = No THEN Life Insurance Promotion = No

23
A Simplified Rule Obtained by Removing Attribute Age
IF Sex = Male & Credit Card Insurance = No THEN Life Insurance Promotion = No

24
Other Methods for Building Decision Trees
CART CHAID

25
Advantages of Decision Trees
Easy to understand. Map nicely to a set of production rules. Applied to real problems. Make no prior assumptions about the data. Able to process both numerical and categorical data.

26
Disadvantages of Decision Trees
Output attribute must be categorical. Limited to one output attribute. Decision tree algorithms are unstable. Trees created from numeric datasets can be complex.

27
3.2 Generating Association Rules Confidence and Support

28
Rule Confidence Given a rule of the form “If A then B”, rule confidence is the conditional probability that B is true when A is known to be true.

29
Rule Confidence If customers purchase milk they also purchase bread
If customers purchase bread they also purchase milk

30
Rule Support The minimum percentage of instances in the database that contain all items listed in a given association rule.

31
Mining Association Rules: An Example

35
Two-item set rules IF Magazine Promotion = Yes
THEN Life Insurance Promotion = Yes (5/7)(5/10) IF Life Insurance Promotion = Yes THEN Magazine Promotion = Yes (5/5) (5/10)
(5/10) IF Life Insurance Promotion = Yes. THEN Magazine Promotion = Yes. (5/5) (5/10)")
36
Three-item sets Watch Promotion=No & Life Insurance Promotion=No & Credit Card Insurance=No

37
Three-item set rules IF Watch Promotion=No & Life Insurance Promotion=No THEN Credit Card Insurance=No (4/4) IF Watch Promotion = No THEN Life Insurance Promotion=No & Credit Card Insurance=No (4/6)
 IF Watch Promotion = No. THEN Life Insurance Promotion=No & Credit Card Insurance=No. (4/6)")
38
General Considerations
We are interested in association rules that show a lift in product sales where the lift is the result of the product’s association with one or more other products. We are also interested in association rules that show a lower than expected confidence for a particular association.

39
3.3 The K-Means Algorithm Choose a value for K, the total number of clusters. Randomly choose K points as cluster centers. Assign the remaining instances to their closest cluster center. Calculate a new cluster center for each cluster. Repeat steps 3-5 until the cluster centers do not change.

40
An Example Using K-Means

44
General Considerations
Requires real-valued data. We must select the number of clusters present in the data. Works best when the clusters in the data are of approximately equal size. Attribute significance cannot be determined. Lacks explanation capabilities.

45
3.4 Genetic Learning

46
Genetic Learning Operators
Crossover Mutation Selection

47
Genetic Algorithms and Supervised Learning

53
Genetic Algorithms and Unsupervised Clustering

56
General Considerations
Global optimization is not a guarantee. The fitness function determines the complexity of the algorithm. Explain their results provided the fitness function is understandable. Transforming the data to a form suitable for genetic learning can be a challenge.

57
3.5 Choosing a Data Mining Technique

58
Initial Considerations
Is learning supervised or unsupervised? Is explanation required? Neural networks, regression models are black-box What is the interaction between input and output attributes? What are the data types of the input and output attributes?

59
Further Considerations
Do We Know the Distribution of the Data? Many statistical techniques assume the data to be normally distributed Do We Know Which Attributes Best Define the Data? Decision trees and certain statistical approaches Neural network, nearest neighbor, various clustering approaches

60
Further Considerations
Does the Data Contain Missing Values? Neural networks Is Time an Issue? Decision trees Which Technique Is Most Likely to Give a Best Test Set Accuracy? Multiple model approaches (Chp. 11)
")
Similar presentations


































 Moh!>")
