Download presentation
Presentation is loading. Please wait.

1
Ontologizing the Ontolog Content
Protégé Workshop Denise A. D. Bedford, Ph.d. July 23, 2006

2
TaxoThesaurus Background
2 Ontolog TaxoThesaurus Working Group aims to: Establish a framework for developing an ontology that will focus on the current and future content of the Ontolog community, support a range of uses of the Ontolog and Ontolog-referenced content, by Ontolog members and non-members Provide a sustainable foundation for future variations in content, use and users - which is extensible without radical re-engineering going forward Provide a framework against which a basic set of functional architecture requirements can be defined – June discussion Provide a framework against which various semantic technologies might be positioned to support Ontolog - April and June discussions

3
TaxoThesaurus Background
3 Provide a basis for a case study in collaborative practice domain ontology development and management Provide a comparison – along the way – of the various ontology reference models If the group wishes – along the way – provide the community with guidance in positioning semantic solutions vis a vis semantic problems

4
Goal is not to… 4 Advocate one particular semantic approach over others because they all serve different purposes Provide a survey of or evaluate the individual technologies on the market today Suggest that any one person has a solution that works for everyone

5
Presentation Overview
Description of the Bottom Up Strategy Status Update on the Ontolog Ontologizing Work Expert Review and Evaluation of Ontolog Outputs (Workshop begins with this step…) Discussion of Next Steps and Invitation to Participate
 Discussion of Next Steps and Invitation to Participate.")
6
Part I. Description of the Bottom Up Approach

7
Workshop Overview Step 1. Describe the domain by brainstorming use, users and content to be ontologized Step 2. Identify the parameters of the ontology and describe their behavior Step 3. Identify semantic methods to support individual parameters Step 4. Take stock of architectural considerations Step 5. Generate values for the ontology parameters Step 6. Coordinate review and validation of ontology values Step 7. Operationalize ontology

8
Ontology Value Chain Content, Use, Users Definitions of Entities,
Describe Domain Ontology Parameters Architecture Issues Semantic Methods Generate Values Expert Review Operationalize Ontology Content, Use, Users Definitions of Entities, Attributes Classes, Relationships Application Requirements Strategy for Generating Values Ontology Raw Value Creation Ontology Refined Value Creation Working Ontology

9
Step 1. Describing the Domain

10
Describing the Domain Ontologies may involve semantic analysis, technologies, architecture, categorization, concept mapping and so forth Ultimately, though, they are about describing a domain so we should always begin with a general definition of the domain Domain may be a line of business or what we typically consider a subject domain Today we’ll work with the domain of ontologies - we will recognize very quickly that defining the domain is not easy and we will not agree on the definition until we have worked through several additional steps

11
Ontolog Domain We have focused the TaxoThesaurus project on the domain of ontologies since we have subject matter experts to work with and since we only have a few hours to walk through this exercise We will also take a bit of a shortcut and use the same boundaries to define our Ontology domain as are used to define the Ontolog Community of Practice

12
Describing the Domain 12 As a starting point, let’s work with framework which contains three essential components that will help us to better describe our domain: Domain Content Users Use/processes These basic reference points should help us to identify several scenarios and to understand the basic functional requirements our ontology will have to satisfy

13
The Context for an Ontolog Ontology
13 Users Use or Function Context Information (Document)
")
14
Users 14 May seem like the easiest dimension to address – but we need to make sure we have the same goals for the Ontolog ontology Do we assume that only Ontolog active members will be served by the ontology? Or, do we support all members and the general public who might be interested in joining the community or who might find the wiki content a valuable resource for learning? Are we assuming only ontolog-sophisticates or do we include general managers, novices, general public interest?

15
User Community Who Domain Knowledge Roles Ontolog Member Wiki
15 Who Domain Knowledge Roles Ontolog Member Wiki Wiki Manager Ontolog Member/Non-Member Ontology research & development Researchers, discussants, presenters, novices Computational linguistics Standards development work Participants, vendors, observers, implementors Metadata Creators, users, semantics developers, computational linguists Taxonomies Creators, designers, users, semantics developers, computational linguists Information Architecture Engineers, information scientists Semantic Technologies Developers, users, implementors, linguists, novices

16
Use and Context 16 It is challenging for people who are so familiar with ontology development and semantic technologies to step back and think about how an ontology would actually support our use of the Ontolog content But, this is a critical first step – without understanding the use and context, we cannot establish a baseline ontology Without understanding use and context we will forever argue about which model works best, which tools work best and who should do what – actually, there is room for variation and negotiation here Following tables are the result of some brainstorming and observations from the Ontolog community itself

17
Possible Uses of Ontolog Content
17 Doing What Find Person who knows something about an issue Browse Issues that Ontolog has discussed All people who participated in a discussion Learn About Reference models discussed by Ontolog Get list of Problems Ontolog identified that need attention Collections by topic Search Future conference call topics

18
Possible Uses of Ontolog Content
18 Doing What Search Next scheduled call Specific message Find List of all members of Ontolog Specific Ontolog member Reference to ontology standards Book references Organizations working in this area

19
Possible Uses of Ontolog Content
19 Doing What Find Upcoming conferences & participants Generate Knowledge map of who knows what in Ontologies Map of the social networking in Ontolog Publish review of a new book Start Discussion of a new topic Annotate/summarize Discussion thread Others??

20
Content 20 In order to understand the content the Taxo-Thesaurus Project Team ran an inventory of all the content published to or contained in the Wiki The Ontolog Use Case surfaced over 65,000 content objects (some of which were versions of the same object) The inventory gave us a better sense of the kinds of content available in the domain and an accurate picture of what was covered in the existing repository We discovered that not all of the kinds of content that belong to the broader domain of Ontologies are accessible in or from the Wiki, though. This includes people, organizations, as well as other kinds of static information content We need to add content to the domain
 The inventory gave us a better sense of the kinds of content available in the domain and an accurate picture of what was covered in the existing repository. We discovered that not all of the kinds of content that belong to the broader domain of Ontologies are accessible in or from the Wiki, though. This includes people, organizations, as well as other kinds of static information content. We need to add content to the domain.")
21
Sample Coast Content Inventory

22
First Cut at Ontolog Content
22 Ontolog People profiles/pages Ontolog presentations Ontolog discussion threads Ontolog concepts Ontolog Activity Calendar Ontolog Conference call notes Ontolog Conference call agendas Ontolog Conference call minutes Ontolog Conference call transcripts messages Discussion threads/forums Professional Conference schedules & announcements Professional Conference representation Books on ontology topics Published articles on ontology topics Reviews of books on ontologies Ontology standards Professional organizations Research institutions Wiki search logs

23
Describing the Domain At the end of this Step we have a basic idea of what kinds of content the ontology will have to cover, the kinds of entities it will have to include, and the kinds of relationships and concepts that will be needed to support functionality We are now ready to begin to specify the parameters of the ontology

24
Step 2. Identify the Parameters of the Ontology

25
Definition of Ontology
“Data model that represents a domain and is used to reason about the objects in that domain and the relationships between them. Ontologies are used in artificial intelligence, the semantic web, software engineering and information architecture as a form of knowledge representation about the world or some part of it. Ontologies generally describe: Entities Classes Attributes Relations” (source – Wikipedia)
")
26
Ontology Architecture Begins to Emerge
26 uses Contextual Matrix & Sensiing Understood in Business Rule Has Use Ontolog Topic Class Scheme Has Meaning in Content Entity Definition User Authority Control – Member Names Has values Has relationship to Thesaurus of Ontolog Concepts Metadata Profile Has Has Has uses Content Elements Content Model Areas of Expertise Profile Has Authority Contro – Organizations Has values Content Elements Aggregation Levels Contains Content

27
Entities in the Ontolog Domain Include…
People Institutions Communities of Practice Journal articles Books Discussion threads Presentations Standards Project proposals Memoranda of Understanding Conference announcements Conference presentations Research grant program descriptions Research reports Conference call notes Conference call tapes …..many others

28
Attributes Include... Ideally, we would model all of these entities at least at a high level The models of these entities would include: Attributes of entities as structured content (structured data) Content elements (semi- or unstructured content) Value added metadata
 Content elements (semi- or unstructured content) Value added metadata.")
29
More Advanced Entity Models
When we began describing content about ten years ago, we went to a more granular level We defined data models for our entities Ideally, you will also take the effort to the entity data model level Following is an example of a data model for a communique We also defined data models for people, institutions, countries, projects, many types of knowledge, for document types, communications (drawing on news schema), etc. Taking it to this level enables you to apply the ontology at a more granular level and to increase the goodness of your application
, etc. Taking it to this level enables you to apply the ontology at a more granular level and to increase the goodness of your application.")
30
Content Data Model Example – Event, Communique
30

31
In order for Ontolog to support….
Search We need to know the parameters users will search by (for who, what, where, when, how…) We need to understand the behavior and semantic challenges of those parameters (author names and variations, affiliations, facets of domains, dates, …) Knowledge mapping of Ontolog members We need to know who is a member of the Ontolog CoP We need to know general areas of expertise in order to describe the mebers consistently knowledge We need to know their names and variations of their names, We need to know their affiliations (organizational names)
 We need to understand the behavior and semantic challenges of those parameters (author names and variations, affiliations, facets of domains, dates, …) Knowledge mapping of Ontolog members. We need to know who is a member of the Ontolog CoP. We need to know general areas of expertise in order to describe the mebers consistently knowledge. We need to know their names and variations of their names, We need to know their affiliations (organizational names)")
32
In order for Ontolog to support….
Navigation/browse by novices and experts We need to know how to organize the content for easy access. By domain facet? By topic? By country? How to organize facets to facilitate expert and novice access. How to maintain the reference sources that support facets. Easily access at the concept level by managers and others who may not have technical expertise… What we discovered when we did the inventory was that 90%+ of the Ontolog content is technical in nature Our expectation that non-technical managers would use the content to understand the value of ontologies does not hold now We need to include more non-technical content and we need to bridge the technical/non-technical vocabulary

33
Understanding Semantic Behavior of Attributes
My experience suggests that before we can successfully apply semantic technologies in an ontology context, we need to understand the behavior of the attributes There are many different kind of semantic methods and it is important to match the right solution to the problem Let’s think about some of the semantic challenges we find in some typical attributes Person’s name Organization name Country name Class scheme Concepts

34
People Name Challenges
People names vary in different ways Over time as names change with life events Denise Ann Dowding Denise Ann Dowding Bedford In their format depending on context D. Bedford D. A. D. Bedford Denise D. Bedford Denise A. Bedford Denise A. D. Bedford Common versus formal names Denny vs. Denise Raju vs. Rajendra vs. Natarajan Need to link all semantic equivalents in the ontology

35
Class Schemes & Classification Problems
Have inheritance structures which must be respected Classes may experience scope changes Classes may appear or be archived over time May be insufficiently comprehensive in coverage of the domain Classification Human classification tends to suffer from inconsistencies due to limited perspectives, variations in perception, and variations over time Classes need to be comprehensively represented across the domain and managed consistently over time Classification needs to be performed consistently

36
Geographic Names Variations in country names occur
Over time as political context changes Armenia Soviet Socialist Republic of Armenia By perspective and tradition New Delhi or Chennai Mombay or Bombay All variations need to be linked as equivalencies or they need to be linked as predecessor/successor forms in an authority controlled context

37
Concept Challenges Primary challenges with concepts are based on:
Concept as a word unit – as defined in dictionaries or word compendiums (WordNet) Girls, education Sediment, transport Concept as a multiword unit – idea as identified in glossaries, thesauri Girls education Sediment transport True concepts are defined at the multiword level Need to be able to understand the linguistic nature of the language in order to discover concepts
 Girls, education. Sediment, transport. Concept as a multiword unit – idea as identified in glossaries, thesauri. Girls education. Sediment transport. True concepts are defined at the multiword level. Need to be able to understand the linguistic nature of the language in order to discover concepts.")
38
Quick Taxonomy Primer Before we can begin to model and/or solve semantic problems programmatically, we need to understand the structure and behavior of taxonomies There are five types of taxonomies: Flat taxonomies (controlled lists) Hierarchical taxonomies (class schemes) Ring taxonomies (synonym, equivalencies) Network taxonomies (thesauri, semantic networks) Faceted taxonomies (aspects, metadata)
 Hierarchical taxonomies (class schemes) Ring taxonomies (synonym, equivalencies) Network taxonomies (thesauri, semantic networks) Faceted taxonomies (aspects, metadata)")
39
Flat Taxonomy Structure
Energy Environment Education Economics Transport Trade Labor Agriculture

40
Hierarchical Taxonomy
A hierarchical taxonomy is represented as a tree data structure in a database application. The tree data structure consists of nodes and links. In an RDBMS environment, the relationships become associations. In a hierarchical taxonomy, a node can have only one parent.

41
Network Taxonomies A network taxonomy is a plex data structure. Each node can have more than one parent. Any item in a plex structure can be linked to any other item. In plex structures, links can be meaningful & different.

42
Ring Taxonomy Poverty mitigation Poverty alleviation Poverty reducation Poverty elimination Poverty prevention Poverty abatement Poverty reduction Rings can include all kinds of synonyms - true, misspellings, predecessors, abbreviations Poverty eradication

43
Facet Taxonomies Faceted taxonomy represented
as a star data structure. Each node in the start structure is liked to the center focus. Any node can be linked to other nodes in other stars. Appears simple, but becomes complex quickly.

44
Step 3. Architectural Considerations

45
Functional Architecture & Requirements
The focus of the workshop is not to discuss the architecture to support an ontology Instead, we simply highlight this step to emphasize the importance of stopping at this point in the process to focus on how you will support use of the ontology This is where varying assumptions may cause a breakdown in agreements within groups Some may presume that an ontology will be applied on top of content dynamically Others may presume that the ontology will be embedded into a more formal enterprise architecture

46
Functional Requirements Begin to Emerge
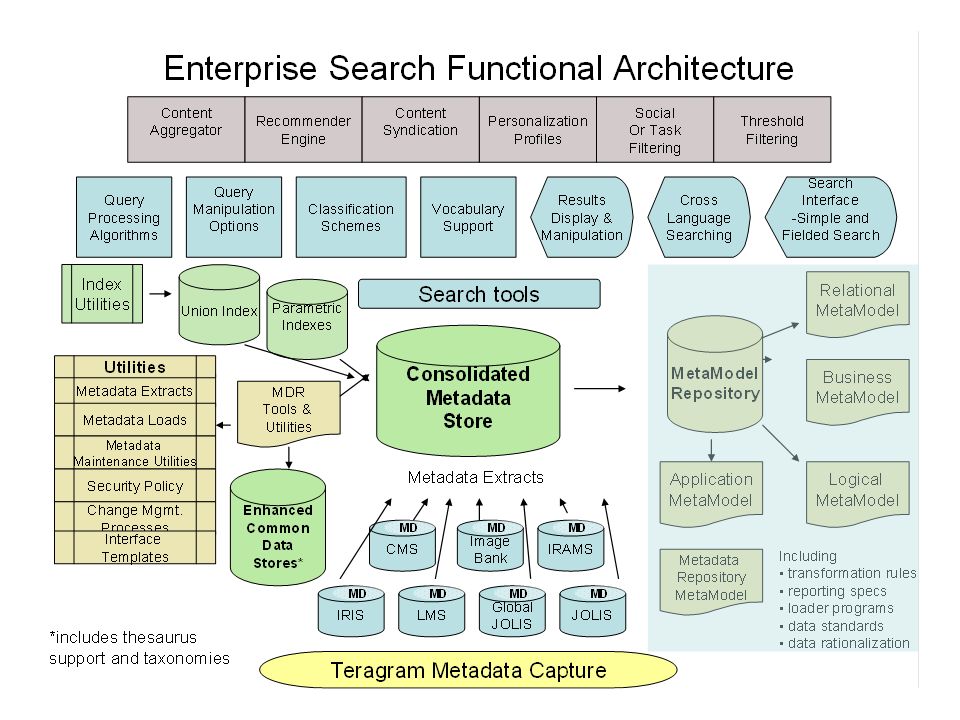
46 At this stage functional requirements and architecture issues begin to surface. In the WB context, we realized we needed: Metadata schema Different kinds of taxonomies (controlled lists, rings, hierarchies, concept networks) Semantic analysis tools to support metadata capture Metadata encoding options (xml, rdf, etc.) Metadata storage options (e.g. embedded in document, distinct database, etc.) Search system which supports attribute searching & which leverages reference sources Browse structure Reporting Data mining and clustering Other more sophisticated inference and reasoning options to support contextualization, business intelligence, and expert systems/inferencing engines and
 Semantic analysis tools to support metadata capture. Metadata encoding options (xml, rdf, etc.) Metadata storage options (e.g. embedded in document, distinct database, etc.) Search system which supports attribute searching & which leverages reference sources. Browse structure. Reporting. Data mining and clustering. Other more sophisticated inference and reasoning options to support contextualization, business intelligence, and expert systems/inferencing engines and.")
48
Step 4. Identify Semantic Methods to Generate Ontology Values

49
Reality of Ontolgy Values
Ontologies are grounded on structures, definitions, relationships and VALUES Without VALUES you don’t have an ontology The problem is that generating values is very resource intense and no one has sufficient human resources to support this work Solution is to leverage semantic technologies to generate values for ontologies As we saw in Step 3, there are different kinds of semantic problems that require different kinds of solutions Challenge is finding the right semantic solution to fit the semantic problem

50
Ontolog Values Today we will share with you for your review and critique some programmatically generated values for entities, attributes, concepts and reference sources Before we do that, though, we’d like to describe how we used semantic technologies to generate the outputs Before we describe the technologies and how we used them, though, it might be important to distinguish two basic types of approaches

51
NLP Technologies – Two Approaches
Over the past 50 years, there have been two competing strategies in NLP - statistical vs. semantic In the mid-1990’s at the AAAI Stanford Spring Workshops it was agreed by the active practitioners that the statistical NLP approach had hit a rubber ceiling – there were no further productivity gains to be made from this approach About that time, the semantic approach showed practical gains – we have been combining the two approaches since the late 1990’s Teragram supports both approaches but is a semantic technology at base – this is the best configuration and it provides the greatest flexibility.

52
Statistical NLP Statistical Approach uses statistical regression and Bayesian modeling methods to find patterns in words. This approach treats words as if they are ‘data’ – it breaks text down into single-word tokens and then tries to find similar tokens. There is no attempt to understand or detect meaning in the words – they are only characters/digits in strings. It then runs statistical analysis to find ‘co-occurring tokens’ The problem with this approach is that it works only at the word or word fragment level and you never get to a higher level of understanding from this baseline. This approach helps you to learn that ‘girls’ and ‘education’ are related – but, we don’t need a statistical tool to tell us this – we already know this and can represent it as a concept (vs. a word)
")
53
Problem with Statistical NLP
We experimented with several of these tools in the early 2000s – including Autonomy, Semio, Northern Lights Clustering We saw the following known effects -- the statistical associations you generate are entirely dependent upon the frequency at which they occur in the training set Without a semantic base you cannot distinguish types of entities, attributes, concepts or relationships If the training set is not representative of your universe, your relationships will not be representative and you cannot generalize from the results If the universe crosses domains, then the words that have the greatest commonality (least meaning) have the greatest association value
 have the greatest association value.")
54
Semantic NLP For years, people thought the semantic could not be achieved so they relied on statistical methods The reason they thought it would never be practical is that it took a long time to build the foundation – understanding human language is not a trivial exercise Building a semantic foundation involves: developing grammatical and morphological rules – language by language Using parsers and Part of Speech (POS) taggers to semantically decompose text into semantic elements Building dictionaries or corpa for individual languages as fuel for the semantic foundation to run on Making it all work fast enough and in a resource efficient way to make it economically practical
 taggers to semantically decompose text into semantic elements. Building dictionaries or corpa for individual languages as fuel for the semantic foundation to run on. Making it all work fast enough and in a resource efficient way to make it economically practical.")
55
Example of Semantic Analysis

56
Getting Semantic with Computational Linguistics
Computational linguistics is an interdisciplinary field dealing with the logical modeling of natural language from a computational perspective Computational linguistics puts the semantic in natural language processing. Computational linguistics predates artificial intelligence - originated with efforts in the United States in the 1950s to have computers automatically translate texts in foreign languages into English, particularly Russian scientific journals. This work was finally brought to a practical level in the 1980s with the joint NASA-Russian Soyuz Space Station work. The first product we looked at in 1998 was NASA’s MAI toolset It has taken us 50 years to get where we are today – and Teragram provides us with some practical NLP capabilities.

57
How We Used the Semantic Technologies
Teragram is a set of multilingual natural language processing (NLP) technologies that use the representation and meaning of text to distill relevant information from vast amounts of data. Teragram’s Natural Language Processing technologies include: Rules Based Concept Extraction (also called classifier) Grammar Based Concept Extraction Categorization Summarization Clustering Language detection The package consists of a developers client (TK240) and multiple servers to support the technologies We have taken this basic ‘technology toolkit’ and implemented it in a way that supports programmatic metadata capture and is consistent with good practice data quality and data management
 technologies that use the representation and meaning of text to distill relevant information from vast amounts of data. Teragram’s Natural Language Processing technologies include: Rules Based Concept Extraction (also called classifier) Grammar Based Concept Extraction. Categorization. Summarization. Clustering. Language detection. The package consists of a developers client (TK240) and multiple servers to support the technologies. We have taken this basic ‘technology toolkit’ and implemented it in a way that supports programmatic metadata capture and is consistent with good practice data quality and data management.")
58
Rule Based Concept Extraction
What is it? Rule based concept or entity extraction is a simple pattern recognition technique which looks for and extracts named entities Entities can be anything – but you have to have a comprehensive list of the names of the entities you’re looking for How does it work? It is a simple pattern matching program which compares the list of entity names to what it finds in content Regular expressions are used to match sets of strings that follow a pattern but contain some variation List of entity names can be built from scratch or using existing sources – we try to use existing sources A rule-based concept extractor would be fueled by a list such as Working Paper Series Names, edition or version statement, Publisher’s names, etc. Generally, concept extraction works on a “match” or “no match” approach – it matches or it doesn’t Your list of entity names has to be pretty good

59
Rule Based Concept Extraction
How do we build it? Create a comprehensive list of the names of the entities – most of the time these already exist, and there may be multiple copies Review the list, study the patterns in the names, and prune the list Apply regular expressions to simplify the patterns in the names Build a Concept Profile Run the concept profile against a test set of documents (not a training set because we build this from an authoritative list not through ‘discovery’) Review the results and refine the profile State of Industry The industry is very advanced – this type of work has been under development and deployed for at least three decades now. It is a bit more reliable than grammatical extraction, but it takes more time to build.
 Review the results and refine the profile. State of Industry. The industry is very advanced – this type of work has been under development and deployed for at least three decades now. It is a bit more reliable than grammatical extraction, but it takes more time to build.")
60
Rules Based Concept Extraction Examples
Loan # Credit # Report # Trust Fund # ISBN, ISSN Organization Name (companies, NGOs, IGOs, governmental organizations, etc.) Address Phone Numbers Social Security Numbers Library of Congress Class Number Document Object Identifier URLs ICSID Tribunal Number Edition or version statement Series Name Publisher Name Let’s look at the Teragram TK240 profiles for Organization Names, Edition Statements, and ISBN
 Address. Phone Numbers. Social Security Numbers. Library of Congress Class Number. Document Object Identifier. URLs. ICSID Tribunal Number. Edition or version statement. Series Name. Publisher Name. Let’s look at the Teragram TK240 profiles for Organization Names, Edition Statements, and ISBN.")
61
ISBN Concept Extraction Profile – Regular Expressions (RegEx)
Replace this slide with the ISBN screen – with the rules displayed Concept based rules engine allows us to define patterns to capture other kinds of data Use of concept extraction, regular expressions, and the rules engine to capture ISBNs. Regular expressions match sets of strings by pattern, so we don’t need to list every exact ISBN we’re looking for.

62
List of entities matches exact strings
List of entities matches exact strings. This requires an exhaustive list– but gives us extensive control. (It would be difficult to distinguish by pattern between IGOs and other NGOs.) Classifier concept extraction allows us to look for exact string matches
 Classifier concept extraction allows us to look for exact string matches.")
63
Another list of entities matches exact strings
Another list of entities matches exact strings. In this case, though, we’re making this into an ‘authority control list’– We’re matching multiple strings to the one approved output. (In this case, the AACR2-approved edition statement.)
")
64
Grammatical Concept Extractions
What is it? A simple pattern matching algorithm which matches your specifications to the underlying grammatical entities For example, you could define a grammar that describes a proper noun for people’s names or for sentence fragments that look like titles How does it work? This is also a pattern matching program but it uses computational linguistics knowledge of a language in order to identify the entities to extract – if you don’t have an underlying semantic engine, you can’t do this type of extraction There is no authoritative list in this case – instead it uses parsers, part-of-speech tagging and grammatical code The semantic engine’s dictionary determines how well the extraction works – if you don’t have a good dictionary you won’t get good results There needs to be a distinct semantic engine for each language you’re working with

65
Grammatical Concept Extractions
How do we build it? Model the type of grammatical entity we want to extract and use the grammar definitions to build a profile Test the profile on a set of test content to see how it behaves Refine the grammars Deploy the profile State of Industry It has taken decades to get the grammars for languages well defined There are not too many of these tools available on the market today but we are pushing to have more open source Teragram now has grammars and semantic engines for 30 different languages commercially available IFC has been working with ClearForest Let’s look at some examples of grammatical profiles – People’s Names, Noun Phrases, Verb Phrases, Book Titles

66
TK240 Grammars for People Names
Grammar concept extraction allows us to define concepts based on semantic language patterns.

67
Grammatical Concept Extraction
Proper Noun Profile for People Names uses grammars to find and extract the names of people referenced in the document. <?xml version="1.0" encoding="UTF-8"?> <Proper_Noun_Concept> <Source><Source_Type>file</Source_Type> <Source_Name>W:/Concept Extraction/Media Monitoring Negative Training Set/ 001B950F2EE8D0B B4003FF816.txt</Source_Name> </Source><Profile_Name>PEOPLE_ORG</Profile_Name> <keywords>Abdul Salam Syed, Aruna Roy, Arundhati Roy, Arvind Kesarival, Bharat Dogra, Kwazulu Natal, Madhu Bhaduri, </keywords><keyword_count>7</keyword_count> </Proper_Noun_Concept>

68
Grammatical Concept Extraction – People Names Client testing mode

69
Rule-Based Categorization
What is it? Categorization is the process of grouping things based on characteristics Categorization technologies classify documents into groups or collections of resources An object is assigned to a category or schema class because it is ‘like’ the other resources in some way Categories form part of a hierarchical structure when applied to such subjects as a taxonomy How does it work? Automated categorization is an ‘inferencing’ task- meaning that we have to tell the tools what makes up a category and then how to decide whether something fits that category or not We have to teach it to think like a human being – When I see -- access to phone lines, analog cellular systems, answer bid rate, answer seizure rate – I know this should be categorized as ‘telecommunications’ We use domain vocabularies to create the category descriptions

70
Rule Based Categorization
How do we build it? Build the hierarchy of categories Manually if you have a scheme in place and maintained by people Programmatically if you need to discover what the scheme should be Build a training set of content category by category – from all kinds of content Describe each category in terms of its ‘ontology’ – in our case this means the concepts that describe it (generally between 1,000 and 10,000 concepts) Filter the list to discover groups of concepts The richer the definition, the better the categorization engine works Test each category profile on the training set Test the category profile on a larger set that is outside the domain Insert the categirt profile into the profile for the larger hierarchy We built the Ontolog classification scheme using the programmatic approach – reference materials include the raw and refined lists, plus the ‘discovered classes’
 Filter the list to discover groups of concepts. The richer the definition, the better the categorization engine works. Test each category profile on the training set. Test the category profile on a larger set that is outside the domain. Insert the categirt profile into the profile for the larger hierarchy. We built the Ontolog classification scheme using the programmatic approach – reference materials include the raw and refined lists, plus the ‘discovered classes’")
71
Rule Based Categorization
State of the Industry Only a handful of rule-based categorizers are on the market today Most of the existing technologies are dynamic clustering tools However, the market will probably grow in this area as the demand grows

72
Categorization Examples
Let’s look at some working examples by going to the Teragram TK240 profiles Topics Countries Regions Sector Theme Disease Profiles Other categorization profiles we’re also working on… Business processes (characteristics of business processes) Sentiment ratings (positive media statements, negative media statements, etc.) Document types (by characteristics found in the documents) Security classification (by characteristics found in the documents)
 Sentiment ratings (positive media statements, negative media statements, etc.) Document types (by characteristics found in the documents) Security classification (by characteristics found in the documents)")
73
Topic Hierarchy From Relationships across data classes
Build the rules at the lowest level of categorization

74
Domain concepts or controlled vocabulary
Subtopics Domain concepts or controlled vocabulary

75
Topics Categorization Client Test

76
Automatically Generated XML Metadata

77
Automatically Generated Metadata

78
Automatically Generated XML Metadata for Business Function attribute
Office memorandum on requesting CD’s clearance of the Board Package for NEPAL: Economic Reforms Technical Assistance (ERTA)
")
79
Clustering vs. Categorization
Clustering Categorization

80
Clustering What is it? The use of statistical and data mining techniques to partition data into sets. Generally the partitioning is based on statistical co-occurrence of words, and their proximity to or distance from each other How does it work? Those words that have frequent occurrences close to one another are assigned to the same cluster Clusters can be defined at the set or the concept level – usually the latter Can work with a raw training set of text to discover and associate concepts or to suggest ‘buckets’ of concepts Some few tools can work with refined list of concepts to be clustered against a text corpus Please note the difference between clustering words in content and clustering domain concepts – major distinction

81
Clustering How do we build it? Define the list of concepts
Create the training set Load the concepts into the clustering engine Generate the concept clusters State of Industry Most of the commercial tools that call themselves ‘categorizers’ are actually clustering engines Generally, doesn’t work at a high domain level for large sets of text They can provide insights into concepts in a domain when used on a small set of documents All the engines are resource intense, though, and the outputs are transitory – clusters live only in the cluster index If you change the text set, the cluster changes

82
Clustering Concepts This is from the clustering output for Wildlife Resources. ‘Clusters’ of concepts between line breaks are terms from the Wildlife Resources controlled vocabulary found co-occurring in the same training document. This highlights often subtle relationships.

83
Clustering Words in Content
Clusters of words based on occurrences in the content

84
Summarization What is it?
Rule-driven pattern matching and sentence extraction programs Important to distinguish summarization technologies from some information extraction technologies - many on the market extract ‘fragments’ of sentences – what Google does when it presents a search result to you Will generate document surrogates, poiint of view summaries, HTML metatag Description, and ‘gist’ or ‘synopsis’ for search indexing Results are sufficient for ‘gisting’ for html metatags, as surrogates for full text document indexing, or as summaries to display in search results to give the user a sense of the content How does it work? Uses rules and conditions for selecting sentences Enables us to define how many sentences to select Allows us to tell us the concepts to use to select sentences Allows us to determine where in the sentence the concepts might occur Allows us to exclude sentences from being selected We can write multiple sets of rules for different kinds of content

85
Summarization How do we build it?
Analyze the content to be summarized to understand the type of speech and writing used – IRIS is different from Publications is different from News stories Identify the key concepts that should trigger a sentence extraction Identify where in the sentence these concepts are likely to occur Identify the concepts that should be avoided Convert concepts and conditions to a rule format Load the rule file onto the summarization server Test the rules against test set of content and refine until ‘done’ Launch the summarization engine and call the rule file State of Industry Most tools are either readers or extractors. Reader method uses clustering & weighting to promote sentence fragments. Extractor method uses internal format representation, word & sentence weighting What has been missing from the Extractors in most commercial products is the capability to specify the concepts and the rules. Teragram is the only product we found to support this.

86
Where would appear in the sentence It is likely to be included
Summarization Rules Code Where would appear in the sentence It is likely to be included Syntax 5 anywhere in the sentence It is likely not to be included copyright/2004,5 9 Definitely not included for/example,9 7 Definitely to be included got/the/top/grade,7 10 pull/off/that/coup,10 2 anywhere in the sentence, followed by the second evidence,2:collected 1 beginning of the sentence we/report,1 6 reporting/on,6 8 copyright/reserved,8 3 beginning of the sentence; only if the preceding sentence qualifies however,3 4 the/former,4

87
Automatically Generated Gist
PID Bosnia-Herzegovina Private Sector Credit Project Rules agreed/to,10 with/the/objective,10 objective,2:project proposed,2:project assist/in,10 Gist

88
Step 5. Generate Values for the Ontolog Ontology

89
Sample Dimensions of Ontolog Ontology
Names of organizations and companies (Rule based concept extraction) Names of people (Grammar based concept extraction) Countries (Rule based categorization) Ontology facets or subdomains (Grammar based concept extraction + rule based categorization) – Attachment #1 Domain Vocabulary/Concept Lists (Grammar based concept extraction) – Attachment #2
 Names of people (Grammar based concept extraction) Countries (Rule based categorization) Ontology facets or subdomains (Grammar based concept extraction + rule based categorization) – Attachment #1. Domain Vocabulary/Concept Lists (Grammar based concept extraction) – Attachment #2.")
90
Step 6. Review and Validation of Ontology Values

91
Expert Review of Facets
Are all of the core facets of ontologies included in the list? If not, what is missing? We have identified some facets as related but not essential aspects of ontologies. Have we characterized these correctly? If not, what should be changed? What is included in the list that should not be? This includes both core and related facets. It is generally a good idea to try to limit facets to no more than 30 (what a human mind can retain in short term memory)
")
92
Expert Review of Concept Lists
If you were talking about ontology with an expert, are all of the concepts you would use included in the domain concept list? If not, what is missing? Are there a few concepts missing, or is there a larger subdomain or knowledge area that is missing? What is in the list that is core to ontologies? What is only related to ontologies? If you were looking for information about ontologies – from an expert point of view – would you use any of these concepts to search? Which ones are missing? What shouldn’t be in the list? If you were looking for information about ontologies from a novice’s point of view – what is missing from the list of concepts? What shouldn’t be included?

93
Step 7. Operationalizing the Ontology

Similar presentations

















 Grants Chapter 6.>")

