Download presentation
Presentation is loading. Please wait.

1
Intermediate Statistical Analysis Professor K. Leppel

2
Hypothesis Testing One Sample

3
Notation H 0 : hypothesis being tested “null hypothesis” H a or H 1 : alternative hypothesis Example: H 0 : = 100 versus H 1 : 100

4
Type I and Type II errors Type I error – rejecting the null hypothesis when it’s true. Type II error – accepting the null hypothesis when it’s false.

5
Situation H 0 is trueH 0 is false Decision accept H 0 reject H 0

6
Situation H 0 is trueH 0 is false Decision accept H 0 reject H 0 incorrect decision (type I error) probability = = level of significance
 probability = = level of significance")
7
Situation H 0 is trueH 0 is false Decision accept H 0 correct decision probability = 1- = confidence level reject H 0 incorrect decision (type I error) probability = = level of significance
 probability = = level of significance")
8
Situation H 0 is trueH 0 is false Decision accept H 0 correct decision probability = 1- = confidence level incorrect decision (type II error) probability = reject H 0 incorrect decision (type I error) probability = = level of significance
 probability = reject H 0 incorrect decision (type I error) probability = = level of significance")
9
Situation H 0 is trueH 0 is false Decision accept H 0 correct decision probability = 1- = confidence level incorrect decision (type II error) probability = reject H 0 incorrect decision (type I error) probability = = level of significance correct decision probability = 1- = power of the test
 probability = reject H 0 incorrect decision (type I error) probability = = level of significance correct decision probability = 1- = power of the test")
10
Critical region Values of the test statistic for which the null hypothesis is rejected. Example: Suppose you are testing whether or not the population mean is 100. Your test statistic is the sample mean. If the sample mean is very far from 100, perhaps less than 90 or more than 110, you reject the hypothesis that the mean is 100. Then your critical region is the set of values of the sample mean that are less than 90 or more than 110.

11
Acceptance region Values of the test statistic for which the null hypothesis is accepted. Example: Again suppose you are testing whether the population mean is 100, and your test statistic is the sample mean. You decided to reject the null hypothesis if the sample mean is less than 90 or more than 110. You accept the null hypothesis if the sample mean is between 90 and 110. Then your acceptance region is the set of values of the sample mean that are between 90 and 110.

12
Example: Suppose you want to know whether the mean IQ at a particular university is 130. You know the population standard deviation is 5.4. To test the hypothesis, you take a random sample of 25 observations. The mean IQ of the sample is 128.

13
a 130 b If the null hypothesis is correct, the center of the distribution of the sample mean is 130. acceptance region crit. reg. Our critical and acceptance regions look like this graph. We need to determine what a and b are so that we know when we should accept our null hypothesis and when we should reject it.

14
a 130 b Suppose we want our probability of type I error to be at most 0.05. acceptance region crit. reg. We want the probability of rejecting the null hypothesis when it is actually correct to be 0.05. So we are in the critical region when the graph is centered at 130 with probability 0.05. The area in each of the two tails of the critical region is half of 0.05 or 0.025. 0.025

17
.025 The equation we derived implies this graph of the standard normal or Z distribution. From the Z table, we know that the cut-off points for the tails with area 0.025 must be 1.96 and -1.96. -1.961.96

18
Solving the first equation for a and the second equation for b, we find a = 127.88 and b = 132.12.

19
127.88 130 132.12 Returning to our graph for the sample mean, we have this picture. acceptance region crit. reg. So if our sample mean is between 127.88 and 132.12, we accept the null hypothesis that the population mean IQ is 130. If our sample mean is less than 127.88 or more than 132.12, we reject the null hypothesis and accept the alternative that the population mean is not 130.

20
127.88 130 132.12 Since the sample mean was 128, what would our decision be? acceptance region crit. reg. Accept H 0 : = 130 If the sample mean was 127 instead, what would our decision be?

21
In the hypothesis test we just performed, we determined the cut-off points a and b for the sample mean, and then checked to see if our observed values were in the acceptance or critical region. Another way of doing the hypothesis test is to use the “p-value.” The p-value is the probability that the value of the sample mean is as far away from the hypothesized mean as observed, if the hypothesized mean is actually correct. If the p-value is greater than our test level , we accept the null hypothesis. If the p-value is less than , we reject the null hypothesis. The reasoning when the p-value is less than is this: The probability of seeing the observed value of the sample mean, if the null hypothesis is true, is very small. Since it’s unlikely under the assumption of the null hypothesis, we reject that hypothesis.

22
Let’s do the same problem using the p-value method. Recall that the sample mean was 128, the population standard deviation was 5.4, the sample size was 25, and the test level was 0.05. = 2 (0.5-0.4678) = 2 (0.0322) = 0.0644 Using a test level of = 0.05, we accept the null hypothesis, since the p-value > 0.05. -1.85 0 1.85Z.4678.0322
 = 2 (0.0322) = Using a test level of = 0.05, we accept the null hypothesis, since the p-value > Z")
23
Quick & Dirty Method of Hypothesis Testing 1.Convert the sample mean to a standard normal Z-statistic: 2. Sketch the critical & acceptance regions in terms of a Z-statistic. 3. Make the decision.

24
Same problem one more time: Recall that the sample mean was 128, the population standard deviation was 5.4, the sample size was 25, and the test level was 0.05. Based on a test level or of 0.05, we have the graph below. -1.96 0 1.96Z.4750.0250 crit. reg. Since the Z-value -1.85 is in the acceptance region, we accept the null hypothesis that the population mean is 130.

25
When a hypothesis has only one value such as = 130, we call it a simple hypothesis. When a hypothesis has more than one value, we call it a composite hypothesis. Some examples:

26
The critical region depends on the alternative hypothesis, not the null. If the alternative is “not equal to”, the critical region is 2-tailed. If the alternative is “greater than”, the critical region is the right tail only. If the alternative is “less than”, the critical region is the left tail only.

27
1-Tailed Hypothesis Test at the 5% level if the sample mean is 128 based on a sample of size 25, and the population standard deviation is 5.4. We will again use these 3 methods to do this problem: 1.Determine critical region in terms of the sample mean. 2.P-value 3.“Quick & Dirty”

28
1. Determine critical region in terms of the sample mean. 130.45.05 crit. reg. Since the alternative hypothesis is <130, the critical region is the left tail. Since the test level is 5%, the area of the critical region is 0.05. Acceptance region We sketch the graph under the assumption that the null hypothesis is true, centering the graph at the most conservative value of that hypothesis, = 130. a

29
130.45. 05 crit. reg. Acceptance region a 0.45. 05 crit. reg. Acceptance region Z Using the Z table, we find the cut-off point must be -1.645.

30
we find a = 128.22. 128.22 Our value of the sample mean was 128. Since 128 is in the critical region, we reject the null hypothesis and accept the alternative that < 130. 130.45.05 crit. reg. Acceptance region a

31
2. P-value method. Keep in mind that the sample mean is 128, the population standard deviation is 5.4, the sample size is 25, and the test level is 0.05. = 0.5 – 0.4678 = 0.0322 Using a test level of = 0.05, we reject the null hypothesis and accept the alternative that <130, since the p-value < 0.05. Z 0.0322 -1.85

32
3. “Quick & Dirty” Method. Again, remember that the sample mean was 128, the population standard deviation was 5.4, the sample size was 25, and the test level was 0.05. Based on a test level or of 0.05, we have the graph below. crit. reg. Since the Z-value -1.85 is in the critical region, we reject the null hypothesis and accept the alternative that < 130. Z 0.05 -1.645 Acceptance region.45

33
Calculating Recall that is the probability of type I error = Pr( reject H 0 | H 0 is true), and is the probability of type II error = Pr( accept H 0 | H 0 is false).
, and is the probability of type II error = Pr( accept H 0 | H 0 is false).")
34
where the population standard deviation is 50 and the sample size is 25. Let’s first determine the critical region, and then calculate , based on a specified value of .

35
a 1000 b acceptance region crit. reg. 0.025

36
.025 The above equation implies this graph of the standard normal or Z distribution. -1.961.96 From the Z table, we know that the cut-off points for the tails with area 0.025 must be 1.96 and -1.96

37
Solving the first equation for a and the second equation for b, we find a = 980.4 and b = 1019.6. So our critical and acceptance regions look like this: 980.4 1000 1019.6 acceptance region crit. reg.

38
But what if is actually 990, not 1000? 980.4 990 1019.6 acceptance region crit. reg. Our cut-off values for the critical and acceptance regions are still the same, but the distribution curve is centered at 990 instead of at 1000. = Pr(accepting H 0 | H 0 is false, in this case, =990) = Pr(being in acceptance region| =990)
 = Pr(being in acceptance region| =990).")
39
We determine from the Z table that the specified area is 0.3315 + 0.4985 = 0.83 -0.96 0 2.96 Z.3315.4985

40
So, , the probability of accepting the null hypothesis that = 1000, when is actually 990, is 0.83. With the given standard deviation and sample size, it is difficult to distinguish a distribution with a mean of 990 from a distribution with a mean of 1000. If we had a mean of 900, which is farther from 1000 than 990 is, it would be easier to distinguish it from 1000, and our value of would be smaller.

41
In general, we want the probability of type I and type II errors, and , to be small. How can we make and smaller? Since is the probability of accepting the null hypothesis when it is false, we can make smaller by accepting the null hypothesis less often (shrinking the acceptance region). If we shrink the acceptance region, however, we expand the critical region. That means we reject the null hypothesis more often, increasing the probability of rejecting it when it is correct. So we’ve increased . Similarly, if we try to decrease , we increase .
. If we shrink the acceptance region, however, we expand the critical region. That means we reject the null hypothesis more often, increasing the probability of rejecting it when it is correct. So we’ve increased . Similarly, if we try to decrease , we increase ..")
42
Example: Parties Suppose you have just completed your first semester at college. You are reflecting back on your social experiences of the semester, and thinking that you went to a lot of boring parties. You are thinking that you would like to reduce the number of boring parties that you attend. Think of the decision to attend a party as one involving the null hypothesis that the party is a good one and the alternative hypothesis is that the party is boring. You want to keep down the error probabilities = Pr(skip a party | it’s a good one) and = Pr(attend a party | it’s boring). To reduce , you might go to a lot of parties, but then you risk attending boring ones. To reduce , you might go to very few parties, but then you risk missing some good ones.
 and = Pr(attend a party | it’s boring). To reduce , you might go to a lot of parties, but then you risk attending boring ones. To reduce , you might go to very few parties, but then you risk missing some good ones..")
43
Is there some way that we can decrease both and ? Yes, we can decrease both and by collecting more data or more information, by increasing the sample size. Unfortunately, in the real world, collecting more data usually means increasing the cost of the study. So there’s a tradeoff between accuracy and cost.

44
In the context of our party example, to keep down the number of boring parties you attend as well as the number of good parties you miss, you need to get more information. You need to talk to more people, find out who’s going, the music that is likely to be played, the food that will be served, etc.

45
How do we do hypothesis testing when the population standard deviation is unknown? We do it similarly to what we’ve done so far, but we replace the population standard deviation by the sample standard deviation and the Z distribution by the t distribution

46
Example: Suppose you sample 16 matchboxes. The sample mean number of matches per box is 17 and the sample standard deviation is 2. Test at the 5% level Use all three methods that we used previously.

47
a 18 b Method 1 acceptance region crit. reg. If the null hypothesis is correct, the distribution of the sample mean is centered at 18. We need to find the values of a and b so that the combined area in the two tails is 0.05. 0.025 We don’t have to compute a and b separately. We can just compute one of them and figure out the other by symmetry. We’ll do b.

49
.025 The equation we derived implies this graph of the t distribution. -2.1312.131 From the t table, we find that for 15 degrees of freedom, the cut-off points for the two tails with a combined area 0.05 are 2.131 and -2.131.

50
Solving the first equation for a and the second equation for b, we find a = 16.93 and b = 19.07, which gives us the acceptance and critical regions shown in the graph. Since our value for the sample mean is 17, which is in the acceptance region, we accept the null hypothesis that = 18. 18 acceptance region crit. reg. 16.93 19.07

51
Method 2 Recall that the sample size is 16, the sample mean number of matches is 17, the sample standard deviation is 2, and we’re testing at the 5% level Since we’re doing a 2-tailed test, we need a 2-tailed p-value.

52
Using Excel, we find that this 2-tailed p-value is 0.064. So based on a test level of = 0.05, we accept the null hypothesis, since the p-value > 0.05. -2.00 0 2.00t 15.032

53
Method 3 Keep in mind that the sample mean was 17, the sample standard deviation was 2, the sample size was 16, and the test level was 0.05. Based on a test level or of 0.05, we have the graph below. Since our t 15 -value, -2.00, is in the acceptance region, we accept the null hypothesis that the population mean is 18. -2.131 0 2.131t 15.0250 crit. reg. Acceptance region

54
New Example: Let X be the number of miles driven when the cumulative repair cost for a car reaches $500. Given a sample of 15 observations, a sample mean of 22,500, and a sample standard deviation of 4,000, test at the 5% level Use all three methods that we used previously. Notice that for this test, the critical region is just the left tail. Also, since we have the sample standard deviation, not the population standard deviation, we’ll be using a t-statistic.

55
a 24,000 Method 1 acceptance region crit. reg. If the null hypothesis is correct, the distribution of the sample mean is centered at 24,000. We need to find the value of a so that the area in the left tail is 0.05. 0.05

57
.05 The equation we derived implies this graph of the t distribution. -1.761 From the t table, we find that for 14 degrees of freedom, the cut-off point for a left tail with an area of 0.05 is -1.761.

58
Solving the equation for a, we find a = 22,181. This gives us the acceptance and critical regions shown in the graph. Since our value for the sample mean is 22,500, which is in the acceptance region, we accept the null hypothesis that = 24,000. 24,000 acceptance region crit. reg. 22,181

59
Method 2 Recall that the sample size is 15, the sample mean is 22,500, the sample standard deviation is 4,000, and we’re testing at the 5% level Since we’re doing a 1-tailed test, we need a 1-tailed p-value.

60
Using Excel, we find that this p-value is 0.084. So based on a test level of = 0.05, we accept the null hypothesis, since the p-value > 0.05. -1.452 0t 14.084

61
Method 3 Keep in mind that the sample mean was 22,500, the sample standard deviation was 4,000, the sample size was 15, and the test level was 0.05. Based on a test level or of 0.05, we have the graph below. Since our t 14 -value, -1.452, is in the acceptance region, we accept the null hypothesis that the population mean is 24,000. -1.761 0t 14.05 crit. reg. Acceptance region

62
Hypothesis testing on the population proportion

63
So for hypothesis testing on a population proportion, we have the statistic

64
Example Notice that our test is right-tailed, so the critical region is as shown below. From the Z table, we know that the cut-off point is 1.645. 1.645 0Z.05 acceptance region crit. reg..45 Since our Z-statistic is in the acceptance region, we accept H 0 : = 0.30

65
In the section we have just completed, we did 3 different types of hypothesis tests for the case of a single sample. 1.population mean - known population variance 2.population mean - unknown population variance 3.population proportion In the next section we will look at hypothesis testing when we have more than one sample.

Similar presentations


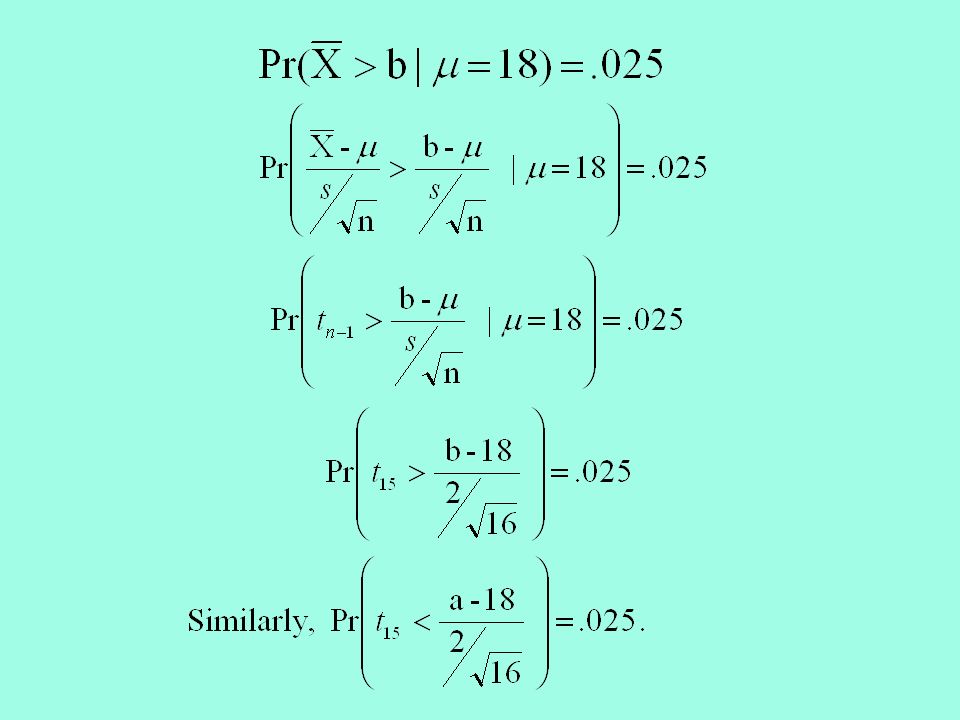





>")







 REJECT Compute the Sample Mean.>")






