Download presentation
Presentation is loading. Please wait.

1
Proteomics Informatics – Data Analysis and Visualization (Week 13)
")
2
Statistics http://blogs.nature.com/methagora/2013/08/giving_statistics_the_attention_it_deserves.html

3
Data Visualization http://blogs.nature.com/methagora/2013/07/data -visualization-points-of-view.html

4
MS/MS Lysis Fractionation Protein Identification MS/MS Digestion Sequence DB All Fragment Masses Pick Protein Compare, Score, Test Significance Repeat for all proteins Pick PeptideLC-MS Repeat for all peptides

5
Search Results

6
Significance Testing False protein identification is caused by random matching An objective criterion for testing the significance of protein identification results is necessary. The significance of protein identifications can be tested once the distribution of scores for false results is known.

7
Distribution of Extreme Values NormalSkewed n=3 n=10 n=100 n=3 n=10 n=100

8
Significance Testing - Expectation Values The majority of sequences in a collection will give a score due to random matching.

9
Database Search M/Z List of Candidates Extrapolate And Calculate Expectation Values List of Candidates With Expectation Values Distribution of Scores for Random and False Identifications Significance Testing - Expectation Values

11
Application: Analytical Measurements Theoretical Concentration Measured Concentration

12
A Few Characteristics of Analytical Measurements Accuracy: Closeness of agreement between a test result and an accepted reference value. Precision: Closeness of agreement between independent test results. Robustness: Test precision given small, deliberate changes in test conditions (preanalytic delays, variations in storage temperature). Lower limit of detection: The lowest amount of analyte that is statistically distinguishable from background or a negative control. Limit of quantification: Lowest and highest concentrations of analyte that can be quantitatively determined with suitable precision and accuracy. Linearity: The ability of the test to return values that are directly proportional to the concentration of the analyte in the sample.
. Lower limit of detection: The lowest amount of analyte that is statistically distinguishable from background or a negative control. Limit of quantification: Lowest and highest concentrations of analyte that can be quantitatively determined with suitable precision and accuracy. Linearity: The ability of the test to return values that are directly proportional to the concentration of the analyte in the sample..")
13
Measuring Blanks

14
Coefficient of Variation Variance Sample Mean Coefficient of Variation (CV)
")
15
Lower Limit of Detection The lowest amount of analyte that is statistically distinguishable from background or a negative control. Two methods to determine lower limit of detection: 1.Lowest concentration of the analyte where CV is less than for example 20%. 2.Determine level of blank by taking 95 th percentile of the blank measurements and add a constant times the standard deviation of the lowest concentration. K. Linnet and M. Kondratovich, Partly Nonparametric Approach for Determining the Limit of Detection, Clinical Chemistry 50 (2004) 732–740.
 732–740..")
16
Limit of Detection and Linearity Theoretical Concentration Measured Concentration

17
Precision and Accuracy Theoretical Concentration Measured Concentration

18
A Data Set with Two Samples

19
A proteomics example – no replicates

20
A proteomics example – three replicates no replicates three replicates Log 2 Standard Deviation Log 2 Average Spectrum Count Log 2 Sum Spectrum Count Log 2 Spectrum Count Ratio Log 2 Sum Spectrum Count Log 2 Spectrum Count Ratio

21
How Different are Two Measurements?

22
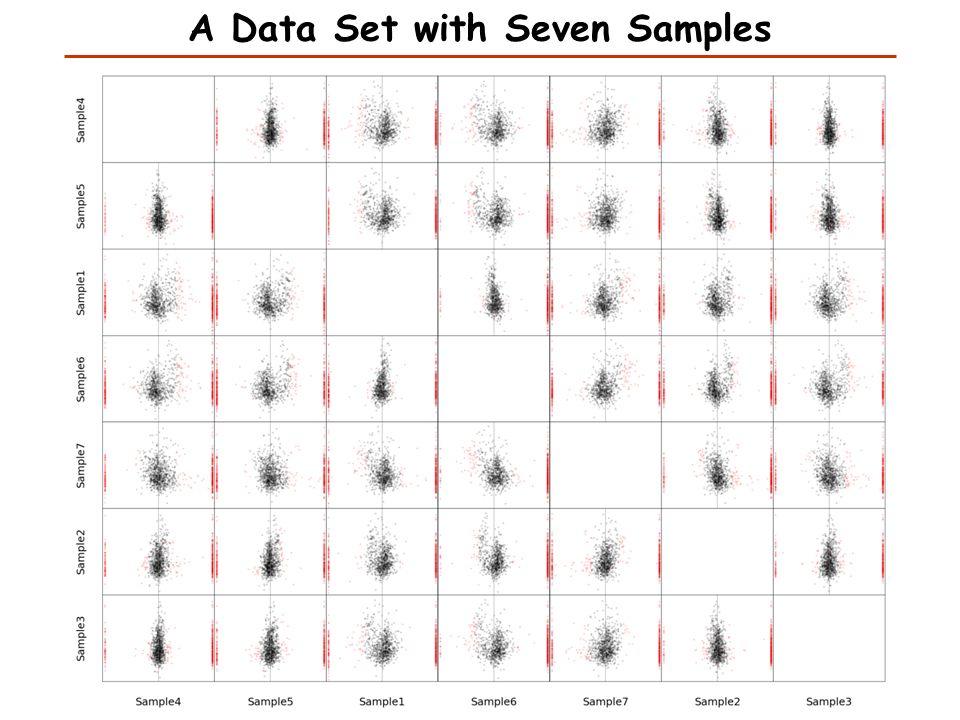
A Data Set with Seven Samples 3 replicates 3 replicates + one more replicate a few months later Normalized

23
A Data Set with Seven Samples

25
Box Plot M. Krzywinski & N. Altman, Visualizing samples with box plots, Nature Methods 11 (2014) 119
 119.")
26
n=5 Box Plots ComplexNormalSkewedLong tails n=10 n=100 n=5 n=10 n=100 n=5 n=10 n=100 n=5 n=10 n=100

27
Box Plots with All the Data Points ComplexNormalSkewedLong tails n=5 n=10 n=100 n=5 n=10 n=100 n=5 n=10 n=100 n=5 n=10 n=100

28
Box Plots, Scatter Plots and Bar Graphs Normal Distribution Error bars: standard deviation error bars: standard deviation error bars: standard error

29
Box Plots, Scatter Plots and Bar Graphs Skewed Distribution Error bars: standard deviation error bars: standard deviation error bars: standard error

30
Box Plots, Scatter Plots and Bar Graphs Distribution with Fat Tail Error bars: standard deviation error bars: standard deviation error bars: standard error

31
Venn Diagrams

32
TCGA – Unsupervised mRNA Expression Analysis The Cancer Genome Atlas Network, Comprehensive molecular portraits of human breast tumors. Nature. 490 (7418):61-70.
:")
33
Correlations between mRNA and protein abundance in TCGA colon tumors B Zhang et al. Nature 000, 1-6 (2014) doi:10.1038/nature13438
 doi: /nature")
34
The Effect of Copy Number Alterations B Zhang et al. Nature 000, 1-6 (2014) doi:10.1038/nature13438
 doi: /nature13438")
35
The Effect of Copy Number Alterations

36
Testing multiple hypothesis Is the concentration of calcium/calmodulin-dependent protein kinase type II different between the two samples? What protein concentration are different between the two samples? p = 2x10 -6 The p-value needs to be corrected taking into account the we perform many tests. Bonferroni correction: multiply the p-value with The number of tests performed (n): p corr = p uncorr x n In this case where 3685 proteins are identified, so the Bonferroni corrected p-value for calcium/calmodulin-dependent protein kinase type II is p corr = 2x10 -6 x 3685 = 0.007
: p corr = p uncorr x n In this case where 3685 proteins are identified, so the Bonferroni corrected p-value for calcium/calmodulin-dependent protein kinase type II is p corr = 2x10 -6 x 3685 =")
37
Testing multiple hypothesis The p-value distribution is uniform when testing differences between samples from the same distribution. Normal distribution Sample size = 10 p-value 1 0 # of test p-value 1 0 # of test p-value 1 0 # of test 0 8 0 60 0 500 10,000 tests1,000 tests100 tests

38
Testing multiple hypothesis The p-value distribution is uniform when testing differences between samples from the same distribution. Normal distribution Sample size = 10 30 tests from a distribution with a different mean (μ 1 -μ 2 >>σ) p-value 1 # of test p-value 1 # of test p-value 1 0 # of test 0 30 0 100 0 500 10,000 tests1,000 tests100 tests 0 0
 p-value 1 # of test p-value 1 # of test p-value 1 0 # of test ,000 tests1,000 tests100 tests 0 0.")
39
Testing multiple hypothesis Controlling for False Discovery Rate (FDR) Normal distribution Sample size = 10 30 tests from a distribution with a different mean (μ 1 -μ 2 >>σ) p-value 1 False Rate p-value 1 False Rate p-value 1 0 False Rate 0 1 0 1 0 1 0 0 False Discovery Rate False Discovery Rate False Discovery Rate 10,000 tests1,000 tests100 tests
 Normal distribution Sample size = tests from a distribution with a different mean (μ 1 -μ 2 >>σ) p-value 1 False Rate p-value 1 False Rate p-value 1 0 False Rate False Discovery Rate False Discovery Rate False Discovery Rate 10,000 tests1,000 tests100 tests")
40
Testing multiple hypothesis False Discovery Rate (FDR) and False Negative Rate (FNR) Normal distribution Sample size = 10 100 tests 30 tests from a distribution with a different mean p-value 1 False Rate p-value 1 False Rate p-value 1 0 False Rate 0 1 0 1 0 1 0 0 μ 1 -μ 2 =2σμ1-μ2=σμ1-μ2=σμ 1 -μ 2 =σ/2 False Discovery Rate False Negative Rate False Discovery Rate False Negative Rate False Discovery Rate False Negative Rate
 and False Negative Rate (FNR) Normal distribution Sample size = tests 30 tests from a distribution with a different mean p-value 1 False Rate p-value 1 False Rate p-value 1 0 False Rate μ 1 -μ 2 =2σμ1-μ2=σμ1-μ2=σμ 1 -μ 2 =σ/2 False Discovery Rate False Negative Rate False Discovery Rate False Negative Rate False Discovery Rate False Negative Rate")
41
Proteomics Informatics – Data Analysis and Visualization (Week 13)
")
Similar presentations




 = 113.5 bp median(nucs) = 110 bp sd(nucs+ = 17.3.>")





: Analysing data.>")

>")



 Course Director David Fenyö Contact information>")
 Course Director David Fenyö Contact information>")


