Download presentation
1
Delon Toh

2
Pitfalls of 2 nd Gen Amplification of cDNA – Artifacts – Biased coverage Short reads – Medium ~100bp for Illumina – 700bp for 454

3
3 rd Gen: PacBIO RS Real-time single molecule sequencer No amplification = no bias Produces long reads – Median ~2246 – Max~23000 ** Resolve complex repeats and span entire gene transcript (No need complex computational assembly)
")
4
3 rd Gen Problem 82.1%-84.6% nucleotide accuracy Point mutations + deletions Results in: Pairwise differences between two reads is approximately twice their individual error rate >5-10% error rate what most genome assemblers can tolerate

6
Length of single-molecule PacBio reads = size distribution of most transcipts PacBio reads will represent full-length/near full- length transcript No need complex algorithms (e.g Trinity) for short reads, in order to detect spliced isoforms Predominance of indel errors makes analysis of raw read problematic
 for short reads, in order to detect spliced isoforms Predominance of indel errors makes analysis of raw read problematic")
7
Solution for high error rate Generate short, high-accuracy sequences Correct the error inherent in long, single molecule sequences Assemble corrected ‘hybrid’ reads

8
Black: Errors Error between 2 Long pink reads: 16% each Error between 1 Pink and 1 blue bar: 16% x ~1% Rare sequencing error will propagate when only sequencing error co-occurs Trimming and splitting long reads (high indel %) whenever there is a gap in short read tiling
 whenever there is a gap in short read tiling")
9
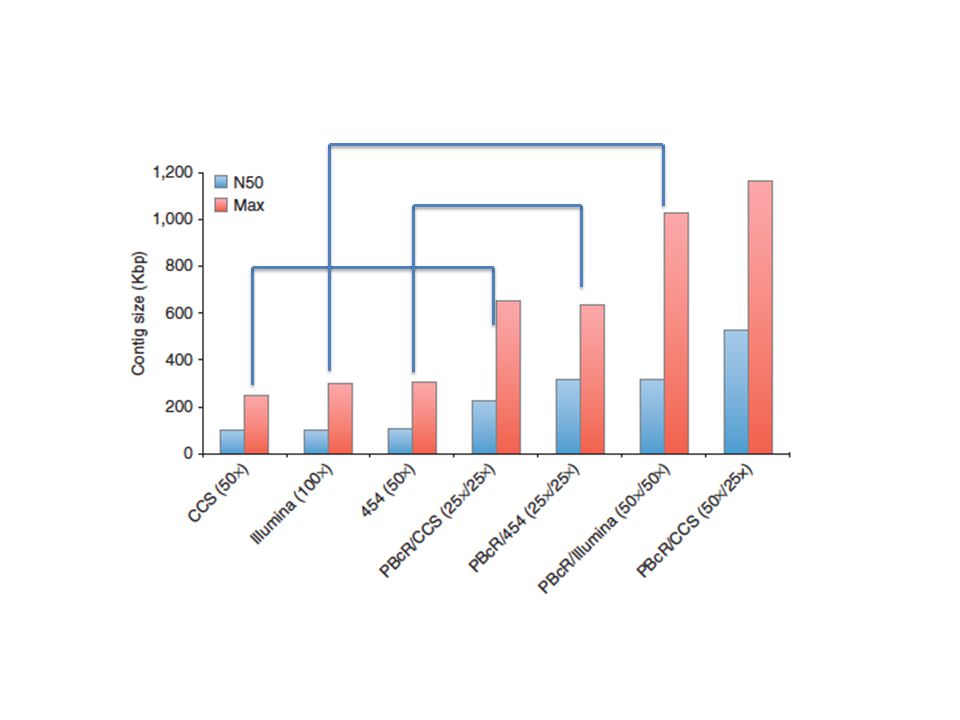
Correction accuracy/performance Using short reads from Illumina to correct Pacbio reads for each reference organism – Lambda NENB3011 – E. coli – S. cerevisiae S228c ~85% to 99% accuracy of long reads PBcR PacBio Corrected Reads

10
Correction and Throughput Reads may be discarded (low abundance RNA?) – Low quality – Short length % of reads that are successfully corrected = Throughput – ~60%
 – Low quality – Short length % of reads that are successfully corrected = Throughput – ~60%")
11
Read accuracy = corrected read vs reference sequence

13
Single-molecule RNA-seq correction: Zea mays 0.06% insertion, 0.02% deletion rate 99.1% aligned to reference genome by BLAT at >90% sequence identity 50130 PacBio reads Median size: 817 11.6% aligned to reference genome by BLAT at >90% sequence identity Correction

15
Many PacBio reads represented close to full- length transcripts Post-correction sequences have virtually no errors and precisely identified splicing junctions

16
Summary 2 nd Gen Sequencing – Short fragment, – Accurate – Requires complex algorithm (eg, Cufflink, Trinity) to piece the short fragments into meaning full transcript 3 rd Gen Sequencing – Long fragment – Inaccurate Combine the long reads from 3 rd gene and accuracy from 2 nd gene – Short fragment used to correct long fragment Long and accurate read – Computational input used to correct rather than assemble
 to piece the short fragments into meaning full transcript 3 rd Gen Sequencing – Long fragment – Inaccurate Combine the long reads from 3 rd gene and accuracy from 2 nd gene – Short fragment used to correct long fragment Long and accurate read – Computational input used to correct rather than assemble")
17
Future Correction was optimized for genome assembly and applied for RNA-seq Direct RNA-seq by changing polymerase to RNA-polymerase?
















 Isolate total RNA Isolate mRNA from total RNA (poly.>")




>")

 Isolate total RNA Isolate mRNA from total RNA (poly.>")