Download presentation
Presentation is loading. Please wait.

1
CS157A Spring 05 Data Mining Professor Sin-Min Lee

2
Today's Presentation covers: 1.What is Data Mining? 2.Data Mining Objectives 3.Data Mining Operations 4.Knowledge Discovery 5.Application of Data Mining 6.Summary 7.References

3
Statistics Databases Artificial Intelligence Visualization Data Mining Overview of Data Mining

5
1. What is Data Mining? ➔ We usually use Data Mining to: – Discovering useful, previously unknown knowledge by analyzing large and complex databases. – Knowledge discovery, exploratory data analysis, applied statistics, machine learning – Search for valuable Information in Large Databases

7
2. Data Mining Objectives ➔ Find rules and patterns in large volumn databases ➔ Discovery – Finding human understandable patterns describing the data ➔ Prediction – Using some variables or fields in database to predict unknown or future values or other variables of interest

9
Data Mining Objectives ➔ Knowledge Discovery – Stage somewhat prior to prediction where information is insufficient – It's close to decision support

10
3. Data Mining Operations ➔ Associations ➔ Sequential Patterns ➔ Time-Series Clustering ➔ Classification ➔ Segmentation ➔ And many more!

11
Association ● Used to find all rules in a basket data ● Basket data also called transaction data ● Analyze how items purchased by customers in a shop

14
Association... ● A formal definition: ● Let I = {i 1, i 2, …i m } be a total set of items D a set of transactions d is one transaction consists of a set of items d I ● Association rule:- ● X Y where X I,Y I and X Y = ● Support = (#of transactions contain X Y ) / D ● Support: number of instances predicted correctly ● Confidence: number of correct predictions, as proportion of all instances ● Confidence = (#of transactions contain X Y) / #of transactions contain X
 / D ● Support: number of instances predicted correctly ● Confidence: number of correct predictions, as proportion of all instances ● Confidence = (#of transactions contain X Y) / #of transactions contain X.")
15
Association... ● Example of transaction data: – Transaction 1: CD player, music's CD, music's book – Transaction 2: CD player, music's CD – Transaction 3: Music's CD, music's book – Transaction 4: CD player ● I = {CD player, music's CD, music's book} ● D = 4 ● # of transactions contain both CD player, music's CD = 2 ● # of transactions contain CD player = 3 ● Support = 2 /4, Confidence: 2 /3

16
Applying Association Rule... ● Example: Books that tend to be bought together. If a customer buys a book, an online bookstore may suggest other associated books. (ie. Amazon.com) ● Example: If a person buys a laptop, the salesperson may suggest accessories that tend to be bought along with laptop.
 ● Example: If a person buys a laptop, the salesperson may suggest accessories that tend to be bought along with laptop..")
18
Time Series Clustering ● Given: – A database of time series ● Find: – Groups of similar time series ● Sample Applications: – Determine products with similar selling patterns – Identify companies with similar pattern of grown – Find stocks with similar price movements

19
Classification ● Classification – Problem: Given that items belong to one of several classes, and given past instances (aka training instances) of items along with the classes to which they belong, the problem is to PREDICT the class to which a new item belongs – The class of the new instance is not known, so other attributes of the instance must be used to predict the class. – It can be done by finding rules that partition the given data into disjoint groups

20
Classification... ● Dataset is usually in the form of a relation table. ● Data has a set of distinct attributes. ● Each data record is also labeled with a class. ● Goal : To build a model or learn rules that can be used to predict the classes of new cases. ● Training Data are used to build this model.

21
Classification... ● For example – Suppose that a credit card company wants to decide whether or not to give a credit card to an applicant ● The company has a variety of information about the person, such as their age, education background, income, etc.. ● Then they will rank the applicants (catogorized them into classes) ● Forall person P, P.degree=masters AND P.income > 75,000 ==> P.credit = excellent ● Forall person P, P.degree=bachelors OR (P.income >= 25,000 AND P.income P.credit = good
 ● Forall person P, P.degree=masters AND P.income > 75,000 ==> P.credit = excellent ● Forall person P, P.degree=bachelors OR (P.income >= 25,000 AND P.income P.credit = good.")
22
Classification... ● Table: Age Smoke Risk ---- ------------------------------------------ 20 No Low 25 Yes High 44 Yes High 18 No Low 55 No High 35 No Low ● To identify the risk (we have two groups): – Risk = Low and Risk = High
: – Risk = Low and Risk = High.")
25
Classification... ● The following techniques could be used to analyze the classification: – Decision Tree – Predictive Modeling – Using association rule – Neural networks – etc...

26
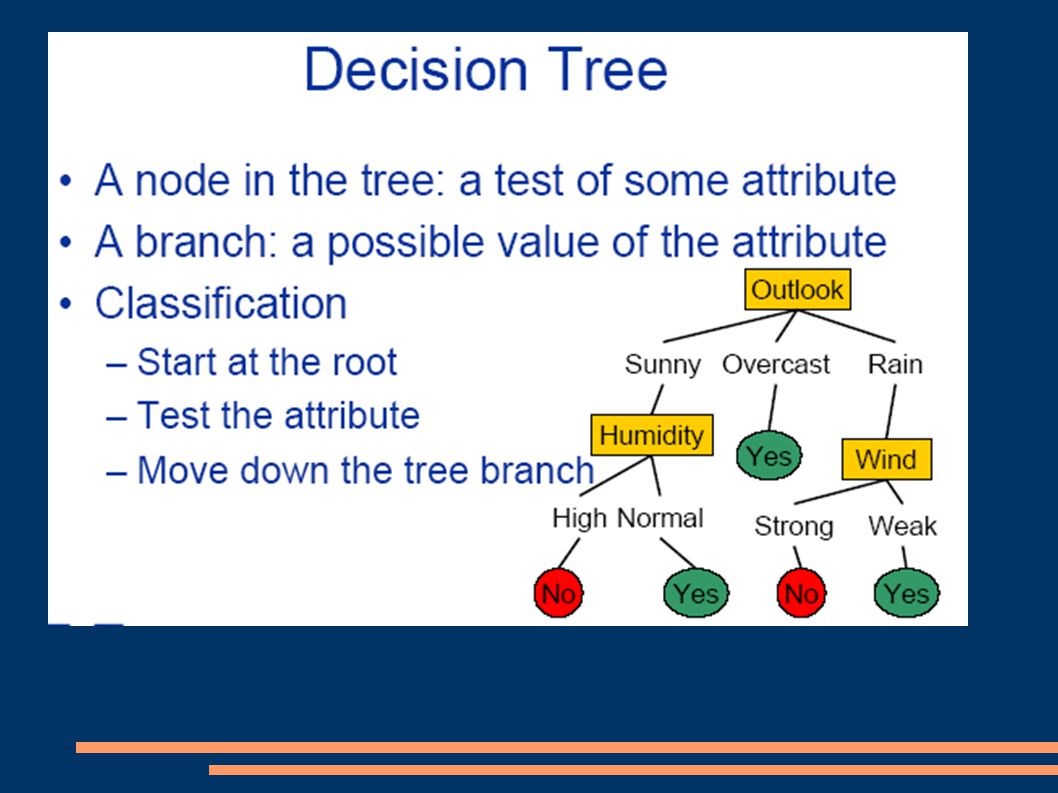
Decision Trees ● “Divide-and-conquer” approach produce tree ● Nodes involve testing a particular attribute ● Usually, attribute value is compared to constant ● Other possibilities: – Comparing values of two attributes – Using a function of one or more attributes ● Leaves assign classification, set of classifications, or probability distrbution to instances ● Unknown instance is routed down the tree

28
Decision Tree ● In short, Decision tree is just a series of nested if/then rules. Smoke Age Yes No 0-35 High Low 36-100 High Our previous example

31
Predictive Modeling ● Predict values based on similar groups of data ● Pattern Recognition – Association of an observation to past experience or knowledge – Interchangeable with classification ● Estimation – Assign infinite number of numeric labels to an observation

34
4. Knowledge Discovery ● Find Patterns in database – For example, if someone buys one thing, what else will he buy next ● Interesting + Certain = Knowledge – Usually the output called “Discovered Knowledge” ● KDD – Knowledge Discovery in Database ● A non-trivial process of identifying valid, potentially useful, and understandable patterns in data

35
KDD – Knowledge Discovery in Database... ● Advances in traditional tasks in data analysis – Classification, Clustering – New Data Mining operations ● Association rules ● Sequential patterns ● Deviation /Exceptions ● New Application areas – Spatial, Text, Web, Image,....

36
KDD – Knowledge Discovery in Database ● Applications – Most large companies have data warehouses: platforms for Data Mining Projects – Trend towards integrated vertical solutions such as financial and telecom areas ● Back-end: integration with databases ● Front-end: Campaign Management or CRM (Customer Relationship Management)
")
37
KDD – Knowledge Discovery in Database ● Next Generation Knowledge Discovery Systems: – Have integrated front-end access to knowledge delivery tools – Have integrated back-end access to enterprise and external databases – Have knowledge discovery engine as embedded part of the overall solution – Be oriented to solving a business problem, not a data analysis problem

38
5. Application of Data Mining ● Medical ● Control Theory ● Engineering ● Marketing and Finance ● Data Mining on the web ● Scientific Data Base ● Fraud Dectection ● And many more!

39
6. Summary ● Data Mining IS.... – Decision Trees, Nearest Neighbor Classification, Neural networks, Rule Induction, K-means Clustering – Decision support process in which we search patterns of information in data ● Data Mining is NOT... – Retrieving data (ie. Google) ● “Information retrieval” or “Database querying” ● Data Mining infers “the right query” from data – Merging many small databases into a large one
 ● Information retrieval or Database querying ● Data Mining infers the right query from data – Merging many small databases into a large one.")
40
Summary ● Data Mining is not... – Data warehousing – SQL / Ad Hoc Queries / Reporting – Software Agents – Online Analytical Processing (OLAP) – Data Visualization
 – Data Visualization.")
42
Referneces ● Dr. Lee's Presentation – http://www.cs.sjsu.edu/~lee/cs157b/cs157b.html http://www.cs.sjsu.edu/~lee/cs157b/cs157b.html ● Data Mining Section ● Dr. Kurt Thearling's website – http://www.thearling.com/dmintro/dmintro_frame.htm http://www.thearling.com/dmintro/dmintro_frame.htm ● An Introduction to Data Mining

Similar presentations


















 Margaret Dunham Dr. M.H.Dunham, Data Mining,>")





 DATA MINING.>")







