Download presentation
Presentation is loading. Please wait.

1
RELIABILITY consistency or reproducibility of a test score (or measurement)
")
2
Common approaches to estimating reliability n Classical True Score Theory – test-retest, alternate forms, internal consistency n useful for estimating relative decisions – intraclass correlation n useful for estimating absolute decisions n Generalizability Theory – can estimate both relative & absolute

3
Reliability is a concept central to all behavioral sciences. To some extent all measures are unreliable. This is especially true with psychological measures and measurements based on human observation

4
Sources of Error n Random – fluctuations in the measurement based purely on chance. n Systematic – Measurement error that affect a score because of some particular characteristic of the person or the test that has nothing to due with the construct being measured.

5
CTST n X = T + E – Recognizes only two sources of variance n test -retest (stability) n alternate forms (equivalence in item sampling) n test-retest with alternate forms (stability & equivalence but these are confounded) – Cannot adequately estimate individual sources of error influencing a measurement
 n alternate forms (equivalence in item sampling) n test-retest with alternate forms (stability & equivalence but these are confounded) – Cannot adequately estimate individual sources of error influencing a measurement")
6
ICC n Uses ANOVA to partition variance due to between subjects and within subjects – Has some ability to accommodate multiple sources of variance – Does not provide an integrated approach to estimating reliability under multiple conditions

7
Generalizability Theory The Dependability of Behavioral Measures, (1972) Cronbach, Glaser, Nanda, & Rajaratnam
 Cronbach, Glaser, Nanda, & Rajaratnam")
8
Dependability The accuracy of generalizing from a person’s observed score on a measure to the average score that person would have received under all possible testing conditions the tester would be willing to accept.

9
The Decision Maker n The score on which the decision is to be based is only one of many scores that might serve the same purpose. The decision maker is almost never interested in the response given to the particular moment of testing. n Ideally the decision should be based on that person’s mean score over all possible measurement occasions.

10
Universe of Generalization n Definition & establishment of the universe admissible observations: – observations that the decision maker is willing to treat as interchangeable. – all sources of influence acting on the measurement of the trait under study. n What are the sources of ERROR influencing your measurement?

11
Generalizability Issues n Facet of Generalization – raters, trials, days, clinics, therapists n Facet of Determination – usually people, but can vary (e.g. raters)
.")
12
Types of Studies n Generalizability Study (G-Study) n Decision Study (D-Study)
 n Decision Study (D-Study)")
13
G-Study n Purpose is to anticipate the multiple uses of a measurement. n To provide as much information as possible about the sources of variation in the measurement. n The G-Study should attempt to identify and incorporate into its design as many potential sources of variation as possible.

14
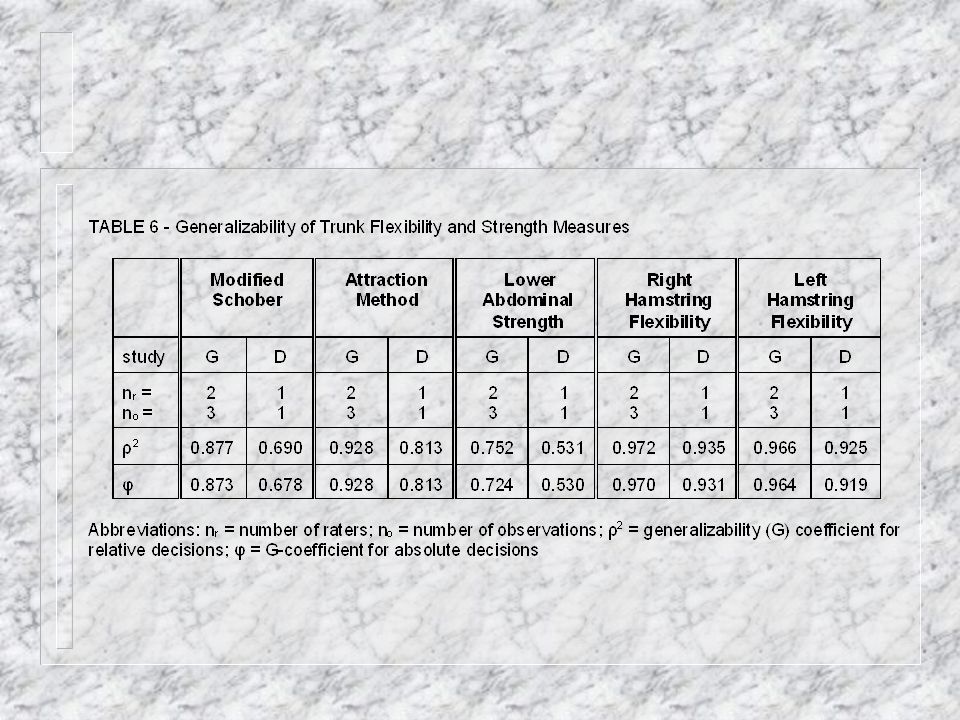
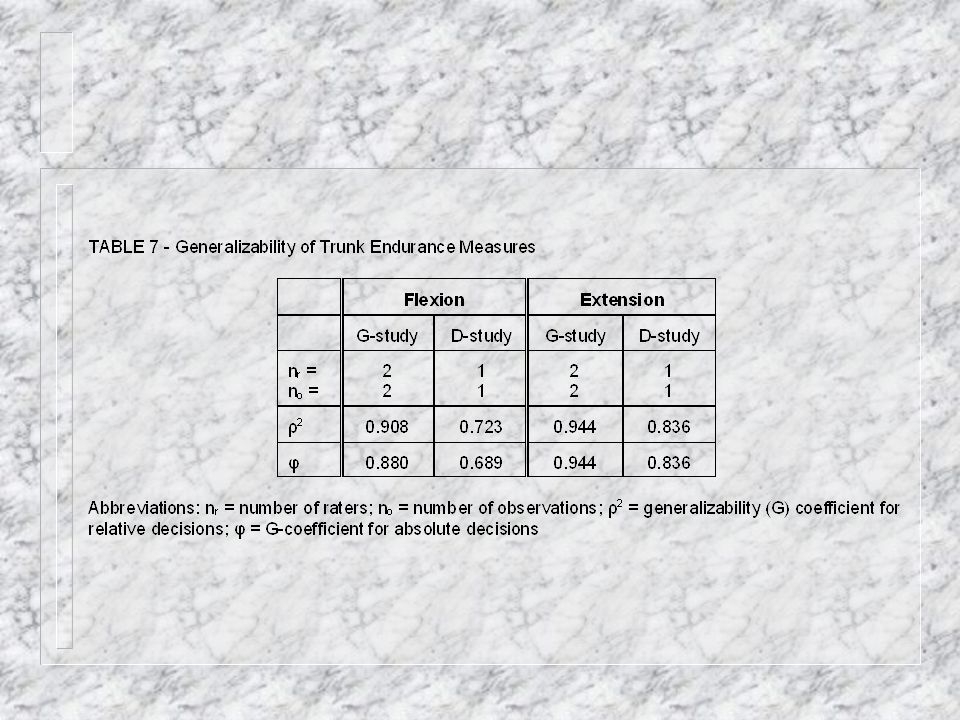
D-Study n Makes use of the information provided by the G- Study to design the best possible application of the measurement for a particular purpose. n Planning a D-Study: – defines the Universe of Generalization – specifies the proposed interpretation of the measurement. – uses G-Study information to evaluate the effectiveness of alternative designs for minimizing error and maximizing reliability.

15
Design Considerations n Fixed Facets n Random Facets

16
Fixed Facet n When the levels of the facet exhaust all possible conditions in the universe to which the investigator wants to generalize. n When the level of the facet represent a convenient sub-sample of all possible conditions in the universe.

17
Random Facets n When it is assumed that the levels of the facet represent a random sample of all possible levels described by the facet. n If you are willing to EXCHANGE the conditions (levels) under study for any other set of conditions of the same size from the universe.
 under study for any other set of conditions of the same size from the universe..")
18
Types of Decisions n Relative – establish a rank order of individuals (or groups). – the comparison of a subject’s performance against others in the group. n Absolute – to index an individual’s (or group’s) absolute level of measurement. – measurement results are to be made independent from the performance of others in the group.
 absolute level of measurement. – measurement results are to be made independent from the performance of others in the group..")
19
Statistical Modeling ANOVA – just as ANOVA partitions a dependent variable into effects for the independent variable (main effects & interactions), G-theory uses ANOVA to partition an individual’s measurement score into an effect for the universe-score and an effect for each source of error and their interactions in the design.
, G-theory uses ANOVA to partition an individual’s measurement score into an effect for the universe-score and an effect for each source of error and their interactions in the design.")
20
n In ANOVA we were driven to test specific hypotheses about our independent variables and thus sought out the F statistic and p- value. n In G-theory we will use ANOVA to partition the different sources of variance and then to estimate their amount (Variance Component). Statistical Modeling
. Statistical Modeling.")
21
One Facet Design n 4 Sources of Variability – systematic differences among subjects n (object of measurement) – systematic differences among raters (occasions, items) – subjects*raters interaction – random error confounded
 – systematic differences among raters (occasions, items) – subjects*raters interaction – random error confounded")
22
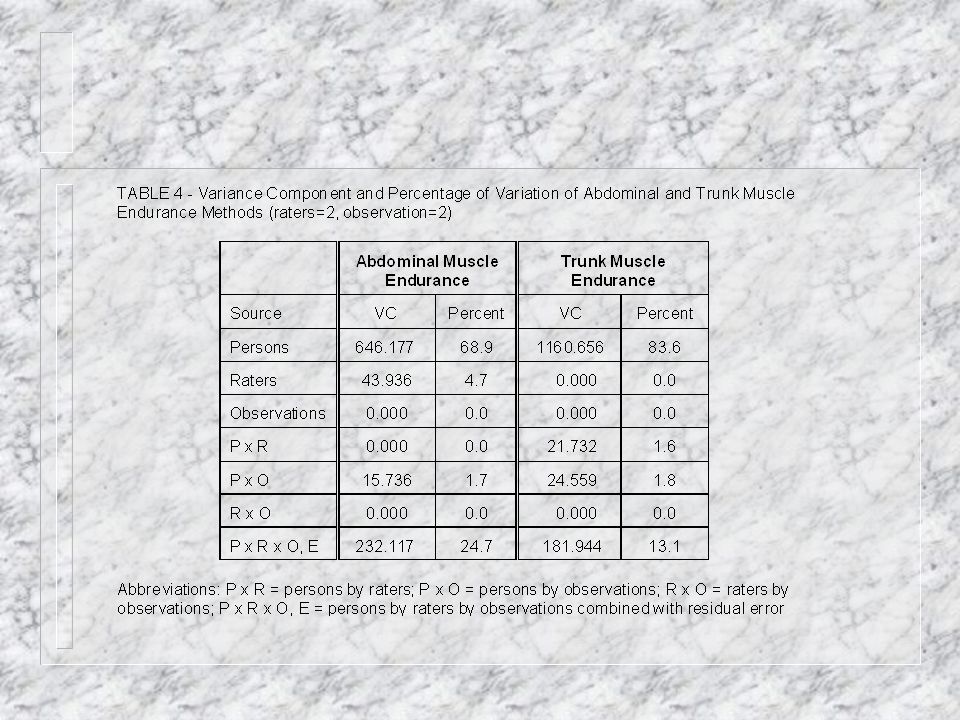
Two Facet Design Components of Variance n Example of a fully crossed two facet design (Kroll, et. al.) n Seven sources of variance are estimated: – subjects – raters – observations – s x r – s x o – r x o – s x r x o,e
 n Seven sources of variance are estimated: – subjects – raters – observations – s x r – s x o – r x o – s x r x o,e.")
23
Variance Components Subjects (s)Observations (o) Raters (r) (s x r)(o x r) (s x o) (s x r x o) + Error
Observations (o) Raters (r) (s x r)(o x r) (s x o) (s x r x o) + Error")
26
Relative Error Facet of Determination: Subjects Subjects (s)Observations (o) Raters (r) (s x r)(o x r) (s x o) (s x r x o) + Error F 2 rel = F 2 sr /n r + F 2 so /n o + F 2 sro,e /n r n o
Observations (o) Raters (r) (s x r)(o x r) (s x o) (s x r x o) + Error F 2 rel = F 2 sr /n r + F 2 so /n o + F 2 sro,e /n r n o")
27
Absolute Error Facet of Determination: Subjects Subjects (s)Observations (o) Raters (r) (s x r)(o x r) (s x o) (s x r x o) + Error F 2 abs = F 2 r /n r + F 2 o /n o + F 2 sr /n r + F 2 so /n o + F 2 or /n o n r + F 2 sro,e /n o n r
Observations (o) Raters (r) (s x r)(o x r) (s x o) (s x r x o) + Error F 2 abs = F 2 r /n r + F 2 o /n o + F 2 sr /n r + F 2 so /n o + F 2 or /n o n r + F 2 sro,e /n o n r")
28
Generalizability Coefficients AKA: Reliability Coefficients Absolute Generalizability Coefficient for Subjects: F 2 s = ------------- F 2 s + F 2 abs Relative Generalizability Coefficient for Subjects: F 2 s 2 = ------------- F 2 s + F 2 rel

29
D-Study: consider raters as fixed, no generalization made to other raters Subjects (s)Observations (o) Raters (r) sxosxo sxrsxroxroxr s x o x r,e Variation in s is no longer affected by raters: a.) average over the levels the fixed effect b.) analyze the fixed effect levels separately F s 2* = F s 2 + 1/n r F ro 2 F o 2* = F o 2 + 1/n r F ro 2 F so,e 2* = F so 2 + 1/n r F sor,e 2 Consider (a) averaging results in a s x o design
Observations (o) Raters (r) sxosxo sxrsxroxroxr s x o x r,e Variation in s is no longer affected by raters: a.) average over the levels the fixed effect b.) analyze the fixed effect levels separately F s 2* = F s 2 + 1/n r F ro 2 F o 2* = F o 2 + 1/n r F ro 2 F so,e 2* = F so 2 + 1/n r F sor,e 2 Consider (a) averaging results in a s x o design")
35
Subjects (s)Observations (o)so,e F 2 rel = F 2 so,e /n o F 2 abs = F 2 o /n o + F 2 so,e /n o Error
Observations (o)so,e F 2 rel = F 2 so,e /n o F 2 abs = F 2 o /n o + F 2 so,e /n o Error")
Similar presentations