Download presentation
Presentation is loading. Please wait.

1
Crawling the Hidden Web Sriram Raghavan Hector Garcia-Molina @ Stanford University

2
Introdution What’s the problem? Current-day crawlers retrieve only Publicly Indexable Web (PIW) Why is it a problem? Large amounts of high quality information are ‘hidden’ behind search forms The hidden Web is 500 times as large as PIW
 Why is it a problem. Large amounts of high quality information are ‘hidden’ behind search forms The hidden Web is 500 times as large as PIW.")
3
Introduction (cont’d) What’s the solution? –Design a crawler capable of extracting content from the hidden Web –A generic operational model of a hidden Web crawler, Hidden Web Exposer (HiWE) Why is HiWE a solution?
 Why is HiWE a solution .")
4
User Form Interaction

5
Challenges and Simplifications Challenges Parse, process and interact with search forms Fill out forms for submission Simplifications Application dependant With user assistance Only address content retrieval and resource discovery step is done

6
Crawler Form Interaction

7
Performance Metrics Coverage Metric Submission Efficiency Lenient Submission Efficiency

8
Design Issues Internal Form Representation Task-specific Database Matching Function Response Analysis

9
HiWE Architecure

10
HiWE – Form Representaion

11
HiWE – Sample Forms

12
HiWE – Task-Specific Database Label Value-Set (LVS) Tables Vaule Set is a fuzzy set of element values is a membership function to assign weights [0, 1] to the member of the set
![HiWE – Task-Specific Database Label Value-Set (LVS) Tables Vaule Set is a fuzzy set of element values is a membership function to assign weights [0, 1] to the member of the set](http://images.slideplayer.com/16/4955973/slides/slide_12.jpg "HiWE – Task-Specific Database Label Value-Set (LVS) Tables Vaule Set is a fuzzy set of element values is a membership function to assign weights [0, 1] to the member of the set")
13
HiWE – Populating the LVS Table Explicit Initialization Built-in Entries Wrapped Data Sources Crawling Experience

14
HiWE – Computing Weights Values from explicit initialization and built-in categories have weight 1 Values from external data sources assigned weights by wrappers [0, 1] Values gathered by crawlers Extract and Match the label – add new values Extract and can not match the label – add new entries (L,V) Can not extract the label – find closest entry and add new values
![HiWE – Computing Weights Values from explicit initialization and built-in categories have weight 1 Values from external data sources assigned weights by wrappers [0, 1] Values gathered by crawlers Extract and Match the label – add new values Extract and can not match the label – add new entries (L,V) Can not extract the label – find closest entry and add new values](http://images.slideplayer.com/16/4955973/slides/slide_14.jpg "HiWE – Computing Weights Values from explicit initialization and built-in categories have weight 1 Values from external data sources assigned weights by wrappers [0, 1] Values gathered by crawlers Extract and Match the label – add new values Extract and can not match the label – add new entries (L,V) Can not extract the label – find closest entry and add new values")
15
HiWE – Matching Function Enumerate values for finite domain elements Label matching step 1: string normalization step 2: string matching Evaluate value assignment Fuzzy Conjunction Average Probabilistic

16
Configuring HiWE

17
HiWE – extraction from pages Prune form page and only keep forms Approximately lay-out the pruned page using a lay- out engine Using lay-out engine to identify candidate labels to form elements Rank each candidate and chose the best one

18
HiWE – extraction from pages (cont’d)
")
19
HiWE – Experiments

20
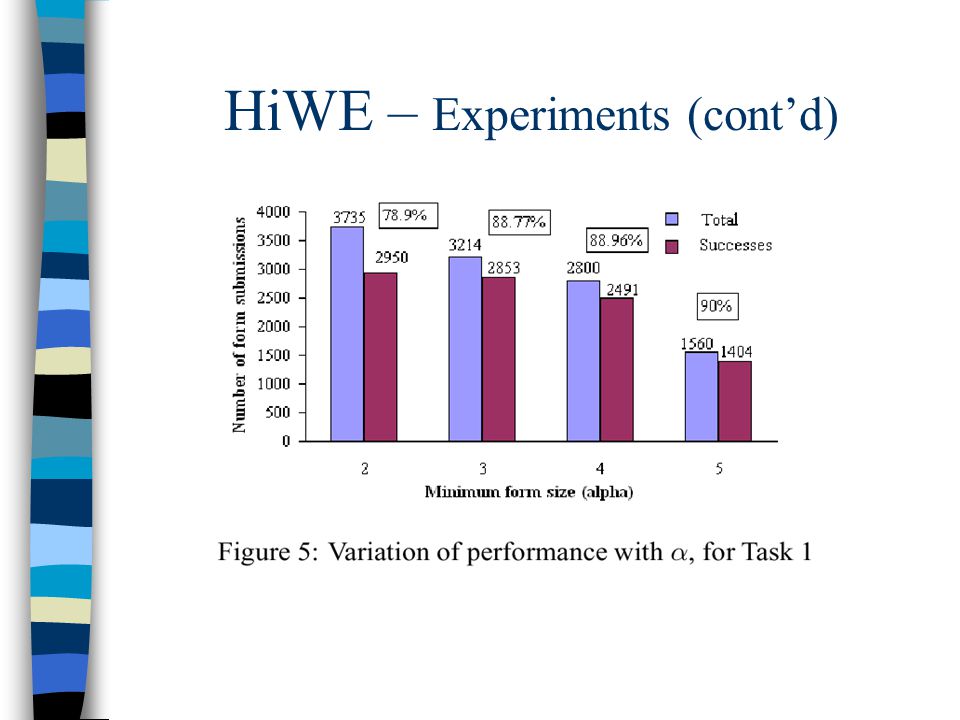
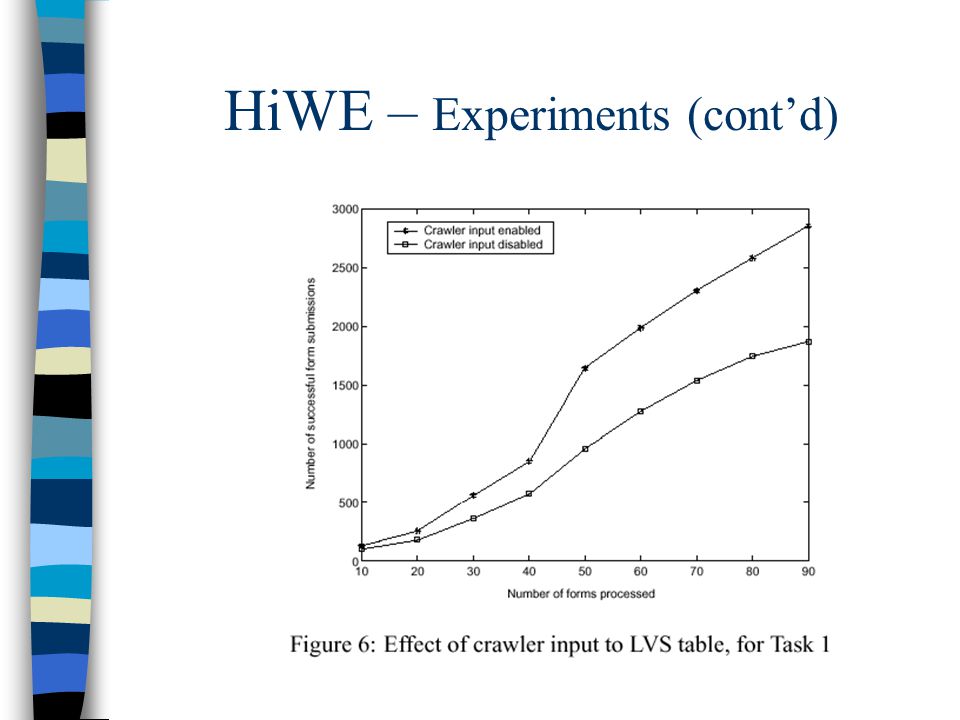
HiWE – Experiments (cont’d)
")
23
93% accuracy

24
Future Work Recognize and respond to the dependencies between form elements Support partially filling-out forms

25
Conclusion Propose an application specific approach to hidden Web crawling Implement a prototype crawler – HiWE Set the stage for designing a variety of hidden Web crawlers

Similar presentations









 (c) Wolfgang Hürst, Albert-Ludwigs-University.>")






>")


