Download presentation
Presentation is loading. Please wait.

1
The Mean Square Error (MSE):
:")
2
Now,

3
Examples: 1) 2)
 2)")
4
Efficiency Assume there are a number (finite or infinite) of unbiased point estimators for a particular parameter :
 of unbiased point estimators for a particular parameter :")
5
Note that the variance of that estimator for which the relative efficiency should be calculated is in the denominator.

6
Example: Assume a sample x 1, …, x n from a population with p.d.f. f(x; ), i.e. the mean is the unknown parameter.
, i.e. the mean is the unknown parameter..")
7
It is seldom (if ever) possible to overview all available point estimators of a particular parameter (or their variances) But we could learn which is the lowest possible variance (at least for a majority of all cases) Cramér-Rao inequality (Information inequality) The Fisher information measure for the parameter :
 possible to overview all available point estimators of a particular parameter (or their variances) But we could learn which is the lowest possible variance (at least for a majority of all cases) Cramér-Rao inequality (Information inequality) The Fisher information measure for the parameter :")
8
An attempt to motivate why this is a measure of information about :

9
Now if

10
Proof:

12
Extensions: Calculations and attainment of the bound:

13
Example:

14
Sufficiency Assume a random sample x = (x 1, …, x n ) from a distribution with p.d.f. f (x; ) A statistic T = T(x 1, …, x n ) is sufficient for the parameter if the conditional distribution of X 1, …, X n given T does not depend on . Tricky concept, not always so easy to assimilate but specific cases can be complex in investigation
 A statistic T = T(x 1, …, x n ) is sufficient for the parameter if the conditional distribution of X 1, …, X n given T does not depend on . Tricky concept, not always so easy to assimilate but specific cases can be complex in investigation.")
15
What does it mean in practice? If T is sufficient for then no more information about than what is contained in T can be obtained from the sample. It is enough to work with T when deriving point estimates of In practice, most of the standard cases are such that an intuitive or from “reasonable relations” an indirectly derived point estimator is also sufficient for What is the point then? It can be used to find the minimum variance unbiased point estimator

16
Example:

18
Minimal sufficient statistic:

19
How can sufficient statistics be obtained? Factorization criterion

20
Example

21
Example 2.9 in the textbook: x = (x 1,…, x n ) a sample from N( , 2 )
 a sample from N( , 2 )")
22
A statistic defines a partition of the sample space of (X 1, …, X n ) into classes satisfying T(x 1, …, x n ) = t for different values of t. If such a partition puts the sample x = (x 1, …, x n ) and y = (y 1, …, y n ) into the same class if and only if then T is minimal sufficient for
 and y = (y 1, …, y n ) into the same class if and only if then T is minimal sufficient for .")
23
Example:

24
Rao-Blackwell’s theorem:

25
The Exponential families of distributions A random variable X belongs to the (k-parameter) exponential family of probability distributions if the p.d.f. of X can be written

26
For a random sample x = (x 1, …, x n ) from a distribution belonging to the exponential family
 from a distribution belonging to the exponential family")
27
Exponential family written on the canonical form:

28
Completeness Let x 1, …, x n be a random sample from a distribution with p.d.f. f (x; ) and T = T (x 1, …, x n ) a statistic Then T is complete for if whenever h T (T ) is a function of T such that E[h T (T )] = 0 for all values of then Pr(h T (T ) 0) = 1 Important lemmas from this definition: Lemma 2.6: If T is a complete sufficient statistic for and h (T ) is a function of T such that E[h (T ) ] = , then h is unique (there is at most one such function) Lemma 2.7: If there exists a Minimum Variance Unbiased Estimator (MVUE) for and h (T ) is and unbiased estimator for , where T is a complete minimal sufficient statistic for , then h (T ) is MVUE Lemma 2.8: If a sample is from a distribution belonging to the exponential family, then ( B 1 (x i ), …, B k (x i ) ) is complete and minimal sufficient for 1, …, k
 and T = T (x 1, …, x n ) a statistic Then T is complete for if whenever h T (T ) is a function of T such that E[h T (T )] = 0 for all values of then Pr(h T (T ) 0) = 1 Important lemmas from this definition: Lemma 2.6: If T is a complete sufficient statistic for and h (T ) is a function of T such that E[h (T ) ] = , then h is unique (there is at most one such function) Lemma 2.7: If there exists a Minimum Variance Unbiased Estimator (MVUE) for and h (T ) is and unbiased estimator for , where T is a complete minimal sufficient statistic for , then h (T ) is MVUE Lemma 2.8: If a sample is from a distribution belonging to the exponential family, then ( B 1 (x i ), …, B k (x i ) ) is complete and minimal sufficient for 1, …, k.")
Similar presentations

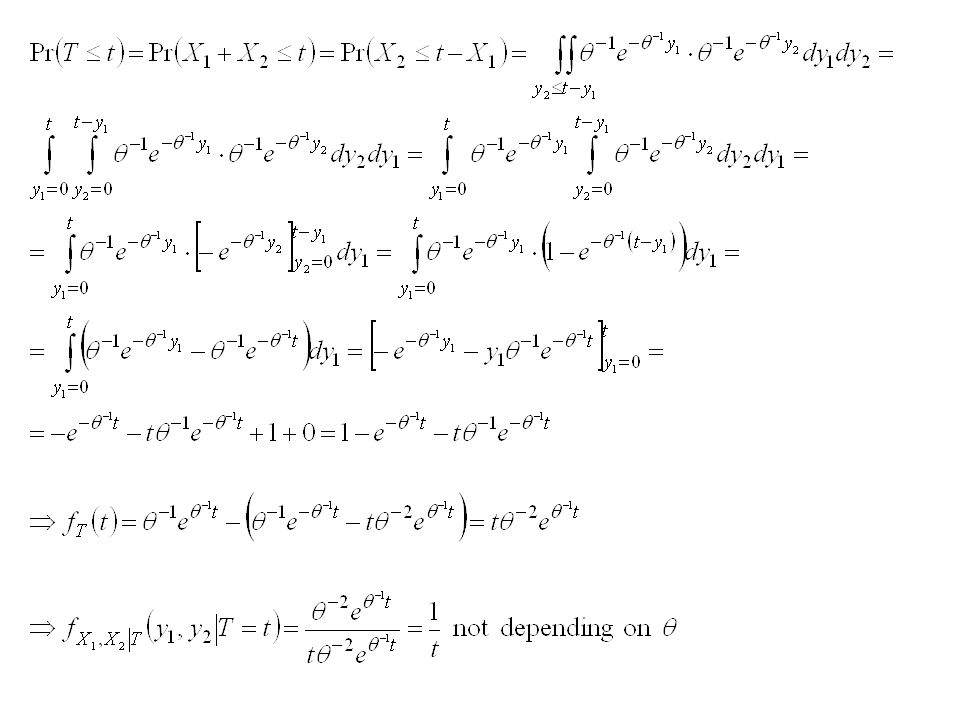






 values must be estimated before.>")
 and likelihood ratio (LR) test>")








 (and c.d.f. F(x; ) ) The maximum.>")


