Download presentation
Presentation is loading. Please wait.

1
Modern Information Retrieval
Chapter 8 Indexing and Searching

2
It is worthwhile building and maintaining an index when the text collection is large and semi-static
semi-static: not often updated consider search cost, space overhead, construction cost, and maintenance cost

3
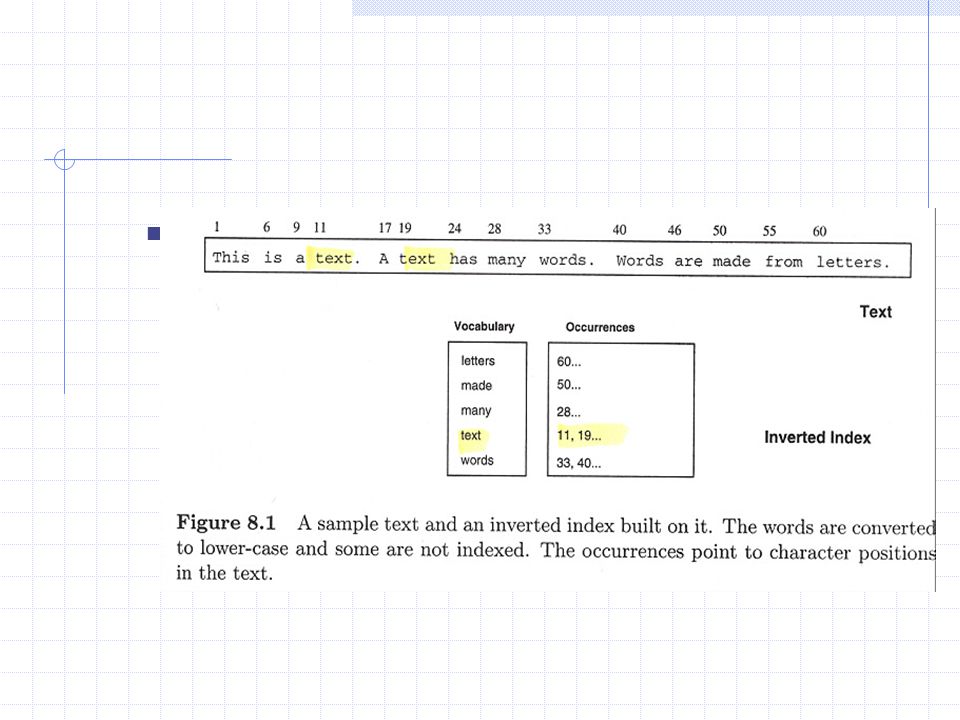
Inverted file (inverted index)
a word-oriented index vocabulary: the set of all different words in the text occurrences: lists of the text positions where the words appear the positions can refer to words or characters

5
block addressing reduces space overhead to 5%
the space required for the vocabulary is rather small while the occurrences demand much more space between 30% and 40% of the text size block addressing reduces space overhead to 5%

7
pointers are smaller due to fewer blocks
occurrences of a word inside a block are collapsed to one reference if the exact occurrence positions are required, an online search over the qualifying blocks has to be performed

9
blocks of natural division of the text collection
blocks of fixed size larger blocks match queries more often and incur more sequential traversals of text block addressing indices with 256 blocks stop working well with texts of 200 Mb blocks of natural division of the text collection good for single-word queries without the exact occurrence position requirement

10
searching the inverted file
vocabulary search: the words present in the query are separately searched in the vocabulary retrieval of occurrences: the lists of the occurrences of all the words found are retrieved

11
allow sub-linear search time at sub-linear space requirements
manipulation of occurrences: the lists are traversed to find places where all the words appear in sequence for a phrase query or appear close enough for a proximity query how to efficiently manipulate the occurrences when block addressing is used? intersect the lists, sequential search, and watch the block boundaries allow sub-linear search time at sub-linear space requirements not possible for other indices

12
constructing the inverted file

13
once constructed, it is written to disk in two files
the lists of occurrences are stored contiguously in the first file in the second file, the vocabulary is stored in lexicographical order with a pointer for each word to its list in the first file allow the vocabulary to be kept in memory

14
Suffix tree and suffix array
can be used to index any text character allow to answer efficiently more complex queries index points are selected form the text, which point to the beginning of the text positions which will be retrievable each position is considered as a text suffix each suffix is uniquely identified by its position

16
it is possible to index only word beginnings to have a functionality similar to inverted indices
a suffix tree is a trie data structure built over the suffixes of the text the pointers to the suffixes are stored at the leaf nodes the trie is compacted into a Patricia tree where unary paths are compressed an indication of the next character position to consider is stored at the nodes which root a compressed path

17
each node takes 12 to 24 bytes; if only word beginnings are indexed, a space overhead of 120% to 240% over the text size is produced

18
suffix arrays provide the same functionality with much less space requirements
an array containing all the pointers to the suffixes in lexicographical order space requirements close to 40% overhead

19
allow binary searches done by comparing the contents of each pointer
supra-index over the suffix array is used to reduce the number of disk accesses

20
compare with the inverted index

21
a simple phrase of words can be searched as if it was a simple pattern
indexing all text positions makes the index 10 to 20 times the text size for suffix trees a simple phrase of words can be searched as if it was a simple pattern how about a long phrase of words? processing proximity queries by searching all the words in the queries the matches collected and sorted to check the allowed distance as for inverted files

22
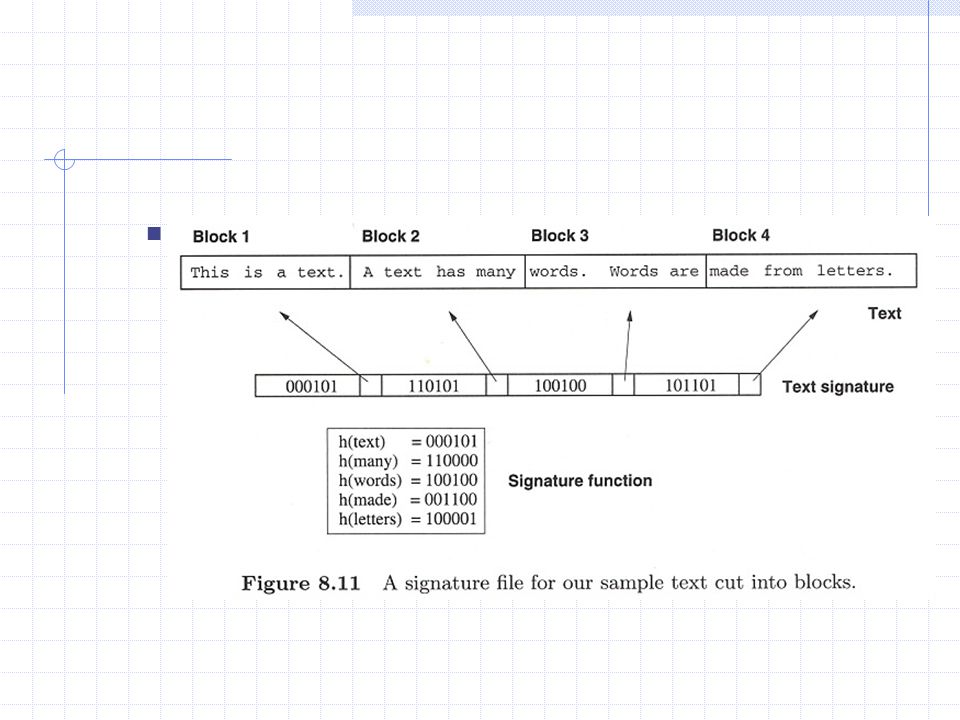
Signature files word-oriented index
low space overhead: 10% to 20% of text use a hash function to map words to bit masks of B bits (signatures) a text is divided in blocks of b words each a bit mask of size B is assigned to each block by bitwise ORing the signatures of all the words in the block
 a text is divided in blocks of b words each. a bit mask of size B is assigned to each block by bitwise ORing the signatures of all the words in the block.")
23
if a word is present in a block, all the bits set in its signature are also set in the bit mask of the block when a bit is set in the bit mask of the query word but not in the bit mask of the block, the word is not present in the block

25
false drop: all the corresponding bits are set while the word is not in the block
signature file design principle: make the probability of a false drop low while keeping the signature as short as possible searching a single word by hashing it to a bit mask W, checking whether , and verifying if the word is actually there

26
process a phrase or proximity query by bitwise ORing the signatures of all the words in the query
the probability of false drops is reduced care has to be exercised at block boundaries by overlapping words in consecutive blocks a 10% space overhead implies a false drop probability close to 2%, while a 20% space overhead errs with probability 0.046%

Similar presentations



: Indexing.>")


 Fang Wei-Kleiner.>")


![Dr. Kalpakis CMSC 661, Principles of Database Systems Index Structures [13]](/15/4658104/big_thumb.jpg "Dr. Kalpakis CMSC 661, Principles of Database Systems Index Structures [13]>")

>")



 SW5 fall 2004 Simonas Šaltenis E1-215b>")




 Modern Information Retrieval (C hapter 8) With G. Navarro.>")

