Download presentation
Presentation is loading. Please wait.

1
Peter Tsai Bioinformatics Institute, University of Auckland
RNA Sequencing Peter Tsai Bioinformatics Institute, University of Auckland

2
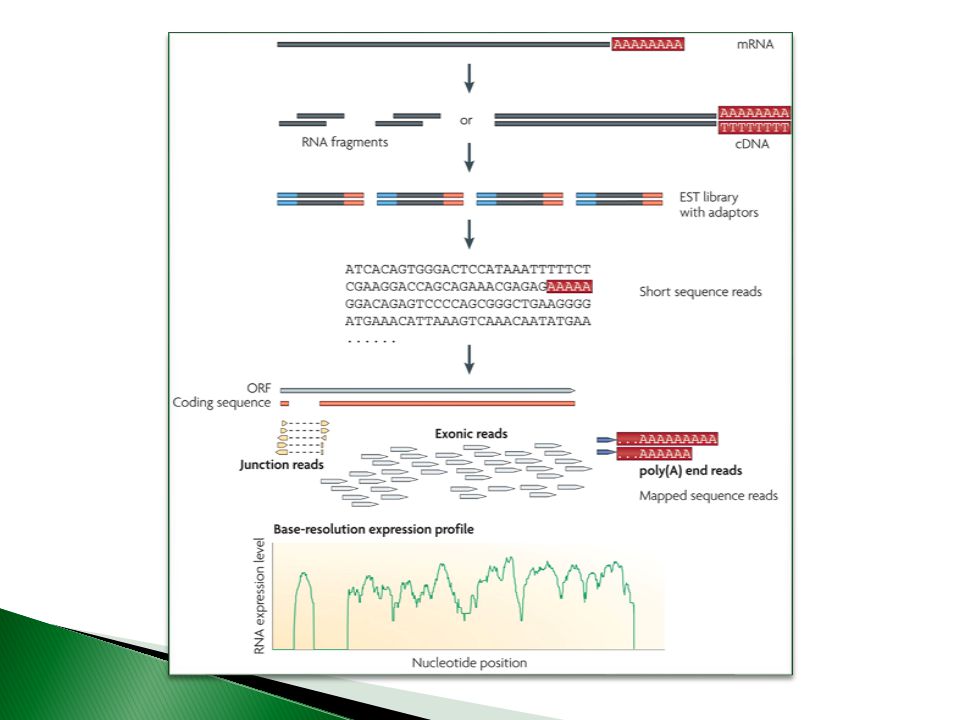
What is RNA-seq? Study of transcriptomes Identify known genes, exons, splicing events, ncRNA, miRNA Novel genes or transcripts Abundances of transcripts (quantitive expression) Differential expressed transcripts between different conditions Reconstructing transcriptome.
 Differential expressed transcripts between different conditions. Reconstructing transcriptome.")
4
General workflow Raw data QC De novo transcriptome assembly
Map to reference genome De novo transcriptome assembly Require downstream annotation Estimate abundance Normalisation Differential expression analysis

5
Quality checks and mapping
Use FastQC, SolexQA Trim off low quality region, keep only proper-paired reads Most QC software assume normality, but in RNA-seq data you will probably see none-normality You might see some duplicated reads, its probably due to highly expressed gene. Specific reference mapping tool that can map across splice junctions between exons, i.e. Tophat Specific de novo transcriptome assembly software for reconstruction of transcriptomes from RNA-seq data, i.e. Trinity

6
Expression value in RNA-seq
The total number of reads mapped to a gene/transcript (Count data or raw counts or digital gene expression) Complexity of using simple counts Sequencing depth: the higher the sequencing depth, the higher the counts Gene length: Counts are proportional to the length of the gene times mRNA expression level Counts distribution: difference on how counts are distributed among samples.
 Complexity of using simple counts. Sequencing depth: the higher the sequencing depth, the higher the counts. Gene length: Counts are proportional to the length of the gene times mRNA expression level. Counts distribution: difference on how counts are distributed among samples.")
7
Normalisation RPKM (Mortazavi et al, 2008)
Reads Per Kilobase of exon model per Million mapped reads FPKM (Mortazavi et al, 2010) Fragments Per Kilobase of exon model per Million mapped reads Paired-end RNA-Seq experiments produce two reads per fragment, but that doesn't necessarily mean that both reads will be mappable.
 Fragments Per Kilobase of exon model per Million mapped reads. Paired-end RNA-Seq experiments produce two reads per fragment, but that doesn t necessarily mean that both reads will be mappable.")
8
Data exploration Replicate 2 Replicate 1

9
Gene.ID/Description logFC logCPM LR PValue FDR 1 9.57E-08 2.72E-05 2 1.02E-07 3 5.68E-07 4 4.33E-06 5 1.17E-05 6 7 8 9 10 11 12 13 14 15 16 17 18 19

10
Up-regulated Down-regulated

11
ERCC spike-in control Set of external RNA transcripts with known concentration. Dynamic range and lower limit of detection Fold-change response Internal control, in order to measure against defined performance criteria

12
Dynamic range and lower limit of detection
The dynamic range can be measured as the difference between the highest and lowest concentration. Measure of sensitivity, and it is defined as the lowest molar amount of ERCC transcript detected in each sample The dynamic range can be measured as the difference between the highest and lowest concentration of ERCC transcript detected in each sample. The LLD is a measure of sensitivity, and it is defined as the lowest molar amount of ERCC transcript detected in each sample, with user-defined threshold values for determining detection. This translates to ~323,000 control molecules detected per 100 ng poly(A) RNA.
 RNA.")
13
Fold-change response

14
How much library depth is needed for RNA-seq?
Depends on a number of factors Biological questions Complexity of the organism Types of analysis Types of RNA, miRNA, lncRNA. Literature search for similar work Pilot experiment

15
Summary Have 3 or more biological replicates
Analysis your data with different normalisation methods Perform data exploration Use a standard spike-in as internal control Validation with qPCR

Similar presentations





 Edouard Severing.>")









>")



