Download presentation
Presentation is loading. Please wait.

1
BCS547 Neural Encoding

2
Introduction to computational neuroscience
10/01 Neural encoding 17/01 Neural decoding 24/01 Low level vision 31/01 Object recognition 7/02 Bayesian Perception 21/02 Sensorimotor transformations

3
Neural Encoding

4
What’s a code? Example Deterministic code: A ->10 B -> 01
If you see the string 01, recovering the encoded letter (B) is easy.
 is easy.")
5
Noise and coding Two of the hardest problems with coding come from:
Non invertible codes (e.g., two values get mapped onto the same code) Noise
 Noise.")
6
Example Noisy code: A -> 01 with p=0.8 -> 10 with p=0.2
B -> 01 with p=0.3 -> 10 with p=0.7 Now, given the string 01, it’s no longer obvious what the encoded letter is…

7
What types of codes and noises are found in the nervous system?

8
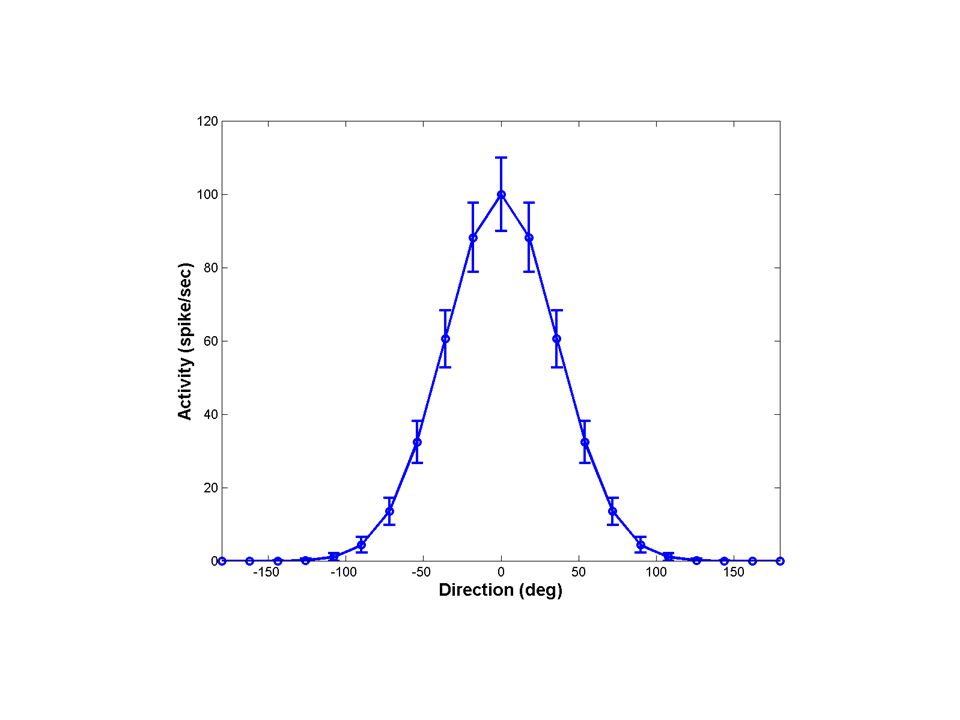
q: Direction of motion Receptive field Code: number of spikes 10
Response Stimulus

9
q: Direction of motion Receptive field 10 Trial 1 7 Trial 2 4 Trial 3
8 4 Trial 1 Trial 2 Trial 3 Trial 4 Stimulus

10
Variance of the noise, si(0)2
Variance, si(q)2, can depend on the input Mean activity fi(0) Tuning curve fi(q) Encoded variable (q)
2, can. depend on the input. Mean activity fi(0) Tuning curve fi(q) Encoded variable (q)")
11
Tuning curves and noise
The activity (# of spikes per second) of a neuron can be written as: where fi(q) is the mean activity of the neuron (the tuning curve) and ni is a noise with zero mean. If the noise is gaussian, then:
 of a neuron can be written as: where fi(q) is the mean activity of the neuron (the tuning curve) and ni is a noise with zero mean. If the noise is gaussian, then:")
12
Probability distributions and activity
The noise is a random variable which can be characterized by a conditional probability distribution, P(ni|q). Since the activity of a neuron is the sum of a deterministic term, fi(q), and the noise, it is also a random variable with a conditional probability distribution, P(ai| q). The distributions of the activity and the noise differ only by their means (E[ni]=0, E[ai]=fi(q)).
. Since the activity of a neuron is the sum of a deterministic term, fi(q), and the noise, it is also a random variable with a conditional probability distribution, P(ai| q). The distributions of the activity and the noise differ only by their means (E[ni]=0, E[ai]=fi(q)).")
13
P(ai|q=0) P(ai|q=-60) Activity distribution P(ai|q=-60)
 P(ai|q=-60) Activity distribution P(ai|q=-60)")
14
Examples of activity distributions
Gaussian noise with fixed variance Gaussian noise with variance equal to the mean

15
Poisson activity (or noise):
The Poisson distribution works only for discrete random variables. However, the mean, fi(q), does not have to be an integer. The variance of a Poisson distribution is equal to its mean.
, does not have to be an integer. The variance of a Poisson distribution is equal to its mean.")
16
Comparison of Poisson vs Gaussian noise with variance equal to the mean
0.09 0.08 0.07 0.06 0.05 Probability 0.04 0.03 0.02 0.01 20 40 60 80 100 120 140 Activity (spike/sec)
")
17
Poisson noise and renewal process
We bin time into small intervals, dt. Then, for each interval, we toss a coin with probability, P(head) =p. If we get a head, we record a spike. For small p, the number of spikes per second follows a Poisson distribution with mean p/dt spikes/second (e.g., p=0.01, dt=1ms, mean=10 spikes/sec).
 =p. If we get a head, we record a spike. For small p, the number of spikes per second follows a Poisson distribution with mean p/dt spikes/second (e.g., p=0.01, dt=1ms, mean=10 spikes/sec).")
18
Properties of a Poisson process
The number of events follows a Poisson distribution (in particular the variance should be equal to the mean) A Poisson process does not care about the past, i.e., at a given time step, the outcome of the coin toss is independent of the past. As a result, the inter-event intervals follow an exponential distribution (Caution: this is not a good marker of a Poisson process)
 A Poisson process does not care about the past, i.e., at a given time step, the outcome of the coin toss is independent of the past. As a result, the inter-event intervals follow an exponential distribution (Caution: this is not a good marker of a Poisson process)")
19
Poisson process and spiking
The inter spike interval (ISI) distribution is indeed close to an exponential except for short intervals (refractory period) and for bursting neurons. (CV close to 1, Softy and Koch, fig. 1 and 3) The variance in the spike count is proportional to the mean but the the constant of proportionality is 1.2 instead of 1 and there is spontaneous activity. (Softy and Koch, fig. 5)
 distribution is indeed close to an exponential except for short intervals (refractory period) and for bursting neurons. (CV close to 1, Softy and Koch, fig. 1 and 3) The variance in the spike count is proportional to the mean but the the constant of proportionality is 1.2 instead of 1 and there is spontaneous activity. (Softy and Koch, fig. 5)")
20
Open Questions Is this Poisson variability really noise?
Where does it come from? Hard question because dendrites integrate their inputs and average out the noise (Softky and Koch)
")
21
Non-Answers It’s probably not in the sensory inputs
It’s not the spike initiation mechanism (Mainen and Sejnowski) It’s not the stochastic nature of ionic channels It’s probably not the unreliable synapses.
 It’s not the stochastic nature of ionic channels. It’s probably not the unreliable synapses.")
22
Possible Answers Neurons embedded in a recurrent network with sparse connectivity tend to fire with statistics close to Poisson (Van Vreeswick and Sompolinski) Random walk model (Shadlen and Newsome; Troyer and Miller)
 Random walk model (Shadlen and Newsome; Troyer and Miller)")
23
Problems with the random walk model
The ratio variance over mean is still smaller than the one measured in vivo (0.8 vs 1.2) It’s unstable over several layers! (this is likely to be a problem for any mechanisms…) Noise injection in real neurons fails to produce the predicted variability (Stevens, Zador)
 It’s unstable over several layers! (this is likely to be a problem for any mechanisms…) Noise injection in real neurons fails to produce the predicted variability (Stevens, Zador)")
24
Other sources of noise and uncertainty
Shot noise in the retina Physical noise in the stimulus Uncertainty inherent to the stimulus (e.g. the aperture problem)
")
25
An alternative: information theory
Beyond tuning curves Tuning curves are often non invariant under stimulus changes (e.g. motion tuning curves for blobs vs bars) Deal poorly with time varying stimulus Assume a rate code An alternative: information theory
 Deal poorly with time varying stimulus. Assume a rate code. An alternative: information theory.")
26
Information Theory (Shannon)
")
27
Definitions: Entropy Entropy: Measures the degree of uncertainty
Minimum number of bits required to encode a random variable

28
P(X=1) = p P(X=0) = 1- p Entropy (bits) Probability (p) 1 0.9 0.8 0.7
0.6 Entropy (bits) 0.5 0.4 0.3 0.2 0.1 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Probability (p)
 Probability (p)")
29
Maximum entropy is achieved for flat probability distributions, i. e
Maximum entropy is achieved for flat probability distributions, i.e., for distributions in which events are equally likely. For a given variance, the normal distribution is the one with maximum entropy

30
Entropy of Spike Trains
A spike train can be turned into a binary vector by discretizing time into small bins (1ms or so). Computing the entropy of the spike train amounts to computing the entropy of the binary vector. 1 1 1 1 1 1 1
. Computing the entropy of the spike train amounts to computing the entropy of the binary vector")
31
Definition: Conditional Entropy
Uncertainty due to noise: How uncertain is X knowing Y?

32
Example H(Y|X) is equal to zero if the mapping from X to Y is deterministic and many to one. Ex: Y = X for odd X Y= X+1 for even X X=1, Y is equal to 2. H(Y|X)=0 Y=4, X is either 4 or 3. H(X|Y)>0
=0. Y=4, X is either 4 or 3. H(X|Y)>0.")
33
Example In general, H(X|Y)H(Y|X), except for an invertible and deterministic mapping, in which case H(X|Y)=H(Y|X)=0 Ex: Y= X+1 for all X Y=2, X is equal to 1. H(X|Y)=0 X=1, Y is equal to 2. H(Y|X)=0
=0. X=1, Y is equal to 2. H(Y|X)=0.")
34
Example If Y=f(X)+noise, H(Y|X) and H(X|Y) are strictly greater than zero Ex: Y is the firing rate of a noisy neuron, X is the orientation of a line: ai=fi(q)+ni. Knowing the firing rate does not tell you for sure what the orientation is, H(X|Y)= H(q|ai)>0.
+ni. Knowing the firing rate does not tell you for sure what the orientation is, H(X|Y)= H(q|ai)>0.")
36
Definition: Joint Entropy
Special case. X and Y independent

37
Independent Variables
If X and Y are independent, then knowing Y tells you nothing about X. In other words, knowing Y does not reduce the uncertainty about X, i.e., H(X)=H(X|Y). It follows that:
=H(X|Y). It follows that:")
38
Entropy of Spike Trains
For a given firing rate, the maximum entropy is achieved by a Poisson process because they generate the most unpredictable sequence of spikes .

39
Definition: Mutual Information
Independent variables: H(Y|X)=H(Y)
=H(Y)")
40
Data Processing Inequality
Computation and information transmission can only decrease mutual information: If Z=f(Y), I(Z,X) I(X,Y) In other words, computation can only decrease information or change its format.
, I(Z,X) I(X,Y) In other words, computation can only decrease information or change its format.")
41
KL distance Mutual information can be rewritten as:
This distance is zero when P(X,Y)=P(X)P(Y), i.e., when X and Y are independent.
=P(X)P(Y), i.e., when X and Y are independent.")
42
Measuring entropy from data
Consider a population of 100 neurons firing for 100ms with 1 ms time bins. Each data point is a 100x100 binary vector. The number of possible data point is 2100x100. To compute the entropy we need to estimate a probability distribution over all these states…Hopeless?…

43
Direct Method Fortunately, in general, only a fraction of all possible states actually occurs Direct method: evaluate P(A) and P(A|q) directly from the the data. Still require tons of data but not 2100x100…
 and P(A|q) directly from the the data. Still require tons of data but not 2100x100…")
44
Upper Bound Assume all distributions are gaussian
Recover SNR in the Fourier domain using simple averaging Compute information from the SNR (box 3) No need to recover the full P(R) and P(R|S) because gaussian distributions are fully characterized by their mean and variance.
 No need to recover the full P(R) and P(R|S) because gaussian distributions are fully characterized by their mean and variance.")
45
Lower Bound Estimate a variable from the neuronal responses and compute the mutual information between the estimate and the stimulus (easy if the estimate follows a gaussian distribution) The data processing inequality guarantees that this is a lower bound on information. It gives an idea of how well the estimated variable is encoded.
 The data processing inequality guarantees that this is a lower bound on information. It gives an idea of how well the estimated variable is encoded.")
46
Mutual information in spikes
Among temporal processes, Poisson processes are the one with highest entropy because time bins are independent from one another. The entropy of a Poisson spike train vector is the sum of the individual time bins, which is best you can achieve.

47
Mutual information in spikes
A deterministic Poisson process is the best way to transmit information with spikes Spike trains are indeed close to Poisson BUT they are not deterministic, i.e., they vary from trial to trial even for a fixed input. Even worse, the conditional entropy is huge because the noise follows a poisson distribution

48
The choice of stimulus Neurons are known to be selective to particular features. In information theory terms, this means that two sets of stimuli with the same entropy do necessarily lead to the same amount of mutual information in the response of a neuron. Natural stimuli often lead to larger mutual information (which makes sense since they are more likely)
")
49
Information Theory: Pro
Assumption free: does not assume any particular code Read-out free: does not depend on a read-out method (direct method) It can be used to identify the features best encoded by a neurons
 It can be used to identify the features best encoded by a neurons.")
50
Information theory: Con’s
Does not tell you how to read out the code: the code might be unreadable by the rest of the nervous system. Data intensive: needs TONS of data

51
Animal system Method Bits per second spik e H igh-fr eq. cutoff (Neur on) (efficiency) or limiting Stim ulus timing Fl y visual 10 Lo w r 6 4 1 2 ms (H1) Motion 15 Dir ect 81 — 0.7 37 er and 36 (HS, graded potential) upper 104 Monk 16 5.5 0.6 100 (ar ea MT) dir 12 1.5 Fr og auditor 38 Noise 46 1.4 750 Hz (Auditor ner v ) Call 133 ( 20%) call 7.8 90%) Salamander 50 3.2 1.6 (22%) (Ganglion cells) Random spots Crick et cer cal 40 294 > 500 (Sensor aff ent) 50%) Mechanical motion 51 75–220 0.6–3.1 500–1000 Wind noise 11,38 8–80 A vg = 100–400 (10-2 10-3) Electric fish Absolute 0–200 0–1.2 200 (P-aff lo Amplitude modulation natur e neur os c i e n ce • v o lume 2 no 11 • no v e mb er 1999
 Motion. 15. Dir. ect. 81. — er. and. 36. (HS, graded. potential) upper Monk (ar. ea. MT) dir Fr. og. auditor. 38. Noise Hz. (Auditor. ner. v. ) Call ( 20%) call %) Salamander (22%) (Ganglion. cells) Random. spots. Crick. et. cer. cal > 500. (Sensor. aff. ent) 50%) Mechanical. motion – – –1000. Wind. noise. 11,38. 8–80. A. vg. = 100–400. ( ) Electric. fish. Absolute. 0–200. 0– (P-aff. lo. Amplitude. modulation. natur. e. neur. os. c. i. e. n. ce. • v. o. lume. 2. no. 11. • no. v. e. mb. er")
Similar presentations

 CS414 – Spring 2007 By Karrie Karahalios, Roger Cheng, Brian Bailey.>")


, to each outcome ζ in the sample space of a random experiment. Domain.>")

 Stimulus to response (1-2) Response to stimulus, information in spikes (3-4) Part 2: Neurons.>")

,>")










 multidimensional decision function spike output Y(t) x1x1 x2x2 x3x3 f1f1 f2f2 f3f3 Functional models of.>")