Download presentation
Presentation is loading. Please wait.

1
Hadoop in the Wild CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook

2
Agenda Check out some use cases Discuss some architectures

3
USE CASES

4
Common Use Cases Log Processing Image Identification Extract Transform Load Recommendation Engines Time-Series Storage and Processing Building Search Indexes Long-Term Archive Audit Logging

5
Non-Use Cases Data processing handled by one large server ACID Transactions

6
A Bank Problem – Need to analyze customer activity across multiple products to predict credit risk – Acquired a number of banks Solution – Setup a single Hadoop cluster with data from multiple EDWs – Bank added new sources of customer service data to get a clear picture of a customer’s financial situation

7
A Mobile Carrier Problem – Why are our customers terminating their service contracts? Solution – Combined transactional and event data with social network data – Combined coverage maps with account data

8
An Online Dating Service Problem – Surveys, demographic, and web activity to build a picture – Customers wanted better recommendations – Algorithms improved and number of users grew Solution – Moved data and analysis to Hadoop – Able to size system to meet needs of customers

9
Ad Targeting Problem – Advertising is a special kind of recommendation – Need to select best ad for a particular visitor, but each advertiser is paying to have its ad seen Solution – Collect stream of user activity with continuous analysis – Build sophisticated models of user behavior

10
POS Transaction Analysis Problem – Retailers able to collect much more data in stores and online – EDW do not generally support sophisticated analysis to provide better forecasting Solution – Loaded 20 years of sales transactions and used Hive to do same analysis as before – Now able to use new algorithms with new data sets

11
Sensor Data Problem – Volume of sensor data from every generator across multiple grids is enormous – Clear picture depends on real-time and forensic analysis Solution – Capture and store all streaming sensor data – Built continuous analysis system to watch performance of generators

12
Threat Analysis Problem – How do we detect threats and fraudulent activity in an online world? Solution – Use of HBase to store virus signatures – Use of MapReduce to compare spam or malware Lambda Architecture

13
Trade Surveillance Problem – Difficult to monitor trades for compliance, and impossible to catch rogue traders Solution – Store trade data and trading party data – Continuously monitor activity and build connections – Provides cheap storage for law-required auditing

14
Search Problem – Indexing stuff is pretty easy, until we went and had to index the Internet – User preferences make it harder Solution – MapReduce was designed for indexing – Online retailers depend on search for users finding and buying products

15
Data Sandbox Problem – ??? Solution – Simple storage mechanism with diverse tools for data analysis and exploration

16
ARCHITECTURES

17
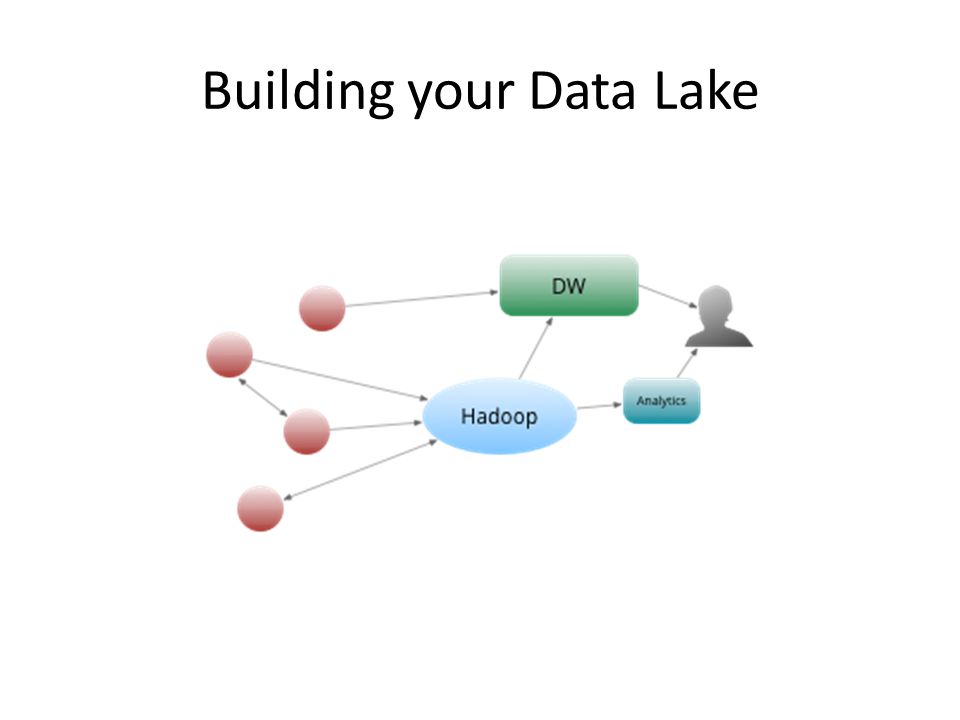
Building your Data Lake

21
12 3 4

22
Lambda Architecture All Data Precompute Views QFD 1 QFD 2 QFD N QFD 1 QFD 2 QFD N Process Stream Increment Views New Data Stream Query Real-Time Increment Batch recompute Storm Real-time views Batch views BATCH LAYER SERVING LAYER SPEED LAYER Hadoop (Apache HBase) (HDFS/SQL)
 (HDFS/SQL)")
23
Facebook EDW (Oracle) was unable to scale and perform Investigated small Hadoop system Engineers loved it Began developing Hive
 was unable to scale and perform Investigated small Hadoop system Engineers loved it Began developing Hive")
24
Facebook Time-series summaries Ad hoc jobs over historical data Long-term archival store for logs Look up log events by specific attributes

25
Facebook Architecture

26
Facebook Messaging Needed a short set of temporal data A growing set of data that is rarely accessed HBase fit their needs more than other open- source technologies

27
Twitter Architecture

28
LinkedIn Architecture

29
LinkedIn Applications

32
LinkedIn Future MapReduce is not suited for large graph processing Batch-oriented nature is not suited for “breaking news”

33
References Hadoop: The Definitive Guide, Chapter 16.2 http://www.slideshare.net/s_shah/the-big-data- ecosystem-at-linkedin-23512853 http://www.slideshare.net/Hadoop_Summit/hadoop- hardware-twitter-size-does-matter http://www.forbes.com/sites/edddumbill/2014/01/14/ the-data-lake-dream/ http://www.slideshare.net/brocknoland/common-and- unique-use-cases-for-apache-hadoop http://blog.cloudera.com/wp- content/uploads/2011/03/ten_common_hadoopable_ problems_final.pdf

Similar presentations