Download presentation
Presentation is loading. Please wait.

1
Organizing the Last Line of Defense before hitting the Memory Wall for Chip-Multiprocessors (CMPs) C. Liu, A. Sivasubramaniam, M. Kandemir The Pennsylvania State University anand@cse.psu.edu

2
Outline CMPs and L2 organization Shared Processor-based Split L2 Evaluation using SpecOMP/Specjbb Summary of Results

3
Why CMPs? Can exploit coarser granularity of parallelism Better use of anticipated billion transistor designs –Multiple and simpler cores Commercial and research prototypes –Sun MAJC –Piranha –IBM Power 4/5 –Stanford Hydra –….

4
Higher pressure on memory system Multiple active threads => larger working set Solution? –Bigger Cache. –Faster interconnect. What if we have to go off-chip? The cores need to share the limited pins. Impact of off-chip accesses may be much worse than incurring a few extra cycles on- chip Needs a close scrutiny of on-chip caches.

5
On-chip Cache Hierarchy Assume 2 levels –L1 (I/D) is private –What about L2? L2 is the last line of defense before going off-chip, and is the focus of this paper.

6
Private (P) L2 I$D$I$D$ L2 $ I NT ER CO NN EC T Coherence Protocol Offchip Memory Advantages: Less interconnect traffic Insulates L2 units Disadvantages: Duplication Load imbalance L1
 L2 I$D$I$D$ L2 $ I NT ER CO NN EC T Coherence Protocol Offchip Memory Advantages: Less interconnect traffic Insulates L2 units Disadvantages: Duplication Load imbalance L1")
7
Shared-Interleaved (SI) L2 Disadvantages: Interconnect traffic Interference between cores Advantages: No duplication Balance the load I$D$I$D$ I NT ER CO NN EC T Coherence Protocol L1 L2
 L2 Disadvantages: Interconnect traffic Interference between cores Advantages: No duplication Balance the load I$D$I$D$ I NT ER CO NN EC T Coherence Protocol L1 L2")
8
Desirables –Approach the behavior of private L2s, when the sharing is not significant –Approach the behavior of private L2 when load is balanced or when there is interference –Approach behavior of shared L2 when there is significant sharing –Approach behavior of shared L2 when demands are uneven.

9
Shared Processor-based Split L2 I NT ER CO NN EC T $$$$$$$$$$$$ Table and Split Select I$D$I$D$ L1 L2 Processors/cores are allocated L2 splits

10
Lookup Look up all splits allocated to requesting core simultaneously. If not found, then look at all other splits (extra latency). If found, move block over to one of its splits (chosen randomly), and removing it from the other split. Else, go off-chip and place block in one of its splits (chosen randomly).
. If found, move block over to one of its splits (chosen randomly), and removing it from the other split. Else, go off-chip and place block in one of its splits (chosen randomly)..")
11
Note … Note, a core cannot place blocks that evict blocks useful to another (as in Private case) A core can look at (shared) blocks of other cores – at a slightly higher cost without being as high as off-chip accesses (as in Shared case). There is at most 1 copy of a block in L2.

12
Shared Split Uniform (SSU) I NT ER CO NN EC T $$$$$$$$$$$$ Table and Split Select I$D$I$D$ L1 L2
 I NT ER CO NN EC T $$$$$$$$$$$$ Table and Split Select I$D$I$D$ L1 L2")
13
Shared Split Non-Uniform (SSN) I NT ER CO NN EC T $$$$$$$$$$$$ Table and Split Select I$D$I$D$ L1 L2
 I NT ER CO NN EC T $$$$$$$$$$$$ Table and Split Select I$D$I$D$ L1 L2")
14
Split Table $$$$$$$$$$ XXX XXXX XX X P3P3 P2P2 P1P1 P0P0

15
Evaluation Using Simics complete system simulator Benchmarks: SpecOMP2000 + Specjbb Reference dataset used Several billion instructions were simulated. A bus interconnect was simulated with MESI.

16
Default configuration # of proc8L2 Assoc4-way L1 Size8KBL2 Latency10 cycles L1 Line Size32 Byte# L2 Splits8 (SI, SSU) L1 Assoc4-way# L2 Splits16 (SSN) L1 Latency1 cycle MEM Access 120 cycles L2 Size2MB total Bus Arbitration 5 cycles L2 Line Size64 Byte Replacement Strict LRU
 L1 Assoc4-way# L2 Splits16 (SSN) L1 Latency1 cycle MEM Access 120 cycles L2 Size2MB total Bus Arbitration 5 cycles L2 Line Size64 Byte Replacement Strict LRU")
17
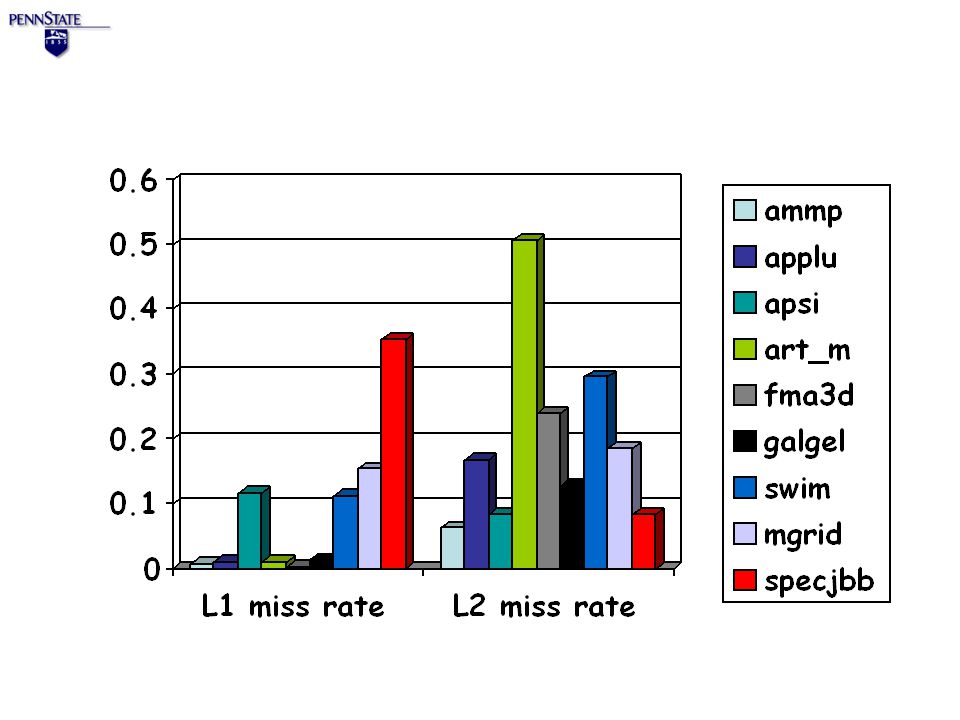
Benchmarks (SpecOMP + Specjbb) Benchmark L1L2 # of Inst (m) # MissRate# MissRate ammp53.1m0.0072.1m0.06225,528 applu111.2m0.00926.4m0.16821,519 apsi378.9m0.11727.2m0.08315,713 art_m66.1m0.00925.7m0.50722,967 fma3d18.9m0.0026.2m0.23926,189 galgel111.4m0.01410.7m0.12724,051 swim261.6m0.11195.9m0.2967,761 mgrid333.2m0.15368.3m0.18510,294 specjbb828.5m0.35322.7m0.0839,413
 Benchmark L1L2 # of Inst (m) # MissRate# MissRate ammp53.1m m ,528 applu111.2m m ,519 apsi378.9m m ,713 art_m66.1m m ,967 fma3d18.9m m ,189 galgel111.4m m ,051 swim261.6m m0.2967,761 mgrid333.2m m ,294 specjbb828.5m m0.0839,413")
18
SSN Terminology With a total L2 of 2MB (16 splits of 128K each) to be allocated to 8 cores, SSN-152 refers to –512K (4 splits) allocated to 1 CPU –256K (2 splits) allocated to each of 5 CPUs –128K (1 split) allocated to each of 2 CPUs Determining how much to allocate to each CPU (and when) – postpone for future work. Here, we use a profile based approach based on L2 demands.

19
Application behavior Intra-application heterogeneity –Spatial: (among CPUs) allocate non-uniform splits to different CPUs. –Temporal: (for each CPU) change the number of splits allocated to a CPU at different points of time. Inter-application heterogeneity –Different applications running at same time can have different L2 demands.
 change the number of splits allocated to a CPU at different points of time. Inter-application heterogeneity –Different applications running at same time can have different L2 demands..")
20
Definition SHF (Spatial Heterogeneity Factor) THF (Temporal Heterogeneity Factor)
 THF (Temporal Heterogeneity Factor)")
21
Spatial heterogeneity Factor

22
Temporal Heterogeneity Factor

23
Results: SI

24
Results: SSU

25
Results: SSN

26
Summary of Results When P does better than S (e.g. apsi), SSU/SSN does as well (if not better) as P. When S does better than P (e.g. swim, mgrid, specjbb), SSU/SSN does as well (if not better) as S. In nearly all cases (except applu), some configuration of SSU/SSN does the best. On the average we get over 11% improvement in IPC over the best S/P configuration(s).
, SSU/SSN does as well (if not better) as P. When S does better than P (e.g. swim, mgrid, specjbb), SSU/SSN does as well (if not better) as S. In nearly all cases (except applu), some configuration of SSU/SSN does the best. On the average we get over 11% improvement in IPC over the best S/P configuration(s)..")
27
Inter-application Heterogenity Different applications have different L2 demands These applications could even be running concurrently on different CPUs.

28
Inter-application results ammp+apsi, low+high. ammp+fma3d, both low swim+apsi, both high, imbalanced + balanced. swim+mgrid, both high, imbalanced + imbalanced

29
Inter-application: ammp+apsi SSN-152 1.25MB dynamically allocated to apsi, 0.75MB to ammp. Graph shows the rough 5:3 allocation. Better overall IPC value. Low miss rate for apsi and not affecting the miss rate of ammp.

30
Concluding Remarks Shared Processor-based Split L2 is a flexible way of approaching the behavior of shared or private L2 (based on what is preferable) It accommodates spatial and temporal heterogeneity in L2 demands both within an application and across applications. Becomes even more important with higher off-chip accesses.

31
Future Work How to configure the split sizes – statically, dynamically and a combination of the two?

32
Backup Slides

34
Meaning Capture the heterogeneity between CPUs (spatial) or over the epochs (temporal) of the load imposed on the L2 structure. Weighted by L1 accesses reflect the effect on the overall IPC. –If the overall access are low, there is not going to be a significant impact on the IPC even though the standard deviation is high.

35
Results: P

36
Results: SI

37
Results: SSU

38
Results Except applu, shared split L2 perform the best. In swim, mgrid, specjbb with high L1 miss rate means higher pressure on L2, which results significant IPC improvement (30.9% to 42.5%)
.")
39
Why private L2 does better in some? L2 performance: –The degree of sharing –The imbalance of load imposed on L2 For applu and swim+apsi, –Only 12% of the blocks are shared at any time, mainly shared between 2 CPUs. –Not much spatial/temporal heterogeneity.

40
Why we use IPC instead of the execution time? We could not finish any of the benchmark, since we are using the “reference” dataset. Another possible indicator is the number of iterations executed of certain loop (for example, the dominating loop) for unit amount of time. We did this and find the direct correlation between the IPC value and the number of iterations. PrivateSSU Average timeipcAverage timeipc apsi loop calling dctdx() (mainloop) 3,349m cycles 3.44 3,048m cycles 3.79
 for unit amount of time. We did this and find the direct correlation between the IPC value and the number of iterations. PrivateSSU Average timeipcAverage timeipc apsi loop calling dctdx() (mainloop) 3,349m cycles ,048m cycles")
41
Results

42
Closer look: specjbb SSU is over 31% better than the private L2. Direct correlation between the L2 misses and the IPC values. P never exceeds 2.5, while SSU sometimes push over 3.0

43
Sensitivity: Larger L2 2MB -> 4MB -> 8MB –Miss rates go down, difference arising from miss rate diminish. ‘swim’ still get considerable savings. –If application size keep growing up, the split shared L2 is still going to help. –More splits of L2 -> finer granularity -> could help SSN.

44
Sensitivity: Longer memory access 120 cycles -> 240 cycles Benefits are amplified

Similar presentations