Download presentation
Presentation is loading. Please wait.

1
Analysis of Classification Algorithms in Handwriting Pattern Recognition Logan Helms Jon Daniele

2
Problem The construction and implementation of computerized systems capable of classifying visual input with speed and accuracy comparable to that of the human brain has remained an open problem in computer science for over 40 years.

13
Formal Statement Given an unknown function (the ground truth) that maps input instances to output labels, along with training data assumed to represent accurate examples of the mapping, produce a function that approximates as closely as possible the correct mapping.
 that maps input instances to output labels, along with training data assumed to represent accurate examples of the mapping, produce a function that approximates as closely as possible the correct mapping.")
14
Basic Pattern Recognition Model

15
Pattern Recognition Preprocessor A system that processes its input data to produce output data that will be used as input data for another system. Classifier A system that attempts to assign each input value to one of a given* set of classes. *A predetermined set of classifications may not always exist

16
MNIST Dataset A subset constructed from NIST’s Special Database 3 (SD-3) and Special Database 1 (SD-1) which contain binary images of handwritten digits. SD-3 was collected from Census Bureau employees SD-1 was collected from high school students Samples are 28x28 pixels, size-normalized and centered Samples contain gray levels as a result of the anti- aliasing technique used by the normalization algorithm. Dataset has been used without further preprocessing.

17
MNIST: Training Set 30,000 from Census Bureau employees 30,000 from high school students

18
MNIST: Testing Set 5,000 from Census Bureau employees 5,000 from high school students

19
Algorithms We Will Analyze Template Matching Naïve Bayes Classifier Feed Forward Neural Network with Backpropagation

20
Template Matching Low hanging fruit

21
Template Matching Digital image processing technique used to match smaller parts of one image that match a template image Multiple approaches: template- matching vs feature-matching Computationally complex

22
Approaches: Template-based Used when there are no 'strong features' available in a template Makes use of the entire template image rather than just portions Becomes difficult with high-resolution images Potentially requires a massive search area to find the best match Facial recognition: Uses the entire face as a template May become difficult if multiple features on a face are obscured or unavailable

23
Approaches: Feature-based Identify specific, 'strong' features in a given template and match those features rather than match the entire template Less computationally complex as it doesn't require the resolution of an entire template May fail when templates are not differentiated between strong features Facial recognition example: Match the relative position of strong facial features, i.e. nose, mouth, ears Match the strong features themselves as well Works at a far lower resolution, which may obscure the features necessary for a template match

24
Bayesian classifier A naïve approach (that works)
")
25
Preconception

26
Bayes' theorem

27
But that’s not naïve!!

28
Some points to note

29
Let’s do this: Leeeeeeroy Jennnnkins!

30
Leroy’s example We have 3 pieces of data each for 1000 players on WoW How loud are they Do people like them How many times do they screw up a raid Training set: Let’s predict Leroy?LoudNot loudDislikedLikedScrew-upNot a screw-upTotal Leroy fanboy 40010035015045050 500 Kinda Leroy 0300150 3000 Not Leroy 100 15050 150 200 Totals500 6503508002001000

31
Easy math: The base rates Class occurences: p(Leroy fanboy) = 0.5 (500/1000) p(Kinda Leroy) = 0.3 p(Not Leroy) = 0.2 Probability of “likelihood” p(Loud/Leroy fanboy) p(Loud/Kinda Leroy) … p(Not a screw-up/Not Leroy) = 0.25 (50/200) p(Screw-up/Not Leroy) = 0.75 Given features from the unknown player p(Loud) = 0.5 p(Disliked) = 0.65 p(Screw-up) = 0.8
 = 0.5 (500/1000) p(Kinda Leroy) = 0.3 p(Not Leroy) = 0.2 Probability of likelihood p(Loud/Leroy fanboy) p(Loud/Kinda Leroy) … p(Not a screw-up/Not Leroy) = 0.25 (50/200) p(Screw-up/Not Leroy) = 0.75 Given features from the unknown player p(Loud) = 0.5 p(Disliked) = 0.65 p(Screw-up) = 0.8")
32
Easy math: the base rates Feature per class: Feature/Class total LoudNot loudNot likedLikedScrew-upNot a screw-up Leroy Fanboy 0.80.20.70.30.90.1 Kinda Leroy 0.01.00.5 1.00.0 Not Leroy 0.5 0.750.25 0.75 Probability of class: Class/total players Leroy Fanboy 0.5 Kinda Leroy 0.3 Not Leroy 0.2 Features from evidence: Feature/total players Loud 0.5 Disliked 0.65 Screw-up 0.8

33
Bad math Ok, here’s a new player on Wow, and we want to know into which category of player they should be placed. Are they a Leroy fanboy, Kinda Leroy, or Not a Leroy? We observe the following characteristics for the unknown player: Loud Disliked Screw-up We run the numbers for each of the 3 outcomes, then choose the one with the highest probability and classify the unknown player as part of the class with highest probability according to our base rates established by the training set.

34
Bad math, cont’d

37
Bad math, fin We now have the following probabilities: Leroy fanboy:0.252 Kinda Leroy: 0 Not Leroy:0.01875 And now we know that the new player falls into the Leroy fanboy category of players!

38
Feed Forward Neural Network with Backpropagation The birth of SKYNET

39
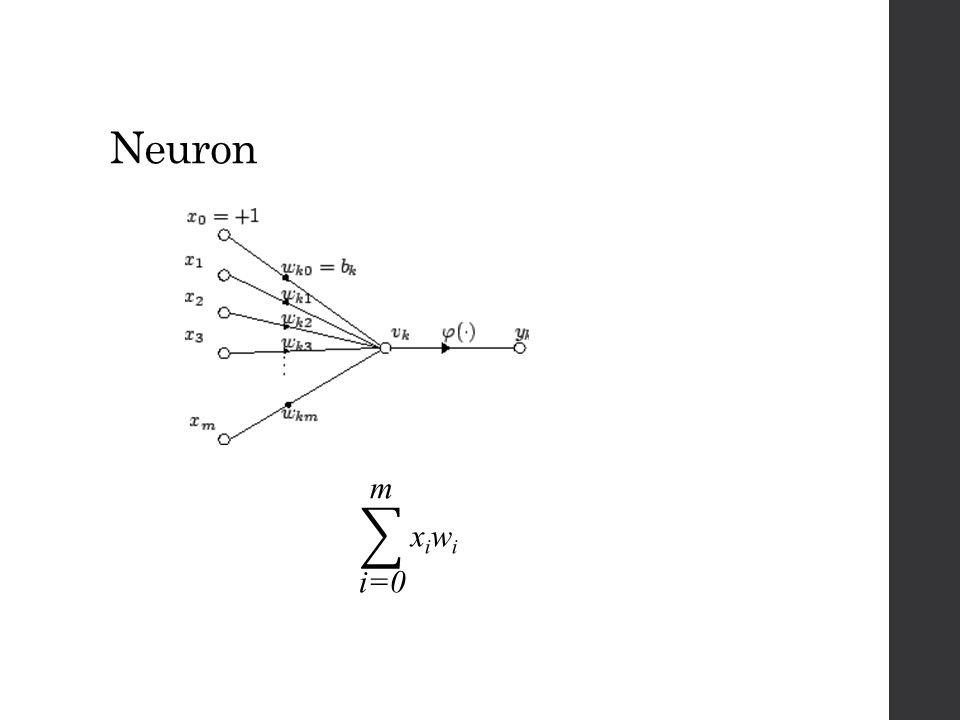
Neural Network A computational model inspired by central nervous systems, in particular the brain. Generally presented as systems of interconnected neurons in a brain. Neuron is the basic unit.

40
Neuron

42
Transfer Function Backpropagation requires the transfer function be differentiable. We chose to use sigmoid function for our transfer function because it is easily differentiable and easier to work with.

43
Feed Forward Neural Network

44
Solutions are known Weights are learned Evolves in the weight space Used for: Prediction Classification Function approximation

45
Backpropagation Common method of training neural networks Backpropagation requires the transfer function to be differentiable. Two Step Process 1. Propagation 2. Weight update

46
1. Propagation Forward propagation of a training pattern’s input through the neural network in order to generate the propagation’s output activations. Backward propagation of the propagation’s output activations through the neural network using the training pattern target in order to generate the deltas of all output and hidden neurons.

47
2. Weight Update Each weight-synapse will follow these steps: Multiply its output delta and input activation to get the gradient of the weight. Subtract a ratio (percentage) of the gradient from the weight.
 of the gradient from the weight..")
48
Network Error Total-Sum-Squared-Error (TSSE) Root-Mean-Squared-Error (RMSE)
 Root-Mean-Squared-Error (RMSE)")
49
A Pseudo-Code Algorithm Randomly choose the initial weights While error is too large For each training pattern (in random order) Apply the inputs to the network Propagation (as described earlier) Weight Update (as described earlier) Apply weight adjustments Periodically evaluate the network performance
 Apply the inputs to the network Propagation (as described earlier) Weight Update (as described earlier) Apply weight adjustments Periodically evaluate the network performance")
50
Constraints As a control, each classification algorithm will be presented with the MNIST test set, in the exact same order.

51
Hypothesis The neural network will match samples to targets with a higher accuracy than the template matching and Naïve Bayes classifier.

52
Hypothesis Testing Accuracy is defined as such: In addition we will also test the following: Implementation: Based on ease of implementation Average Runtime: Based on average of end time – start time of running an algorithm Overall Feasibility: All factors taken into account for the desired use-case.

Similar presentations












>")

>")





 by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley.>")







 –Perceptrons –Feed-forward.>")


