Download presentation
Presentation is loading. Please wait.

1
Esma Yildirim Department of Computer Engineering Fatih University Istanbul, Turkey DATACLOUD 2013

2
Data Scheduling Services in the Cloud Data Scheduling Services in the Cloud File Transfer Scheduling Problem History File Transfer Scheduling Problem History Implementation Details of the Client Implementation Details of the Client Example Algorithms Example Algorithms Amazon EC2 Experiments Amazon EC2 Experiments Conclusions Conclusions

3
Data Clouds strive for novel services for management, analysis, access and scheduling of Big Data Data Clouds strive for novel services for management, analysis, access and scheduling of Big Data Application level protocols providing high performance in high speed networks is an integral part of data scheduling services Application level protocols providing high performance in high speed networks is an integral part of data scheduling services GridFTP, UDP based protocols are used frequently in Modern Day Schedulers (e.g. GlobusOnline, StorkCloud) GridFTP, UDP based protocols are used frequently in Modern Day Schedulers (e.g. GlobusOnline, StorkCloud)
 GridFTP, UDP based protocols are used frequently in Modern Day Schedulers (e.g. GlobusOnline, StorkCloud).")
4
Data is large, diverse and complex Data is large, diverse and complex Transferring large datasets faces many bottlenecks Transferring large datasets faces many bottlenecks Transport protocol’s under utilization of network Transport protocol’s under utilization of network End-system limitations (e.g. CPU, NIC and disk speed) End-system limitations (e.g. CPU, NIC and disk speed) Dataset characteristics Dataset characteristics Many short duration transfers Many short duration transfers Connection startup and tear down overhead Connection startup and tear down overhead
 End-system limitations (e.g. CPU, NIC and disk speed) Dataset characteristics Dataset characteristics Many short duration transfers Many short duration transfers Connection startup and tear down overhead Connection startup and tear down overhead.")
6
Setting optimal parameters for different datasets is a challenging task Setting optimal parameters for different datasets is a challenging task Data Scheduling Services sets static values based on experiences Data Scheduling Services sets static values based on experiences Provided tools do not comply with dynamic intelligent algorithms that might change settings on the fly Provided tools do not comply with dynamic intelligent algorithms that might change settings on the fly

7
Flexibility to scalable data scheduling algorithms Flexibility to scalable data scheduling algorithms On the fly changes to the optimization parameters On the fly changes to the optimization parameters Reshaping the dataset characteristics Reshaping the dataset characteristics

8
Lies at the origin of the data scheduling services Lies at the origin of the data scheduling services Dates back to 1980s Dates back to 1980s Earliest approaches: List scheduling Earliest approaches: List scheduling Sort the transfers based on size, bandwidth of the path or duration of the transfer Sort the transfers based on size, bandwidth of the path or duration of the transfer Near-optimal solution Near-optimal solution Integer programming – not feasible to implement Integer programming – not feasible to implement

9
Scalable approaches: Scalable approaches: Transferring from multiple replicas Transferring from multiple replicas Divided datasets sent over different paths to make use of additional network bandwidth Divided datasets sent over different paths to make use of additional network bandwidth Adaptive approaches Adaptive approaches Divide files into multiple portions to send over parallel streams Divide files into multiple portions to send over parallel streams Divide dataset into multiple portions and send at the same time Divide dataset into multiple portions and send at the same time Adaptively change level of concurrency or parallelism based on network throughput Adaptively change level of concurrency or parallelism based on network throughput Optimization algorithms Optimization algorithms Find optimal settings via modeling and set the optimal parameters once and for all Find optimal settings via modeling and set the optimal parameters once and for all

10
Modern Day Data Scheduling Service Example Modern Day Data Scheduling Service Example Globus Online Globus Online Hosted SaaS Hosted SaaS Statically set pipelining, concurrency and parallelism Statically set pipelining, concurrency and parallelism Stork Stork Multi-protocol support Multi-protocol support Finds optimal parallelism level based on modeling Finds optimal parallelism level based on modeling Static job concurrency Static job concurrency

11
Allow dataset transfers to be Allow dataset transfers to be Enqueued, dequeued Enqueued, dequeued Sorted based on a property Sorted based on a property Divided, combined into chunks Divided, combined into chunks Grouped by source-destination paths Grouped by source-destination paths Done from multiple replicas Done from multiple replicas

12
Lacks of globus-url-copy Lacks of globus-url-copy Does not let even static setting of pipelining, uses its own default value invisible to the user Does not let even static setting of pipelining, uses its own default value invisible to the user globus-url-copy -pp -p 5 -cc 4 src url dest url globus-url-copy -pp -p 5 -cc 4 src url dest url A directory of files can not be divided and set different optimization parameters A directory of files can not be divided and set different optimization parameters Filelist option does help but it can not apply pipelining on the list as the developers indicates Filelist option does help but it can not apply pipelining on the list as the developers indicates globus-url-copy -pp -p 5 -cc 4 -f filelist.txt globus-url-copy -pp -p 5 -cc 4 -f filelist.txt

13
File data structure properties File data structure properties File size: used to construct data chunks based on total size, throughput calculation, transfer duration calculation File size: used to construct data chunks based on total size, throughput calculation, transfer duration calculation Source and destination paths: necessary for combining and dividing datasets, changing the source path based on replica location Source and destination paths: necessary for combining and dividing datasets, changing the source path based on replica location File name: Necessary to reconstruct full paths File name: Necessary to reconstruct full paths

14
Listing the files for a given path Listing the files for a given path Contacts the GridFTP server Contacts the GridFTP server Pulls information about the files in the given path Pulls information about the files in the given path Provides a list of file data structures including the number of files Provides a list of file data structures including the number of files Makes it easier to divide, combine, sort, enqueue and dequeue on a list of files Makes it easier to divide, combine, sort, enqueue and dequeue on a list of files

15
Performing the actual transfer Performing the actual transfer Sets the optimization parameters on a list of files returned by the list function and manipulated by different algorithms Sets the optimization parameters on a list of files returned by the list function and manipulated by different algorithms For a data chunk it sets the parallel stream, concurrency and pipelining value For a data chunk it sets the parallel stream, concurrency and pipelining value

16
Takes a file list structure returned by the list function as input Takes a file list structure returned by the list function as input Divides the file list into chunks based on the number of files in a chunk Divides the file list into chunks based on the number of files in a chunk Starting with concurrency level of 1, transfer each chunk with an exponentially increasing concurrency level as long as the throughput increases by each chunk transfer Starting with concurrency level of 1, transfer each chunk with an exponentially increasing concurrency level as long as the throughput increases by each chunk transfer If the throughput drops adaptively the concurrency level is also decreased for the subsequent chunk transfer If the throughput drops adaptively the concurrency level is also decreased for the subsequent chunk transfer

18
Mean-based algorithm to construct clusters of files with different optimal pipelining levels Mean-based algorithm to construct clusters of files with different optimal pipelining levels Calculates optimal pipelining level by dividing BDP into mean file size of the chunk Calculates optimal pipelining level by dividing BDP into mean file size of the chunk Dataset is recursively divided by the mean file size index as long as the following conditions are met: Dataset is recursively divided by the mean file size index as long as the following conditions are met: A chunk can only be divided further as long as its pipelining level is different than its parent chunk A chunk can only be divided further as long as its pipelining level is different than its parent chunk A chunk can not be less than a preset minimum chunk size A chunk can not be less than a preset minimum chunk size Optimal pipelining level for a chunk cannot be greater than a preset maximum pipelining level Optimal pipelining level for a chunk cannot be greater than a preset maximum pipelining level

20
After the recursive division of chunks, pp opt is set for each chunk After the recursive division of chunks, pp opt is set for each chunk Chunks go through a revision phase where smaller chunks are combined and larger chunks are further divided Chunks go through a revision phase where smaller chunks are combined and larger chunks are further divided Starting with cc = 1, each chunk is transferred with exponentially increased cc levels until throughput drops down Starting with cc = 1, each chunk is transferred with exponentially increased cc levels until throughput drops down The rest of the chunks are transferred with the optimal cc level The rest of the chunks are transferred with the optimal cc level

22
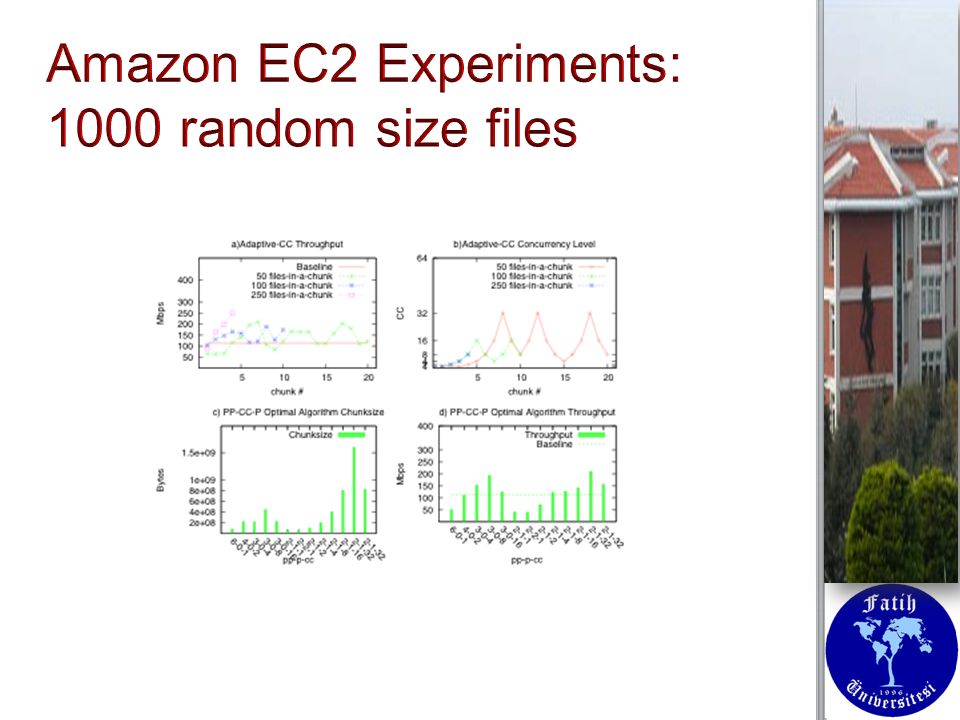
Large nodes with 2vCPUs, 8GB storage, 7.5 GB memory and moderate network performance Large nodes with 2vCPUs, 8GB storage, 7.5 GB memory and moderate network performance 50ms artificial delay 50ms artificial delay Globus Provision is used to automatic setup of servers Globus Provision is used to automatic setup of servers Datasets comprise of many number of small files (most difficult optimization case) Datasets comprise of many number of small files (most difficult optimization case) 5000 1MB files 5000 1MB files 1000 random size files in range 1Byte to 10MB 1000 random size files in range 1Byte to 10MB
 Datasets comprise of many number of small files (most difficult optimization case) MB files MB files 1000 random size files in range 1Byte to 10MB 1000 random size files in range 1Byte to 10MB")
23
Baseline performance: Default pipelining+data channel caching Baseline performance: Default pipelining+data channel caching Throughput achieved is higher than baseline for majority of cases Throughput achieved is higher than baseline for majority of cases

25
The flexible GridFTP client has the ability to comply with different natured data scheduling algorithms The flexible GridFTP client has the ability to comply with different natured data scheduling algorithms Adaptive and optimization algorithms easily sort, divide and combine datasets Adaptive and optimization algorithms easily sort, divide and combine datasets Possibility to implement intelligent cloud scheduling services in an easier way Possibility to implement intelligent cloud scheduling services in an easier way

Similar presentations











 with 3 nodes each. Each node with 4 x 10 GE NICs Measure various overheads from protocols and file sizes.>")


 CMPT 886 Represented By: Lilong Shi.>")




![High Performance Cooperative Data Distribution [J. Rick Ramstetter, Stephen Jenks] [A scalable, parallel file distribution model conceptually based on.](/16/5222846/big_thumb.jpg "High Performance Cooperative Data Distribution [J. Rick Ramstetter, Stephen Jenks] [A scalable, parallel file distribution model conceptually based on.>")




