Download presentation
Presentation is loading. Please wait.

1
Von Neuman (Min-Max theorem) Claude Shannon (finite look-ahead) Chaturanga, India (~550AD) (Proto-Chess) John McCarthy ( pruning) Donald Knuth ( analysis)
 Claude Shannon (finite look-ahead) Chaturanga, India (~550AD) (Proto-Chess) John McCarthy ( pruning) Donald Knuth ( analysis)")
2
Wilmer McLean The war began in my front yard and ended in my front parlor

3
Deep Thought: Chess is easy for but the pesky opponent Search: If I do A, then I will be in S, then if I do B, then I will get to S’ Game Search: If I do A, then I will be in S, then my opponent gets to do B. then I will be forced to S’. Then I get to do C,..

4
Snakes-and-ladders is perfect information with chance think of the utter boringness of deterministic snakes and ladders Not that the normal snakes-and-ladders has any real scope for showing your thinking power (your only action is dictated by the dice—so the dice can play it as a solitaire—at most they need your hand..). Kriegspiel (blind-fold chess) Snakes & Ladders?
 Snakes & Ladders .")
6
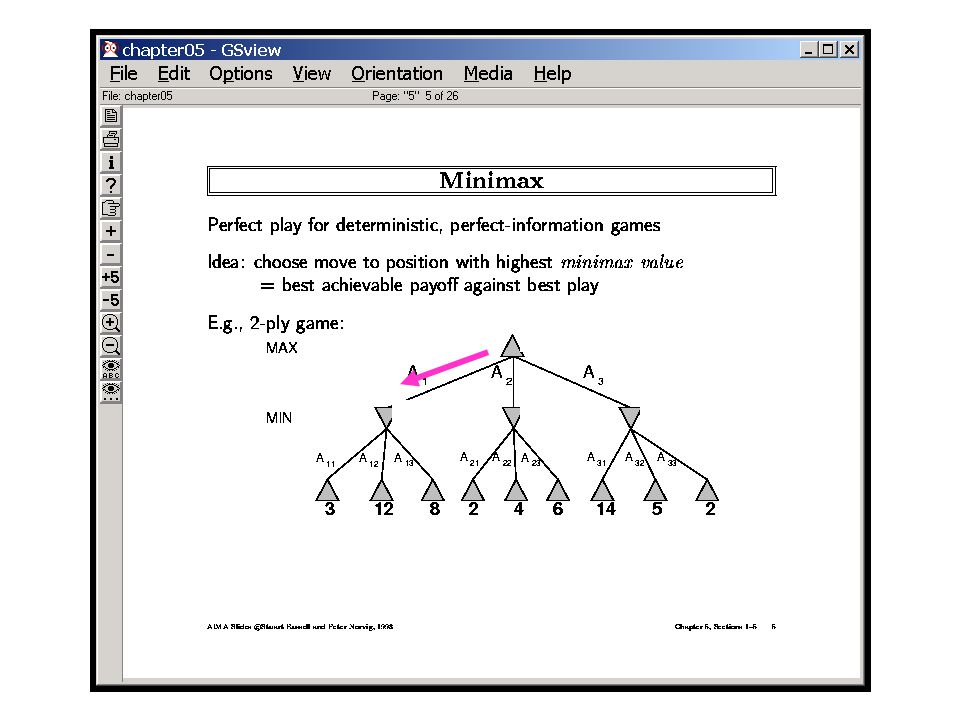
Searching Tic Tac Toe using Minmax A game is considered Solved if it can be shown that the MAX player has a winning (or at least Non-losing) Strategy This means that the backed-up Value in the Full min-max Tree is +ve
 Strategy This means that the backed-up Value in the Full min-max Tree is +ve")
9
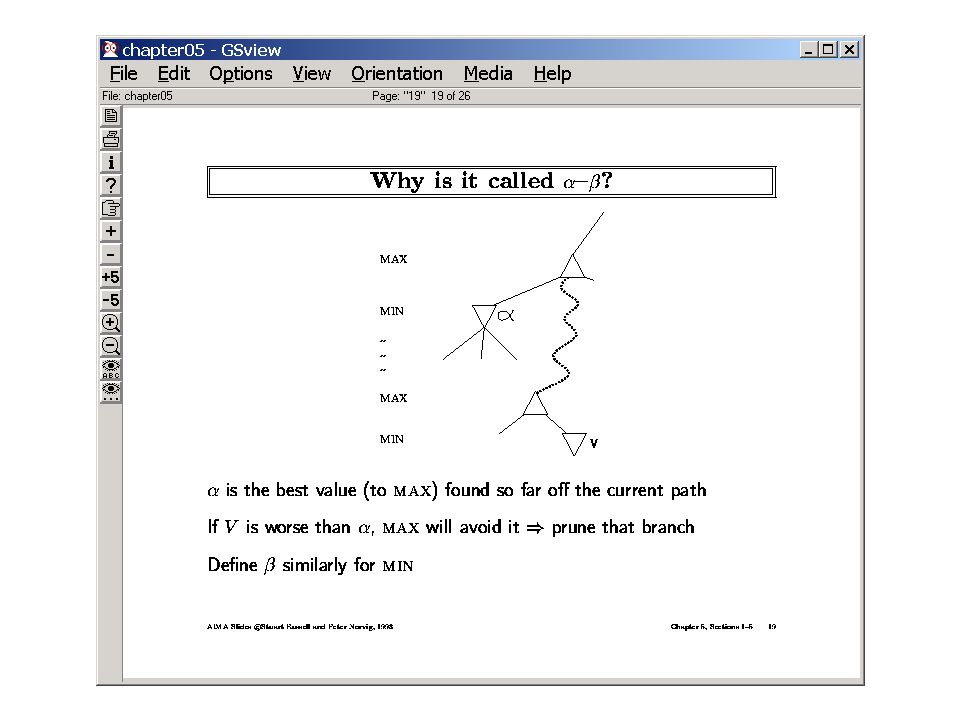
2 <= 2 Cut 14 <= 14 5 <= 5 2 <= 2 Whenever a node gets its “true” value, its parent’s bound gets updated When all children of a node have been evaluated (or a cut off occurs below that node), the current bound of that node is its true value Two types of cutoffs: If a min node n has bound =j, then cutoff occurs as long as j >=k If a max node n has bound >=k, and a min ancestor of n, say m, has a bound <=j, then cutoff occurs as long as j<=k
, the current bound of that node is its true value Two types of cutoffs: If a min node n has bound =j, then cutoff occurs as long as j >=k If a max node n has bound >=k, and a min ancestor of n, say m, has a bound <=j, then cutoff occurs as long as j<=k")
10
Another alpha-beta example

11
Click for an animation of Alpha-beta search in action on Tic-Tac-Toen animation of Alpha-beta search in action on Tic-Tac-Toe (order nodes in terms of their static eval values)
")
14
Evaluation Functions: TicTacToe If win for Max +infty If lose for Max -infty If draw for Max 0 Else # rows/cols/diags open for Max - #rows/cols/diags open for Min

17
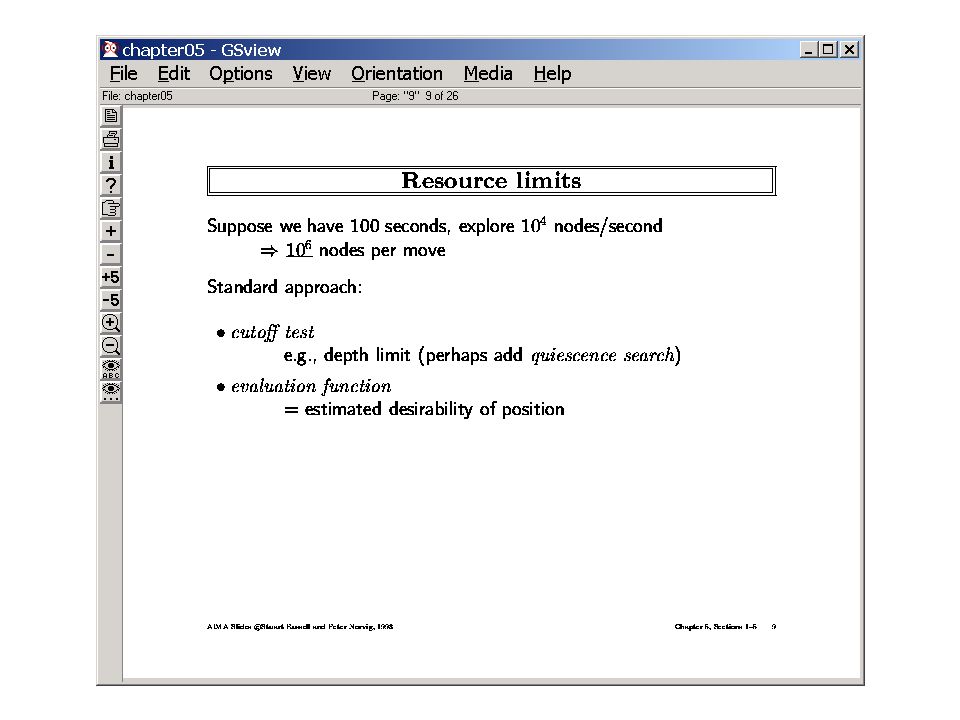
What depth should we go to? --Deeper the better (but why?) Should we go to uniform depth? --Go deeper in branches where the game is in a flux (backed up values are changing fast) [Called “Quiescence” ] Can we avoid the horizon effect?
 [Called Quiescence ] Can we avoid the horizon effect .")
18
Depth Cutoff and Online Search Until now we considered mostly “all or nothing” computations –The computation takes the time it takes, and only at the end will give any answer When the agent has to make decisions online, it needs flexibility in the time it can devote to “thinking” (“deliberation scheduling”) –Can’t do it if we have all-or-nothing computations. We need flexibile or anytime computations The depth-limited min-max is an example of an anytime computation. –Pick a small depth limit. Do the analysis w.r.t. that tree. Decide the best move. Keep it as a back up. If you have more time, go deeper and get a better move. Online Search is not guaranteed to be optimal --The agent may not even survive unless the world is ergodic (non-zero prob. of reach any state from any other state)
.")
19
Why is “deeper” better? Possible reasons –Taking mins/maxes of the evaluation values of the leaf nodes improves their collective accuracy –Going deeper makes the agent notice “traps” thus significantly improving the evaluation accuracy All evaluation functions first check for termination states before computing the non-terminal evaluation If this is indeed the case, then we should remember the backed-up values for game positions—since they are better than straight evaluations

20
(just as human weight lifters refuse to compete against cranes)
")
21
Uncertain Actions & Games Against Nature

22
[can generalize to have action costs C(a,s)] If M ij matrix is not known a priori, then we have a reinforcement learning scenario.. Repeat
![[can generalize to have action costs C(a,s)] If M ij matrix is not known a priori, then we have a reinforcement learning scenario..](http://images.slideplayer.com/13/4173675/slides/slide_22.jpg "Repeat.")
23
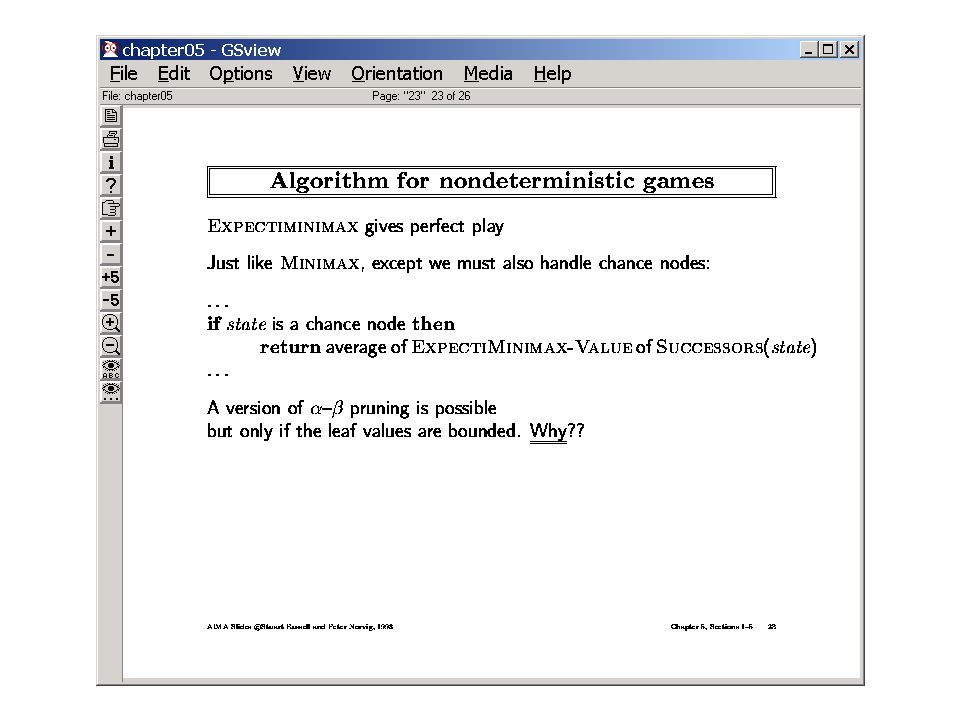
3,2 4,23,33,13,33,24,2 -0.04.8.1.8.1 This is a game against the nature, and nature decides which outcome of each action will occur. How do you think it will decide? I am the chosen one: So nature will decide the course that is most beneficial to me [Max-Max] I am the Loser: So nature will decide the course that is least beneficial to me [Min-Max] I am a rationalist: Nature is oblivious of me—and it does what it does—so I do “expectation analysis” Leaf node values have been set to their immediate rewards Can do better if we set to them to an estimate of their expected value..

24
Real Time Dynamic Programming Interleave “search” and “execution” (Real Time Dynamic Programming) Do limited-depth analysis based on reachability to find the value of a state (and there by the best action you should be doing—which is the action that is sending you the best value) The values of the leaf nodes are set to be their immediate rewards –Alternatively some admissible estimate of the value function (h*) If all the leaf nodes are terminal nodes, then the backed up value will be true optimal value. Otherwise, it is an approximation… RTDP For leaf nodes, can use R(s) or some heuristic value h(s)
 or some heuristic value h(s).")
25
The expected value computation is fine if you are maximizing “expected” return If you are --if you are risk-averse? (and think “nature” is out to get you) V 2 = min(V 3,V 4 ) If you are perpetual optimist then V 2 = max(V 3,V 4 ) If you have deterministic actions then RTDP becomes RTA* (if you use h(.) to evaluate leaves
 V 2 = min(V 3,V 4 ) If you are perpetual optimist then V 2 = max(V 3,V 4 ) If you have deterministic actions then RTDP becomes RTA* (if you use h(.) to evaluate leaves.")
26
RTA* (RTDP with deterministic actions and leaves evaluated by f(.)) Sn m k G S n m G=1 H=2 F=3 G=1 H=2 F=3 k G=2 H=3 F=5 infty --Grow the tree to depth d --Apply f-evaluation for the leaf nodes --propagate f-values up to the parent nodes f(parent) = min( f(children)) RTA* is a special case of RTDP --It is useful for acting in determinostic, dynamic worlds --While RTDP is useful for actiong in stochastic, dynamic worlds LRTA*: Can store backed up values for states (and they will be better heuristics)
) Sn m k G S n m G=1 H=2 F=3 G=1 H=2 F=3 k G=2 H=3 F=5 infty --Grow the tree to depth d --Apply f-evaluation for the leaf nodes --propagate f-values up to the parent nodes f(parent) = min( f(children)) RTA* is a special case of RTDP --It is useful for acting in determinostic, dynamic worlds --While RTDP is useful for actiong in stochastic, dynamic worlds LRTA*: Can store backed up values for states (and they will be better heuristics)")
27
End of Gametrees

28
Game Playing (Adversarial Search) Perfect play –Do minmax on the complete game tree Alpha-Beta pruning (a neat idea that is the bane of many a CSE471 student) Resource limits –Do limited depth lookahead –Apply evaluation functions at the leaf nodes –Do minmax Miscellaneous –Games of Chance –Status of computer games..
 Perfect play –Do minmax on the complete game tree Alpha-Beta pruning (a neat idea that is the bane of many a CSE471 student) Resource limits –Do limited depth lookahead –Apply evaluation functions at the leaf nodes –Do minmax Miscellaneous –Games of Chance –Status of computer games..")
29
(so is MDP policy)
")
32
Multi-player Games Everyone maximizes their utility --How does this compare to 2-player games? (Max’s utility is negative of Min’s)
.")
33
Expecti-Max

Similar presentations










>")
















