Download presentation
2
Overview Types of Missing Data Strategies for Handling Missing Data Software Applications and Examples

3
Sources of Missing Data ◦ Item non-response Missing value for any given item ◦ Scale non-response Missing value for any given scale Often a result of item non-response ◦ Attrition Missing value (item and/or scale) for any given time point ◦ Data entry error Observed value not included
 for any given time point ◦ Data entry error Observed value not included")
4
So I have missing data…what’s the big deal? ◦ Missing data, no matter how minimal, can (and probably do) result in biased results ◦ Statistical power ◦ Validity
 result in biased results ◦ Statistical power ◦ Validity.")
5
How much missing data is “problematic”? Depends on who you ask… Answer #1 ANY Answer #2 Its never “too much” Optimal methods can easily accommodate 50% missing data Answer #3 >5% (Schafer, 1999) >10% (Bennett, 2001) >20% (Peng, et al., 2006) Answer #4 (Widaman, 2006) 1%-2% (Negligible) 5%-10% (Minor) 10%-25% (Moderate) 25%-50% (High) >50% (Excessive)
 >10% (Bennett, 2001) >20% (Peng, et al., 2006) Answer #4 (Widaman, 2006) 1%-2% (Negligible) 5%-10% (Minor) 10%-25% (Moderate) 25%-50% (High) >50% (Excessive).")
6
Missing Completely at Random (MCAR) Missing at Random (MAR) Not Missing at Random (NMAR)
 Missing at Random (MAR) Not Missing at Random (NMAR)")
7
Missing Completely at Random (MCAR) ◦ Missing values on Y are unrelated to any other variable in the analysis ◦ Cases with missing data can be treated as a random subset of the entire sample ◦ Best case scenario; difficult to ascertain
 ◦ Missing values on Y are unrelated to any other variable in the analysis ◦ Cases with missing data can be treated as a random subset of the entire sample ◦ Best case scenario; difficult to ascertain")
8
Missing at Random (MAR) ◦ Missing values on Y are related to X but not to Y ◦ Missing values on Y are random (random effect)after controlling for X (systematic effect ◦ Can test systematic effect but not random effect
 ◦ Missing values on Y are related to X but not to Y ◦ Missing values on Y are random (random effect)after controlling for X (systematic effect ◦ Can test systematic effect but not random effect")
9
Not Missing at Random (NMAR) ◦ Missing values on Y are related to Y itself ◦ Missing data are “non-ignorable” ◦ Difficult to ascertain; difficult to manage
 ◦ Missing values on Y are related to Y itself ◦ Missing data are non-ignorable ◦ Difficult to ascertain; difficult to manage")
10
Testing for MCAR ◦ Little’s Test of MCAR Omnibus χ 2 test of all specified variables If significant, data are not MCAR May be MAR or MNAR If not significant, can assume MCAR Available in SPSS under “Missing Value Analysis” and as a SAS Macro

11
Testing for MAR ◦ Create a “dummy” variable for not missing/missing on the variable of interest ◦ Conduct statistical tests to see if other relevant variables are associated with values of the new variable Binomial logistic regression χ 2 test of independence t-tests ◦ If significant relationships are found, then have MAR; these variables need to be included in any analyses ◦ If no significant relationships found, then you have more work to do

12
If not MCAR or MAR, does that mean it is MNAR? ◦ Not necessarily… Might still be MAR but you haven’t found the right indicator variable ◦ Consider other potentially relevant variables and test against the missing data “dummy” variable

13
Patterns of missing data ◦ Monotone pattern Variables v 1 -v j can be ordered so that if data are missing on v 1, they are missing on all successive variables VERY common with longitudinal data

14
Patterns of missing data ◦ Non-monotone pattern Patterns of missing data are arbitrary

15
Deletion Methods ◦ Remove cases with missing values Non-Stochastic Methods ◦ Replace missing values with “known” values Stochastic Methods ◦ Replace missing values with estimated values

16
List-Wise Deletion ◦ Mechanism Deletes cases from analysis with missing data on any variable (even if that variable isn’t part of the analysis) Only uses “complete cases” ◦ Pros Easy to implement Works for any kind of statistical analysis If data are MCAR, does not introduce any bias in parameter estimates Standard error estimates are appropriate ◦ Cons May delete a large proportion of cases, resulting in loss of statistical power May introduce bias if MAR but not MCAR
 Only uses complete cases ◦ Pros Easy to implement Works for any kind of statistical analysis If data are MCAR, does not introduce any bias in parameter estimates Standard error estimates are appropriate ◦ Cons May delete a large proportion of cases, resulting in loss of statistical power May introduce bias if MAR but not MCAR")
17
Pair-Wise Deletion ◦ Mechanism Deletes cases when missing data on a specific variable involved in parameter estimation Uses all available information for each estimation, independent of information available for other estimations ◦ Pros Approximately unbiased if MCAR Uses all available information ◦ Cons Standard errors are incorrect

19
Mean Imputation ◦ Mechanism All missing values on a given variable are replaced by the sample mean for that variable ◦ Pros Leaves sample mean of non-missing values unchanged ◦ Cons Often leads to biased parameter estimates (e.g., variances) Usually leads to standard error estimates that are biased downward Treats imputed data as real data, ignores inherent uncertainty in imputed values.
 Usually leads to standard error estimates that are biased downward Treats imputed data as real data, ignores inherent uncertainty in imputed values.")
20
Individual Mean Imputation ◦ Mechanism Scale scores are computed by taking the mean of non-missing values Ex: Respondent answered 8 of 10 questions on Miller Anxiety Scale – Compute Scale score by taking mean of available cases ◦ Pros All available information for a given individual is used in the estimation of missing values ◦ Cons Assumes the items with missing values are similar in difficulty or extremity to items with non-missing data May lead to biased scores

21
Regression ◦ Mechanism Missing values are replaced by “predicted” values derived from MR using all relevant variables ◦ Pros Predicted values maintain relationships among variables ◦ Cons Predicted values are “perfect” and lead to positively biased estimates

23
Stochastic Regression (aka “Simple Imputation”) ◦ Mechanism Similar to non-stochastic regression in the available data are used to predict missing values Adds a random value to the predicted value by sampling from a normal distribution with a mean of zero and variance equal to the residual variance of the regression equation ◦ Pros Improvement over Non-Stochastic methods Provides unbiased variance estimates ◦ Cons Only uses a single estimation step and may produce inaccurate or unusual values
 ◦ Mechanism Similar to non-stochastic regression in the available data are used to predict missing values Adds a random value to the predicted value by sampling from a normal distribution with a mean of zero and variance equal to the residual variance of the regression equation ◦ Pros Improvement over Non-Stochastic methods Provides unbiased variance estimates ◦ Cons Only uses a single estimation step and may produce inaccurate or unusual values")
25
Expectation Maximization (EM) ◦ Mechanism 2-step iterative process Step 1: Expectation Use parameter values (initially based on complete-case data) to estimate values for missing data Step 2: Maximization Use complete-case data and estimated values for missing data to estimate new model parameters Repeat until results converge (Successive iterations will not yield different parameters) ◦ Pros Minimizes bias in parameter estimates (larger samples yield less bias) Ideal for exploratory and reliability analyses ◦ Cons Initial estimates based on list-wise deletion (doesn’t use all available data) Biased standard errors (minimized with larger samples) Less efficient than FIML for hypothesis testing
 ◦ Mechanism 2-step iterative process Step 1: Expectation Use parameter values (initially based on complete-case data) to estimate values for missing data Step 2: Maximization Use complete-case data and estimated values for missing data to estimate new model parameters Repeat until results converge (Successive iterations will not yield different parameters) ◦ Pros Minimizes bias in parameter estimates (larger samples yield less bias) Ideal for exploratory and reliability analyses ◦ Cons Initial estimates based on list-wise deletion (doesn’t use all available data) Biased standard errors (minimized with larger samples) Less efficient than FIML for hypothesis testing")
27
Full Information Maximum Likelihood (FIML) ◦ Mechanism Directly estimates parameters using all observed data for every case ◦ Pros Only requires a single step for imputation and analysis Uses all available data even if some cases are missing data Unbiased standard errors Can be used with smaller samples (N<100) ◦ Cons All variables related to missing data need to be included in the analysis
 ◦ Mechanism Directly estimates parameters using all observed data for every case ◦ Pros Only requires a single step for imputation and analysis Uses all available data even if some cases are missing data Unbiased standard errors Can be used with smaller samples (N<100) ◦ Cons All variables related to missing data need to be included in the analysis")
29
Multiple Imputation (MI) ◦ Mechanism Creates multiple data set using stochastic regression Minimum of 3-5 recommended, but no limit on maximum (Schafer, 1997) Each data set will be slightly different because of the random component Parameters are estimated for each data set and then averaged ◦ Pros Produces unbiased parameter estimates Produces unbiased standard errors Easy to include auxiliary variables ◦ Cons Labor intensive Can be difficult to integrate multiple data sets
 ◦ Mechanism Creates multiple data set using stochastic regression Minimum of 3-5 recommended, but no limit on maximum (Schafer, 1997) Each data set will be slightly different because of the random component Parameters are estimated for each data set and then averaged ◦ Pros Produces unbiased parameter estimates Produces unbiased standard errors Easy to include auxiliary variables ◦ Cons Labor intensive Can be difficult to integrate multiple data sets")
31
Comparison of Stochastic Methods GoodBetterBest Stochastic Regression Expectation-Maximization Multiple Imputation Full Information Maximum Likelihood

32
SPSS/PASWSASAMOS/MPLUS/LISREL Deletion Non-Stochastic Replacement Simple Imputation EM FIML MI

33
Modeling problematic child behavior outcomes Predictors ◦ Positive Parenting ◦ Social Skills ◦ Interpartner Violence ◦ Child Sex N=181 Original data set missing 4 observations (<.5%) New data set created for purpose of demonstration
 New data set created for purpose of demonstration")
34
◦ Little’s Test of MCAR can be obtained as part of PASW “Missing Values Analysis” Little's MCAR test: Chi-Square = 36.014, DF = 18, Sig. =.007 Conclude that data are not MCAR (not surprising given that I did not delete values in a random manner)
.")
35
Test of MAR can be conducted by creating new dichotomous variable for “Not Missing/Missing” and using it as the outcome variable in a logistic regression model Most interested in missing data on outcome variable in this example, but method is not limited to that Conclude that pattern of missing data is related to Gender Little's MCAR test for Boys: Chi-Square = 8.338, DF = 14, Sig. =.871* Little's MCAR test for Girls: Chi-Square = 13.026, DF = 18, Sig. =.790* *We can conclude that data are MCAR within each group. Gender must be included in any missing data analysis to minimize bias.

38
Although the pattern is not monotone, these cases only make up a very small %

39
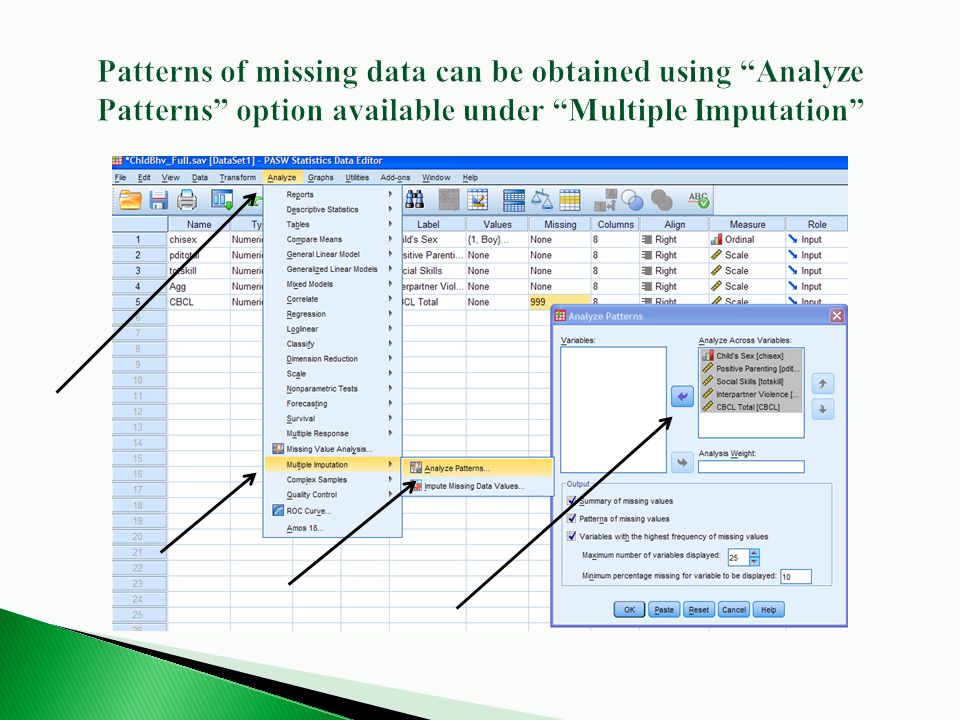
PASW provides several options for handling missing data The add-on module for “Missing Values Analysis” allows you to implement several different strategies simultaneously ◦ In addition to saving time, comparison output is provided for means, SDs, and correlation/covariance matrices Available options: ◦ List-wise deletion ◦ Pair-wise deletion ◦ Stochastic regression ◦ EM

40
Enter continuous and categorical variables Choose strategies Additional options

41
The “Multiple Imputation” option is part of the basic PASW package ◦ Provides numerous options Choose # of iterations Choose estimation method (monotone vs. non-monotone patterns) Create new data sets
 Create new data sets.")
42
Enter all variables to use in imputation (model + auxiliary) Choose # of iterations Create a new data set with imputed data Note: PASW allows you to run analysis on all imputed sets simultaneously
 Choose # of iterations Create a new data set with imputed data Note: PASW allows you to run analysis on all imputed sets simultaneously")
43
“Automatic” is the default Can manually select method based on pattern of missing data If your data include interactions, so should your imputation model

44
Multiple Imputation available in PreLIS under “Statistics” I have included both model and auxiliary variables Select estimation method EM -> monotone MCMC -> non-monotone Decide how to handle cases when all data are missing Output is a “complete” data set for analysis

45
An alternative to MI is to use FIML estimation with the original data set containing missing values LISREL will default to this option if there is missing data

46
Complete List-WisePair-Wise B Std. Error Sig. B Std. Error Sig. B Std. ErrorSig. (Constant) 83.715.29.00091.476.57.00091.347.01.000 Child's Sex -.751.38.586-.641.72.709-.581.79.748 Positive Parenting -1.03.22.000-1.27.27.000-1.34.28.000 Social Skills -.20.06.001-.26.08.001-.21.08.000 Interpartner Violence.14.06.024.10.07.136.07.006
 Child s Sex Positive Parenting Social Skills Interpartner Violence")
47
Complete Mean SubstitutionSimple Imputation B Std. Error Sig. B Std. Error Sig. B Std. ErrorSig. (Constant) 83.715.29.00085.375.21.00080.876.01.000 Child's Sex -.751.38.586-.421.19.709-.181.48.904 Positive Parenting -1.03.22.000-1.17.22.000-1.06.24.000 Social Skills -.20.06.001-.16.05.001-.12.06.049 Interpartner Violence.14.06.024.07.05.136.05.06.390
 Child s Sex Positive Parenting Social Skills Interpartner Violence")
48
Complete EM-PASWMCMC-LISRELFIML-LISREL B Std. Error Sig. B Std. Error Sig. B Std. ErrorSig.B Std. ErrorSig. (Constant) 83.715.29.00091.524.99.00092.965.32.00088.835.86.000 Child's Sex -.751.38.586-.351.16.761-.181.59.359-.23.79.799 Positive Parenting -1.03.22.000-1.36.21.000-1.24.26.000-1.19.26.000 Social Skills -.20.06.001-.22.05.000-.23.06.000-.25.07.000 Interpartner Violence.14.06.024.09.05.073.11.06.051.11.06.076
 Child s Sex Positive Parenting Social Skills Interpartner Violence")
49
The goal of handling missing data is to find values close to the “real” (but absent) values. (T or F) ◦ FALSE – the goal is to estimate unbiased standard errors and parameter estimates Which is more important – amount of missing data or type of missing data? ◦ Both are important, but type is more important than amount List-wise deletion is a good strategy for handling missing data? (T or F) ◦ TRUE – if data are MCAR; if not MCAR, then there are better alternatives There are no “good” strategies for handling data that are NMAR. (T or F) ◦ TRUE – but FIML is considered to yield the least biased results
 ◦ FALSE – the goal is to estimate unbiased standard errors and parameter estimates Which is more important – amount of missing data or type of missing data. ◦ Both are important, but type is more important than amount List-wise deletion is a good strategy for handling missing data. (T or F) ◦ TRUE – if data are MCAR; if not MCAR, then there are better alternatives There are no good strategies for handling data that are NMAR. (T or F) ◦ TRUE – but FIML is considered to yield the least biased results.")
50
Deletion is the only strategy for handling missing categorical data. (T or F) ◦ FALSE – can use both non-stochastic and stochastic methods If using multiple imputation, it is best to include all available variables. (T or F) ◦ FALSE – only include variables related to those with missing data Values such as “not applicable”, “not sure”, “I don’t know”, etc. should be treated as missing data. (T or F) ◦ FALSE – if you included these as possible response categories, then they constitute valid responses (i.e., they are not missing) List-wise deletion is better than non-stochastic imputation. (T or F) ◦ TRUE – if data are MCAR and/or unless using a small sample with minimal power
 ◦ FALSE – can use both non-stochastic and stochastic methods If using multiple imputation, it is best to include all available variables. (T or F) ◦ FALSE – only include variables related to those with missing data Values such as not applicable , not sure , I don’t know , etc. should be treated as missing data. (T or F) ◦ FALSE – if you included these as possible response categories, then they constitute valid responses (i.e., they are not missing) List-wise deletion is better than non-stochastic imputation. (T or F) ◦ TRUE – if data are MCAR and/or unless using a small sample with minimal power.")
51
Missing data should only be imputed for predictor variables and never for outcome variables. (T or F) ◦ DEPENDS – if you have good auxiliary variables for the outcome variable, then you should impute on the outcome variable; otherwise you should not impute. Values such as “not applicable”, “not sure”, “I don’t know”, etc. can be treated as missing data. (T or F) ◦ TRUE – IF you have a strong theoretical argument that a different response would have been obtained under different circumstances The most important factor in choosing a strategy is the type of missing data. (T or F) TRUE Analyses should always be conducted and reported using data with and without missing values. (T or F) ◦ TRUE
 ◦ DEPENDS – if you have good auxiliary variables for the outcome variable, then you should impute on the outcome variable; otherwise you should not impute. Values such as not applicable , not sure , I don’t know , etc. can be treated as missing data. (T or F) ◦ TRUE – IF you have a strong theoretical argument that a different response would have been obtained under different circumstances The most important factor in choosing a strategy is the type of missing data. (T or F) TRUE Analyses should always be conducted and reported using data with and without missing values. (T or F) ◦ TRUE.")
52
Causes (actual and/or hypothesized) of missing data should be discussed The amount of missing data and the strategy used to handle it should be reported Results of analyses with and without missing data should be discussed The most appropriate strategy should be used
 of missing data should be discussed The amount of missing data and the strategy used to handle it should be reported Results of analyses with and without missing data should be discussed The most appropriate strategy should be used")
53
StrategyType of Missing Data MCARMARNMAR List-wise Deletion Pair-wise Deletion Non-stochastic Replacement Simple Imputation EM FIML Multiple Imputation

54
Allison, P. D. (2001). Missing data. Thousand Oaks, CA: Sage Publications. Bennett, D.A. (2001). How can I deal with missing data in my study? Australian and New Zealand Journal of Public Health, 25, 464-469. Little, R.J.A. (1988). A test of missing completely at random for multivariate data with missing values. Journal of the American Statistical Association, 83, 1198-1202. Little, R. J. A., & Rubin, D.B. (1987). Statistical analysis with missing data. John Wiley & Sons, New York. Peng, C.Y., Harwell, M., Liou, S.M., & Ehman, L.H. (2006). Advances in missing data methods and implications for educational research. In S Sawilowsky (Ed.), Real data analysis (pp.31-78), Greenwich, CT: Information Age. Schafer, J.L. (1997). Analysis of incomplete multivariate data. Thousand Oaks, CA: Sage. Schafer, J.L. (1999). Multiple imputation: A primer. Statistical Methods in Medical Research. 8: 3-15. Schlomer, G.L., Bauman, S., & Card, N.A. (2010). Best practices for missing data management in counseling psychology. Journal of Counseling Psychology, 57(1), 1-10. Widaman, K.F. (2006). Missing data: What to do with or without them. Monographs of the Society for Research in Child Development, 71(3), 42-64.
. How can I deal with missing data in my study. Australian and New Zealand Journal of Public Health, 25, Little, R.J.A. (1988). A test of missing completely at random for multivariate data with missing values. Journal of the American Statistical Association, 83, Little, R. J. A., & Rubin, D.B. (1987). Statistical analysis with missing data. John Wiley & Sons, New York. Peng, C.Y., Harwell, M., Liou, S.M., & Ehman, L.H. (2006). Advances in missing data methods and implications for educational research. In S Sawilowsky (Ed.), Real data analysis (pp.31-78), Greenwich, CT: Information Age. Schafer, J.L. (1997). Analysis of incomplete multivariate data. Thousand Oaks, CA: Sage. Schafer, J.L. (1999). Multiple imputation: A primer. Statistical Methods in Medical Research. 8: Schlomer, G.L., Bauman, S., & Card, N.A. (2010). Best practices for missing data management in counseling psychology. Journal of Counseling Psychology, 57(1), Widaman, K.F. (2006). Missing data: What to do with or without them. Monographs of the Society for Research in Child Development, 71(3),")