Download presentation
Presentation is loading. Please wait.

1
Top 500 Computers Federated Distributed Systems Anda Iamnitchi

2
Objectives and Outline Question to answer in the end: differences between clusters and supercomputers? Top 500 computers: –List –How is it decided? (Linpack Benchmark) –Some historical data IBM Blue Gene Earth Simulator
 –Some historical data IBM Blue Gene Earth Simulator.")
4
System components BG/L Objective: 65,536 nodes produced in 130-nm copper IBM CMOS 8SFG technology. Each node: a single application-specific integrated circuit (ASIC) with two processors and nine double-data-rate (DDR) synchronous dynamic random access memory (SDRAM) chips. The SoC ASIC that powers the node incorporates all of the functionality needed by BG/L. It also contains 4 MB of extremely high-bandwidth embedded DRAM [15] that is of the order of 30 cycles from the registers on most L1/L2 cache misses.15 Nodes are physically small, allowing for very high packaging density.
 with two processors and nine double-data-rate (DDR) synchronous dynamic random access memory (SDRAM) chips. The SoC ASIC that powers the node incorporates all of the functionality needed by BG/L. It also contains 4 MB of extremely high-bandwidth embedded DRAM [15] that is of the order of 30 cycles from the registers on most L1/L2 cache misses.15 Nodes are physically small, allowing for very high packaging density..")
6
System components BG/L (cont) Power is critical: densities achieved are a factor of 2 to 10 greater than those available with traditional high-frequency uniprocessors. System packaging: 512 processing nodes, each with a peak performance of 5.6 Gflops, on a doubled-sided board, or midplane, (20 in. by 25 in). Each node contains two processors, which makes it possible to vary the running mode. Each compute node has a small operating system that can handle basic I/O tasks and all functions necessary for high-performance code. For file systems, compiling, diagnostics, analysis, and service of BG/L, an external host computer (or computers) is required. The I/O nodes contain a software layer above the layer on the compute nodes to handle communication with the host. Partitioning the machine space in a manner that enables each user to have a dedicated set of nodes for their application, including dedicated network resources. This partitioning is utilized by a resource allocation system which optimizes the placement of user jobs on hardware partitions in a manner consistent with the hardware constraints.
. Each node contains two processors, which makes it possible to vary the running mode. Each compute node has a small operating system that can handle basic I/O tasks and all functions necessary for high-performance code. For file systems, compiling, diagnostics, analysis, and service of BG/L, an external host computer (or computers) is required. The I/O nodes contain a software layer above the layer on the compute nodes to handle communication with the host. Partitioning the machine space in a manner that enables each user to have a dedicated set of nodes for their application, including dedicated network resources. This partitioning is utilized by a resource allocation system which optimizes the placement of user jobs on hardware partitions in a manner consistent with the hardware constraints..")
7
ComponentDescriptionNo. per rack Node card16 compute cards, two I/O cards32 Compute card Two compute ASICs, DRAM512 I/O cardTwo compute ASICs, DRAM, Gigabit Ethernet2 to 64, selectable Link cardSix-port ASICs8 Service cardOne to twenty clock fan-out, two Gigabit Ethernet to 22 Fast Ethernet fan-out, miscellaneous rack functions, 2.5/3.3-V persistent dc 2 Midplane16 node cards2 Clock fan- out card One to ten clock fan-out with and without master oscillator1 Fan unitThree fans, local control20 Power system ac/dc1 Compute rack With fans, ac/dc power1

9
Nodes are interconnected through five networks, the most significant of which is a 64 × 32 × 32 three-dimensional torus that has the highest aggregate bandwidth and handles the bulk of all communication. There are virtually no asymmetries in this interconnect. This allows for a simple programming model because there are no edges in a torus configuration.

11
Principles: 1.Simplicity for ease of development and high reliability, e.g.: One job per partition (hence, no protection for communication) One thread per processor (hence, more deterministic computation and scalability) No virtual memory (hence, no page faults, thus more deterministic computation) 2.Performance 3.Familiarity: programming environments popular with scientists (MPI) for portability.
 One thread per processor (hence, more deterministic computation and scalability) No virtual memory (hence, no page faults, thus more deterministic computation) 2.Performance 3.Familiarity: programming environments popular with scientists (MPI) for portability.")
14
The Earth Simulator: Development Schedule

15
Development Goals Distributed Memory Parallel Computing System which 640 processor nodes interconnected by Single-Stage Crossbar Network Processor Node: 8 vector processors with shared memory Peak Performance: 40 Tflops Total Main Memory: 10 TB Inter-node data transfer rate: 12.3GB/s x2 Target for Sustained Performance: 5 Tflops using Atmosphere general circulation model (AGCM). *The goal above was its thousand times' performance of the AGCM in those times (1997).
..")
16
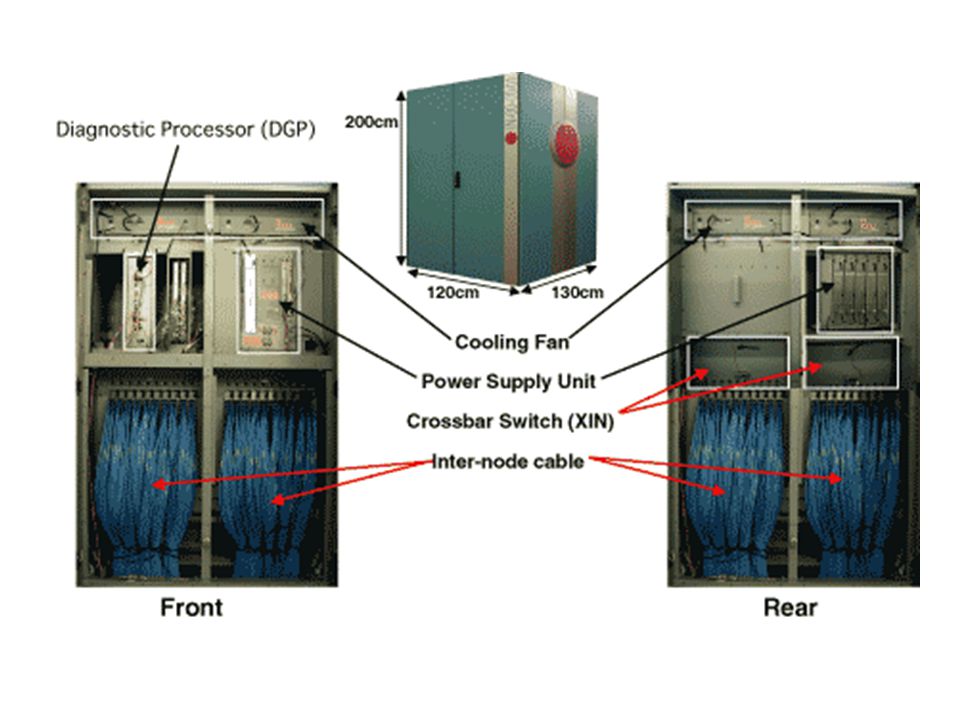
System Configuration The ES is a highly parallel vector supercomputer system of the distributed-memory type, and consisted of 640 processor nodes (PNs) connected by 640x640 single-stage crossbar switches. Each PN is a system with a shared memory, consisting of 8 vector-type arithmetic processors (APs), a 16- GB main memory system (MS), a remote access control unit (RCU), and an I/O processor. The peak performance of each AP is 8Gflops. The ES as a whole thus consists of 5120 APs with 10 TB of main memory and the theoretical performance of 40Tflops Peak performance/AP: 8Gflops; Total number of APs: 5120 Peak performance/PN: 64 Gflops; Total number of PNs: 640 Shared memory/PN: 16G; Total peak performance: 40Tflops Total main memory10TB
, a 16- GB main memory system (MS), a remote access control unit (RCU), and an I/O processor. The peak performance of each AP is 8Gflops. The ES as a whole thus consists of 5120 APs with 10 TB of main memory and the theoretical performance of 40Tflops Peak performance/AP: 8Gflops; Total number of APs: 5120 Peak performance/PN: 64 Gflops; Total number of PNs: 640 Shared memory/PN: 16G; Total peak performance: 40Tflops Total main memory10TB.")
17
Each PN is a system with a shared memory with: 8 vector-type arithmetic processors (APs): peak performance 8Gflops 16-GB main memory system (MS) remote access control unit (RCU) an I/O processor Thus, 5120 APs with 10 TB of main memory and the theoretical performance of 40Tflops Highly parallel vector supercomputer system with distributed memory: 640 processor nodes (PNs) connected by 640x640 single- stage crossbar switches.
: peak performance 8Gflops 16-GB main memory system (MS) remote access control unit (RCU) an I/O processor Thus, 5120 APs with 10 TB of main memory and the theoretical performance of 40Tflops Highly parallel vector supercomputer system with distributed memory: 640 processor nodes (PNs) connected by 640x640 single- stage crossbar switches.")
19
The RCU is directly connected to the crossbar switches and controls inter- node data communications at 12.3GB/s bidirectional transfer rate for both sending and receiving data. Thus the total bandwidth of inter-node network is about 8TB/s.

20
The number of Cables which connects PN cabinet and IN cabinet is 640x130=83200, and the total extension is 2,400Km.

23
Figure 1: Super Cluster System of ES: A hierarchical management system is introduced to control the ES. Every 16 nodes are collected as a cluster system and therefore there are 40 sets of cluster in total. A set of cluster is called an "S-cluster" which is dedicated for interactive processing and small-scale batch jobs. A job within one node can be processed on the S-cluster. The other sets of cluster is called "L-cluster" which are for medium-scale and large-scale batch jobs. Parallel processing jobs on several nodes are executed on some sets of cluster. Each cluster has a cluster control station (CCS) which monitors the state of the nodes and controls electricity of the nodes belonged to the cluster. A super cluster control station (SCCS) plays an important role of integration and coordination of all the CCS operations.
 which monitors the state of the nodes and controls electricity of the nodes belonged to the cluster. A super cluster control station (SCCS) plays an important role of integration and coordination of all the CCS operations..")
24
Parallel File System If a large parallel job running on 640 PNs reads from/writes to one disk installed in a PN, each PN accesses to the disk in sequence and performance degrades terribly. Although local I/O in which each PN reads from or writes to its own disk solves the problem, it is a very hard work to manage such a large number of partial files. Therefore, parallel I/O is greatly demanded in ES from the point of view of both performance and usability. The parallel file system (PFS) provides the parallel I/O features to ES (Figure 2). It enables handling multiple files, which are located on separate disks of multiple PNs, as logically one large file. Each process of a parallel program can read/write distributed data from/to the parallel file concurrently with one I/O statement to achieve high performance and usability of I/O. Figure 2: Parallel File System (PFS): A parallel file, i.e. file on PFS is striped and stored cyclically in the specified blocking size into the disk of each PN. When a program accesses to the file, the File Access Library (FAL) sends a request for I/O via IN to the File Server on the node that owns the data to be accessed.
 provides the parallel I/O features to ES (Figure 2). It enables handling multiple files, which are located on separate disks of multiple PNs, as logically one large file. Each process of a parallel program can read/write distributed data from/to the parallel file concurrently with one I/O statement to achieve high performance and usability of I/O. Figure 2: Parallel File System (PFS): A parallel file, i.e. file on PFS is striped and stored cyclically in the specified blocking size into the disk of each PN. When a program accesses to the file, the File Access Library (FAL) sends a request for I/O via IN to the File Server on the node that owns the data to be accessed..")
25
2 types of queues: L: production run S: single-node batch jobs (pre- and post-processing: creating initial data, processing results of a simulation and other processes

26
Programming Model in ES The ES hardware has a 3-level hierarchy of parallelism: vector processing in an AP, parallel processing with shared memory in a PN, and parallel processing among PNs via IN. To bring out high performance of ES fully, one must develop parallel programs that make the most use of such parallelism.

28
Yellow: theoretical peak; Pink: 30% sustained performance. The top three were honorees of the Gordon Bell Award 2002 (peek performance, language and special accomplishments). Nov. 2003: The Gordon Bell Award for Peak Performance: Modeling of global seismic wave propagation on the Earth Simulator (5Tflops) Nov. 2004: The Gordon Bell Award for Peak Performance: The simulation of a dynamo and geomagnetic fields by the Earth Simulator (15.2Tflops)
. Nov. 2003: The Gordon Bell Award for Peak Performance: Modeling of global seismic wave propagation on the Earth Simulator (5Tflops) Nov. 2004: The Gordon Bell Award for Peak Performance: The simulation of a dynamo and geomagnetic fields by the Earth Simulator (15.2Tflops).")
29
Cluster vs. Supercomputer? …

Similar presentations


















>")
 BlueGene/L IBM Journal of Research and Development, Vol. 49, No. 2-3.>")








