Download presentation
Presentation is loading. Please wait.

1
Capriccio: Scalable Threads for Internet Services Rob von Behren, Jeremy Condit, Feng Zhou, Geroge Necula and Eric Brewer University of California at Berkeley Presenter: Olusanya Soyannwo

2
Outline Motivation Background Goals Approach Experiments Results Related work Conclusion & Future work EECS Advanced Operating Systems Northwestern University

3
Motivation Increasing scalability demands for Internet services Hardware improvements are limited by existing software Current implementations are event based EECS Advanced Operating Systems Northwestern University

4
Background : Event Based Systems - Drawbacks Events systems hide the control flow Difficult to understand and debug Programmers need to match related events Burdens programmers EECS Advanced Operating Systems Northwestern University

5
Goals: Capriccio Support for existing thread API Scalability to hundreds of thousands of threads Automate application-specific customization EECS Advanced Operating Systems Northwestern University

6
Approach: Capriccio Thread package Cooperative scheduling Linked stacks Address the problem of stack allocation for large numbers of threads Combination of compile-time and run- time analysis Resource-aware scheduler EECS Advanced Operating Systems Northwestern University

7
Approach: User Level Thread – The Choice POSIX API (-)Complex preemption (-)Bad interaction with Kernel scheduler Performance Ease thread synchronization overhead No kernel crossing for preemptive threading More efficient memory management at user level Flexibility Decoupling user and kernel threads allows faster innovation Can use new kernel thread features without changing application code Scheduler tailored for applications EECS Advanced Operating Systems Northwestern University
Complex preemption (-)Bad interaction with Kernel scheduler Performance Ease thread synchronization overhead No kernel crossing for preemptive threading More efficient memory management at user level Flexibility Decoupling user and kernel threads allows faster innovation Can use new kernel thread features without changing application code Scheduler tailored for applications EECS Advanced Operating Systems Northwestern University")
8
Approach: User Level Thread – Disadvantages Additional Overhead Replacing blocking calls with non- blocking calls Multiple CPU synchronization EECS Advanced Operating Systems Northwestern University

9
Approach: User Level Thread – Implementation Context Switches Built on top of Edgar Toernig’s coroutine library Fast context switches when threads voluntarily yield I/O Capriccio intercepts blocking I/O calls Uses epoll for asynchronous I/O Scheduling Very much like an event-driven application Events are hidden from programmers Synchronization Supports cooperative threading on single-CPU machines Requires only Boolean checks EECS Advanced Operating Systems Northwestern University

10
Approach: Linked Stack The problem: fixed stacks Overflow vs. wasted space Limits thread numbers The solution: linked stacks Allocate space as needed Compiler analysis Add runtime checkpoints Guarantee enough space until next check Fixed Stacks Linked Stack EECS Advanced Operating Systems Northwestern University

11
Approach: Linked Stack Parameters MaxPath MinChunk Steps Break cycles Trace back Special Cases Function pointers External calls 5 4 2 6 3 3 2 3 MaxPath = 8 EECS Advanced Operating Systems Northwestern University

12
Approach: Linked Stack Parameters MaxPath MinChunk Steps Break cycles Trace back Special Cases Function pointers External calls 5 4 2 6 3 3 2 3 MaxPath = 8 EECS Advanced Operating Systems Northwestern University

13
Approach: Linked Stack Parameters MaxPath MinChunk Steps Break cycles Trace back Special Cases Function pointers External calls 5 4 2 3 3 2 3 MaxPath = 8 6 EECS Advanced Operating Systems Northwestern University

14
Approach: Linked Stack Parameters MaxPath MinChunk Steps Break cycles Trace back Special Cases Function pointers External calls 5 3 MaxPath = 8 6 3 2 2 4 3 EECS Advanced Operating Systems Northwestern University

15
Approach: Linked Stack Parameters MaxPath MinChunk Steps Break cycles Trace back Special Cases Function pointers External calls MaxPath = 8 6 3 2 2 4 3 3 3 EECS Advanced Operating Systems Northwestern University

16
Approach: Scheduling Advantages of event-based scheduling Tailored for applications With event handlers Events provide two important pieces of information for scheduling Whether a process is close to completion Whether a system is overloaded EECS Advanced Operating Systems Northwestern University

17
Approach: Scheduling - The Blocking Graph Close Write ReadSleep ThreadcreateMain Thread-based View applications as sequence of stages, separated by blocking calls Analogous to event-based scheduler EECS Advanced Operating Systems Northwestern University

18
Approach: Resource-aware Scheduling Track resources used along BG edges Memory, file descriptors, CPU Predict future from the past Algorithm Increase use when underutilized Decrease use near saturation Advantages Operate near the knee w/o thrashing Automatic admission control EECS Advanced Operating Systems Northwestern University

19
Experiment: Threading Microbenchmarks SMP, two 2.4 GHz Xeon processors 1 GB memory two 10 K RPM SCSI Ultra II hard drives Linux 2.5.70 Compared Capriccio, LinuxThreads, and Native POSIX Threads for Linux EECS Advanced Operating Systems Northwestern University

20
Experiment: Thread Scalability Producer-consumer microbenchmark LinuxThreads begin to degrade after 20 threads NPTL degrades after 100 Capriccio scales to 32K producers and consumers (64K threads total) EECS Advanced Operating Systems Northwestern University
 EECS Advanced Operating Systems Northwestern University")
21
Results: Thread Primitive - Latency CapriccioLinuxThreadsNPTL Thread creation 21.5 17.7 Thread context switch 0.240.710.65 Uncontended mutex lock 0.040.140.15 EECS Advanced Operating Systems Northwestern University

22
Results: Thread Scalability EECS Advanced Operating Systems Northwestern University

23
Results: I/O performance Network performance Token passing among pipes Simulates the effect of slow client links 10% overhead compared to epoll Twice as fast as both LinuxThreads and NPTL when more than 1000 threads Disk I/O comparable to kernel threads EECS Advanced Operating Systems Northwestern University

24
Results: Runtime Overhead Tested Apache 2.0.44 Stack linking 73% slowdown for null call 3-4% overall Resource statistics 2% (on all the time) 0.1% (with sampling) Stack traces 8% overhead EECS Advanced Operating Systems Northwestern University
 0.1% (with sampling) Stack traces 8% overhead EECS Advanced Operating Systems Northwestern University")
25
Results: Web Server Performance EECS Advanced Operating Systems Northwestern University

26
Related Work Programming Model of high concurrency Event based models are a result of poor thread implementations User-Level Threads Capriccio is unique Kernel Threads NPTL Application Specific Optimization SPIN & Exokernel Burden on programmers Portability Asynchronous I/O Stack Management Using heap requires a garbage collector (ML of NJ) EECS Advanced Operating Systems Northwestern University
 EECS Advanced Operating Systems Northwestern University")
27
Related Work (cont’d) Resource Aware Scheduling Several similar to capriccio
 Resource Aware Scheduling Several similar to capriccio")
28
Future Work Threading Multi-CPU support Kernel interface (enabled) Compile-time techniques Variations on linked stacks Static blocking graph Scheduling More sophisticated prediction EECS Advanced Operating Systems Northwestern University
 Compile-time techniques Variations on linked stacks Static blocking graph Scheduling More sophisticated prediction EECS Advanced Operating Systems Northwestern University")
29
Conclusion Capriccio simplifies high concurrency Scalable & high performance Control over concurrency model Stack safety Resource-aware scheduling Enables compiler support, invariants Issues Additional burden to programmer Resource controlled sched.? What hysteresis? EECS Advanced Operating Systems Northwestern University

30
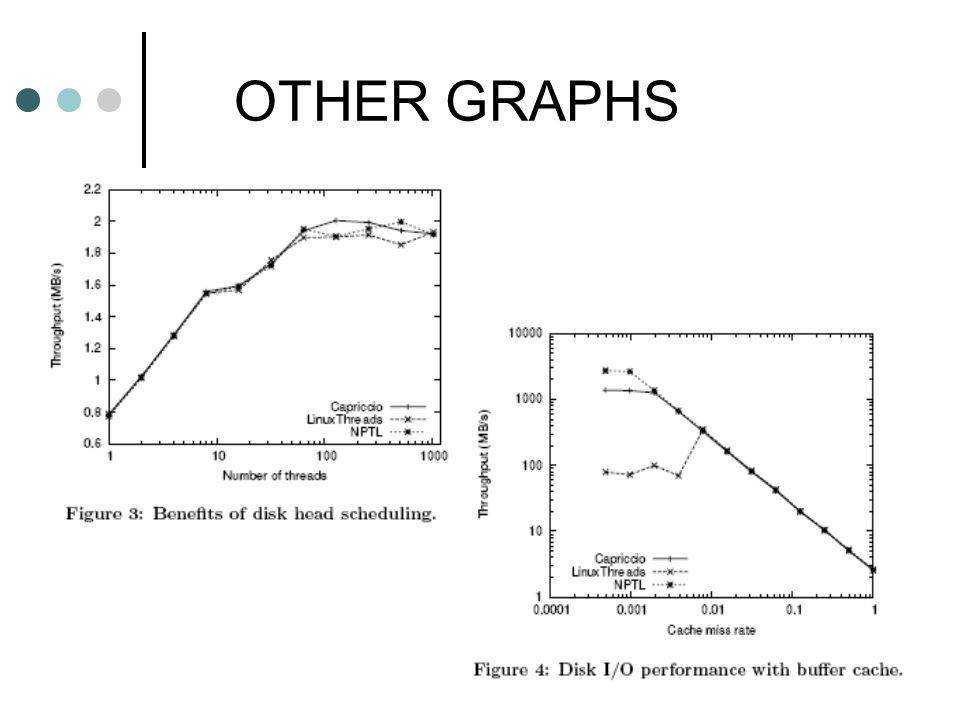
OTHER GRAPHS

Similar presentations




 Unit of dispatch or scheduling (thread.>")

 By Rob von Behren, Jeremy Condit and Eric Brewer.>")
 Presented by Alex Sherman and Sarita Bafna.>")

 Kenneth Chiu.>")



 –Processes must communicate with one another.>")





