Download presentation
Presentation is loading. Please wait.

1
Susan Finger and Sharad Oberoi Carnegie Mellon University ArtifactWebs: Navigable Product Structures

2
Collaborative learning in design Goal –Develop tools that encourage process competence, constructive skills, and reflective practice Web–based collaboration tool Meeting capture and summarization Navigable artifact webs

3
Collaborative learning in design Goal –Develop tools that encourage process competence, constructive skills, and reflective practice Web–based collaboration tool Meeting capture and summarization Navigable artifact webs

4
Collaborative learning in design Assertions –Most learning in design classes takes place in team meetings and in individual activities undertaken to help meet team goals –Argumentation, co-construction, and reflection are important elements of collaborative learning

5
Outline Setting –Engineering design capstone course –Ongoing project to understand collaborative learning by student design teams

6
Engineering design capstone course Required for all accredited engineering programs in US Commonly stated goal: Students should synthesize all the engineering knowledge they have acquired as undergraduates

7
Engineering design course projects The projects are usually: –Team-based –Company-sponsored (or client-driven) –Non-competing (each team has an independent project) –Often taught by academics with little project experience and even less design experience The grade is usually based on –The quality of the final product –The self-reported quality of the team interactions
 –Non-competing (each team has an independent project) –Often taught by academics with little project experience and even less design experience The grade is usually based on –The quality of the final product –The self-reported quality of the team interactions")
8
Engineering design course projects Students –are novices in their domain knowledge –are novices in their knowledge of the design process –often judge their success by the grade they earn or by the artifacts they produce Teacher –rarely plans to use the team’s design directly –usually does not attend group meetings –often does not know if a feasible solution exists to the design problem as stated

9
Engineering design course projects Team membership can change over time, so it is difficult to keep track of the progress as well as the options explored Inherent temptation to start the work over from scratch, wasting time and resources These problems exist for both industry and student teams, but are usually more severe for student teams

10
Engineering design course projects assessmentactivities learning goals

11
Collaborative learning research group Our focus is to develop tools that encourage process competence, constructive skills, and reflective practice –Need to capture process to understand student learning –Collaboration tools designed for industry rarely work well for student teams –Sequence of two National Science Foundation grants on collaborative learning in design

12
NSF Grant: Collaborative Learning across Time and Space Goal: To take advantage of advances in mobile computing to create collaboration tools for student design teams Means: Create an environment that –facilitates group collaboration for students –enables faculty to peer into the collaborative learning process Hook: Students design the tools they need for their own collaboration

13
Kiva collaboration tool Takes advantage of students willingness to send email, use IM, post on newsgroups, send text messages Design goal: Create an interface that students perceive to be equivalent to their preferred communication modes; that is: make it feel like chat

14
Design education testbed RPCS: Rapid prototyping of computer systems –Interdisciplinary, capstone design course –Ambitious projects, e.g. GM companion car-driver interface Context aware cell-phone Wireless classroom on the Voyager science boat

15
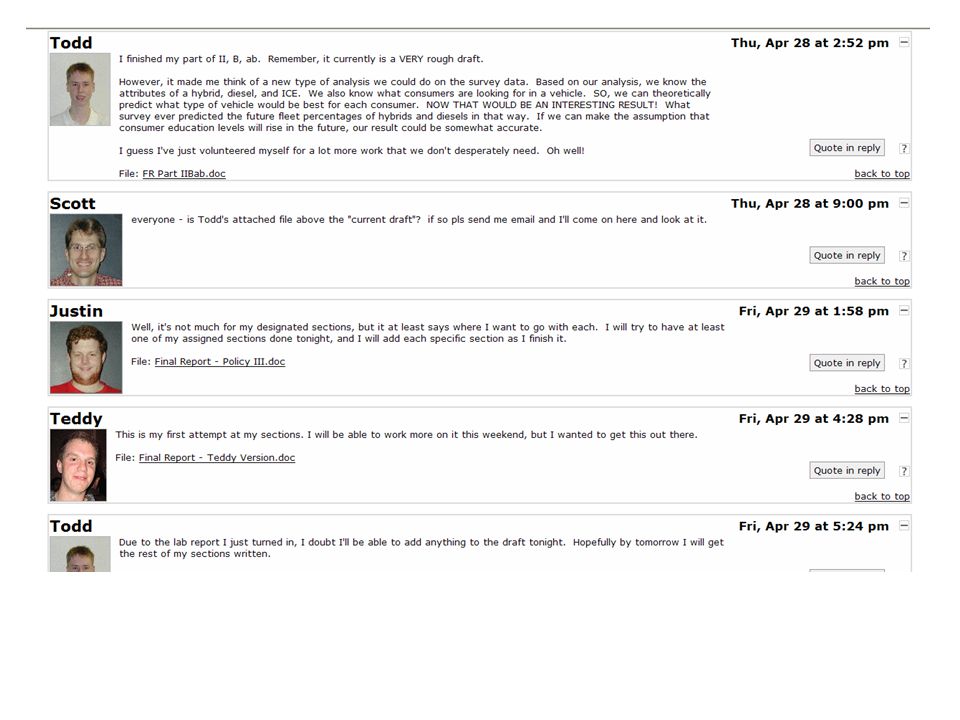
Capturing in-process data For 4 years, RPCS has used the Kiva for team collaboration –Light-weight collaboration tool –Combines functions of e-mail and bboards –Widely accepted and liked by student teams; it feels likes chat and meets their needs –Each year’s Kiva has hundreds of threads and thousands of posts and files We have 4 years of data of all the team conversations and files that would normally go through email or chat

17
Alan I was asking which formula you wanted to use. which comes down to which regression line we are using to map from the fuel values to RPM. I used : y = 327.89x3 - 2194.6x2 a 5087.4x - 2719.1. R2 = 0.9997 KimAh I see.. To be quite honest, I was planning on discussing this issue during class for tomorrow. For now we can just use the one that you wrote above and we will talk more about it during tomorrow's lecture. Thanks!! Chris It also might be good to do something as a special case in the formula so that we don't return a negative number for low values of fuel consumption. It looks really weird in the dashboard. ;) Alanhehe.. Right. Thanks for testing that. : AlanKim: I switched formulas. Now I am using this one. y = -1812.5x4 + 6744.9x3 - 8322.2x2 + 4325.9x + 4.1796. R2 = 0.9993. This is because I had to re-center the data to 0, and this new formula works much better then the alternatives. This is engine 1 I think. (the first set of numbers) AlanSigh.. another new formula. Forgot the upper bound. y = - 81.054x3 + 311.21x2 + 396.24x - 10.003. R2 = 0.9859
 Alanhehe.. Right. Thanks for testing that. : AlanKim: I switched formulas. Now I am using this one. y = x x x x R2 = This is because I had to re-center the data to 0, and this new formula works much better then the alternatives. This is engine 1 I think. (the first set of numbers) AlanSigh.. another new formula. Forgot the upper bound. y = x x x R2 =")
18
Kiva usage How do students use the Kiva? –Group coordination (18%) –Knowledge and work exchange (33%) –Preparation of deliverables (24%) –Other (25%)
 –Knowledge and work exchange (33%) –Preparation of deliverables (24%) –Other (25%).")
19
ADEPT - Assessing Design Engineering Projects Classes with Multi-disciplinary Teams Develop a physical infrastructure that enables the capture of synchronous and asynchronous interactions of student design teams –The (complete) up-to-date record of all of a team’s interactions will enable us to create ArtifactWebs that integrate and summarize team communications –The ArtifactWebs will provide traceability and accountability for individual contributions to shared knowledge –The ArtifactWebs will enable facilitated improvement of engineering design courses (i.e. the instructor will know when to intervene)
.")
20
Capturing in-process data This year, we collected audio files of meetings –Individual speaker –Automated speech to text transcripts –Observation and coding of all team meetings We have 1 year of data of team conversations (with many gaps)
")
21
Objectives To create ArtifactWebs that –represent the state of the project based on the artifacts described in the project documents –enable designers to search and navigate to find relevant information quickly and efficiently –evolve as the artifact, and the documents about it, evolve.

22
Design documentation Design project documents are generated by different team members at different times during a project, so no one is aware of everything that is in all the documents Locating the right information among evolving documents or reference documents can be time consuming Even for teams with well-structured document management systems, finding the correct paragraph or document fragment for a given topic can be difficult

23
Visionary Scenario A student in the wearable computer class is working on developing a text to speech module for a mobile device. Someone tells her that last year’s class developed an OCR (optical character recognition) module for the Trinetra project. She accesses the Trinetra DesignWeb through the class web space.
 module for the Trinetra project. She accesses the Trinetra DesignWeb through the class web space..")
24
Visionary Scenario She quickly searches (using standard search) to find the subweb for the OCR module. She then browses within the OCR module exploring various aspects of the OCR design from the previous team.

25
Visionary Scenario Finally she focuses on the modules on the mobile device. She reads the segment of the final report on the OCR mobile module as well as some of the supporting documents that led to the final decisions in the OCR design.

26
Challenges Levels of abstraction Alternate views for different users Credibility of source (transcripts of meetings vs. final reports) Identifying the structure of created knowledge, especially for different versions of the same document Identifying the design intent
 Identifying the structure of created knowledge, especially for different versions of the same document Identifying the design intent.")
27
Strategy overview Divide documents into topic segments Cluster segments by semantic similarity (e.g. revisions of same paragraph or similar paragraphs from different sources) Summarize each cluster Create a diagram that connects the key words in the document summaries Develop graphical display algorithms that enable users to search and navigate the graphs to access the underlying documents
 Summarize each cluster Create a diagram that connects the key words in the document summaries Develop graphical display algorithms that enable users to search and navigate the graphs to access the underlying documents.")
28
Segmentation Divide documents into topic segments –use the explicit structure of the documents (table of contents and internal headings) –use existing text segmentation algorithms such as TextTiling, which performs semantic clustering of terms and topic identification based on clustering Issue: Size of segments (big or little chunks)
 –use existing text segmentation algorithms such as TextTiling, which performs semantic clustering of terms and topic identification based on clustering Issue: Size of segments (big or little chunks)")
29
Clustering Cluster segments by semantic similarity (e.g. revisions of same paragraph or similar paragraphs from different sources) –InfoMagnets, created by Rosé, uses Latent Semantic Analysis and document clustering to automatically generate a bubble diagram, which a user can then incrementally adjust through the interface. Issue: Non-standard vocabulary across disciplines
 –InfoMagnets, created by Rosé, uses Latent Semantic Analysis and document clustering to automatically generate a bubble diagram, which a user can then incrementally adjust through the interface. Issue: Non-standard vocabulary across disciplines.")
30
Summarizing Summarize each cluster –Summarization is widely used in web searches –Many potential summarization algorithms exist Issues: What types of summaries are useful for designers and what types are useful for creating the graphs

31
Graphing Create a diagram that connects the key words in the document summaries –Use co-word analysis to find relationships among the key words in the document summaries Issues: Level of granularity and strength of relationships

32
Visualizing Develop graphical display algorithms that enable designers to search and navigate the graphs to access the underlying documents Issues: Algorithm and interface design

33
Design teams documents Auto-summarization Summarized fragments Document fragments Network of versioned fragments Collocation analysis Version matching Credibility mapping Document structure and associated metadata

34
Design teams documents Auto-summarization Summarized fragments Document fragments Network of versioned fragments Collocation analysis Version matching Credibility mapping Document structure and associated metadata

35
Design teams documents Auto-summarization Summarized fragments Document fragments Network of versioned fragments Collocation analysis Version matching Credibility mapping Document structure and associated metadata

36
Conclusions Creating ArtifactWebs automatically from student design documents is useful for organizing the information into product structures. These product structures can be used for developing computational environments that support systematic modeling and also for characterizing design problems. ArtifactWebs can help us understand the content and nature of information related to various aspects of the artifact and how designers generate and refine it.

37
Questions?

38
Prior work Previous work on automatic topic segmentation has focused on segmentation of expository text written by professionals –technical articles, such as journal papers –non-technical articles (e.g. blogs) –multi-party dialogues in a synchronous (e.g. chat) or asynchronous environment (e.g. discussion-boards) Student project reports do not come under any of these categories Nobody has evaluated student design reports that are often characterized by their authors’ lack of experience in technical writing
 –multi-party dialogues in a synchronous (e.g. chat) or asynchronous environment (e.g. discussion-boards) Student project reports do not come under any of these categories Nobody has evaluated student design reports that are often characterized by their authors’ lack of experience in technical writing.")
39
Proposed Solution Navigable ArtifactWebs that will: –Aid instructors and students alike by giving them a bird’s eye view of the evolving design. –Enable team members to explore the ideas that have been generated during the design process, the connections between the ideas, and the evolution of the ideas. –Direct the users to the relevant fragment of a document that contains the detailed discussion of an idea, in addition to searching the relevant topics using a query-based approach.

40
Challenges Levels of abstraction Alternate views for different users Credibility of source (transcripts of meetings vs. final reports) Identifying the structure of created knowledge, especially for different versions of the same document Identifying the design intent
 Identifying the structure of created knowledge, especially for different versions of the same document Identifying the design intent.")
41
Background Two broad categories of previous work in topic segmentation: 1.Lexical Cohesion Models: based on the central idea that the segmentation of text is guided primarily by distribution of terms used in it, in contrast to using cue words for the purpose. Examples: TextTiling (Hearst, 1997) and Latent Semantic Analysis (Landauer and Dumais, 1997) 2.Content-oriented Models: based on the evaluation of reoccurrence of topic patterns over multiple thematically similar discourses. Examples: Approaches based on Hidden Markov models (Barzilay et al, 2004).
 and Latent Semantic Analysis (Landauer and Dumais, 1997) 2.Content-oriented Models: based on the evaluation of reoccurrence of topic patterns over multiple thematically similar discourses. Examples: Approaches based on Hidden Markov models (Barzilay et al, 2004)..")
42
TextTiling (Hearst, 1997) 1.Block comparison approach: Adjacent pairs of text blocks are compared for overall lexical similarity. The sentences are grouped into blocks of size N/2 each, where the more the terms are similar to each other in the two blocks, the higher the lexical score we get at the gap between them. 2.Vocabulary introduction approach: Adjacent pairs of text blocks are compared for overall lexical dissimilarity. The sentences are grouped into blocks of size N/2 each, where the more thematically unrelated terms are introduced, the higher the lexical score we get at the gap between them.

43
TextTiling (Contd) 3.Lexical chain-based approach: Adjacent pairs of text blocks are compared for identifying the number of active chains, or terms that repeat within threshold sentences and span the sentence gap. This approach is based on the assumption that when a term is repeated in a more or less short distance (called a hiatus), a lexical chain is created between these two occurrences. Thematic boundaries are set in the text at places where the number of chains is minimal. This approach attempts to segment texts at places where the local cohesion is the lowest.
, a lexical chain is created between these two occurrences. Thematic boundaries are set in the text at places where the number of chains is minimal. This approach attempts to segment texts at places where the local cohesion is the lowest..")
44
Museli (Arguello et al,2006) Used for evaluating dialogues. It combined evidence of topic shifts from lexical cohesion with linguistic evidence such as syntactically distinct features. It used unigrams, bigrams, POS-tagging and lexical scores as the features to solve the segmentation problem as a binary classification problem where each contribution is classified as NEW_TOPIC if the contribution introduces a new topic and SAME_TOPIC otherwise.

45
Three degenerative approaches a)Classifying all contributions as NEW_TOPIC (ALL), b)Classifying no contributions as NEW_TOPIC (NONE), c)Classifying contributions as NEW_TOPIC at uniform intervals (EVEN), corresponding to the average reference topic length
Classifying all contributions as NEW_TOPIC (ALL), b)Classifying no contributions as NEW_TOPIC (NONE), c)Classifying contributions as NEW_TOPIC at uniform intervals (EVEN), corresponding to the average reference topic length")
46
Experiments Data Source: Documents created by students in the Rapid Prototyping of Computer Systems classes at Carnegie Mellon as our data-set.

47
Experiments Evaluation Metrics: a)P k measure determines the probability of misclassifying two contributions a distance of k contributions apart from each other by determining if they constitute the same topic segment or not. Lower P k values are preferred over higher ones. b)F-measure refers to the weighted harmonic mean of precision and recall.
F-measure refers to the weighted harmonic mean of precision and recall..")
48
Experiments (Contd) Gold Standard: We use the section and sub-section headings for student documents as tags for different student document fragments and the boundaries between them as the correct segmentation locations.
 Gold Standard: We use the section and sub-section headings for student documents as tags for different student document fragments and the boundaries between them as the correct segmentation locations.")
49
Experiments (Contd) Methodology: 1.TextTiling: Block comparison approach 2.Museli: Naïve Bayes classifier with an attribute selection wrapper and the Chi-square test for ranking the attributes using 10-fold cross-validation. [All along we were careful not to include instances from the same document in both the training and test sets on any fold so that the results would not be biased.] We trained a model with the top 1000 features, and applied that trained model to the test data. 3.Three degenerative approaches

50
Results TextTiling works best, while Museli worked worst.

51
Conclusions TextTiling was designed to partition texts into contiguous, non-overlapping subtopic segments. So it works best for segmenting student design documents. Naïve Bayes algorithm works best when there is much more training data available than what we provided, and where the documents are more stratified, so there is less chance of overlapping words in each category. The degenerative approaches give us a baseline for what happens with regular segmentation regardless of the content.

52
Possible weak points in our approach Stoplist could be customized for each document. Lemmatization removed words with the same root, but this may have implications on engineering design documents.

53
Summary We evaluated the approaches considered successful for automated topic segmentation of monolithic text written by professional authors and multi-party dialogues to the documents written by students as part of their project- based courses.

54
Future/Ongoing Work

55
We plan to evaluate the implementation of content-oriented models used successfully for a series of thematically similar discourses (such as a number of newspaper articles about similar events) for different versions of student design documents. Since these approaches greatly rely on the structure of the document for successfully implementing the topic segmentation, having student documents characterized by a lack of such explicitly defined structures would be interesting. We believe that such evaluations will slowly but steadily help us move towards achieving the vision of ArtifactWebs.

56
Thanks!

57
2002 NSF grant Team-Based Design: Collaboration Across Time and Space –Daniel P. Siewiorek, Susan Finger and Asim Smailagic –Combined Research and Curriculum Development Grant

58
Kiva vision Rapid Prototyping of Computer Systems –25 students primarily from engineering, and also from design, English, HCI designed, developed, integrated, and tested an environment for student team work –In their visionary scenario, the Kiva is an interactive physical and digital workspace that addresses the requirements of interdisciplinary teams. It is the digital equivalent of a dedicated project room.

59
Kiva vision

60
First implementation

61
Second iteration

62
Assessment strategy Pre and post essays on design process Pre and post domain knowledge tests Focus groups Coding and analysis of the posts

63
Proposed Solution Navigable ArtifactWebs that will: –Aid instructors and students alike by giving them a bird’s eye view of the evolving design. –Enable team members to explore the ideas that have been generated during the design process, the connections between the ideas, and the evolution of the ideas. –Direct the users to the relevant fragment of a document that contains the detailed discussion of an idea, in addition to searching the relevant topics using a query-based approach.

64
Potential Benefits to Members Ability to find information in documents from prior designs Ability to track a design-in-progress through the completeness of its DesignWeb

Similar presentations














 Testing Visual Information Retrieval Methodologies.>")




