Download presentation
Presentation is loading. Please wait.

1
Experiments Pre and Post condition

2
Classic experimental design
Random assignment to control and treatment conditions Why random assignment and control groups?

3
Classic experimental design
Random assignment helps with internal validity Some threats to internal validity: Experimenter/Subject expectation Mortality bias Is there an attrition bias such that subjects later in the research process are no longer representative of the larger initial group? Selection bias Without random assignment our treatment effects might be due to age, gender etc. instead of treatments Evaluation apprehension Does the process of experimentation alter results that would occur naturally? Classic experimental design when done properly can help guard against many threats to internal validity

4
Classic experimental design
Posttest only control group design: Experimental Group R X O1 Control Group R O2 With random assignment, groups should be largely equivalent such that we can assume the differences seen may be largely due to the treatment

5
Classic experimental design
Special problems involving control groups: Control awareness Is the control group aware it is a control group and is not receiving the experimental treatment? Compensatory equalization of treatments Experimenter compensating the control group's lack of the benefits of treatment by providing some other benefit for the control group Unintended treatments The ‘Hawthorne’ effect (as it is understood though not actually shown by the original study) might be an example
 might be an example.")
6
Mixed design: prepost experiments
Back to our basic control/treatment setup A common use of mixed design includes a pre-test post test situation in which the between groups factor includes a control and treatment condition Including a pretest allows: A check on randomness Added statistical control Examination of within-subject change 2 ways to determine treatment effectiveness Overall treatment effect and in terms of change

7
Pre-test/Post-test Random assignment
Observation for the two groups at time 1 Introduction of the treatment for the experimental group Observation of the two groups at time 2 Note change for the two groups

8
Mixed design 2 x 2 Between subjects factor of treatment
Pre Post treatment treatment treatment treatment control control control control 2 x 2 Between subjects factor of treatment Within subjects factor of pre/post Example

9
SPSS output Why are we not worried about sphericity here?
No main effect for treatment (though “close” with noticeable effect) Main effect for prepost (often not surprising) Interaction
 Main effect for prepost (often not surprising) Interaction.")
10
Interaction The interaction suggests that those in the treatment are benefiting from it while those in the control are not improving due to the lack of the treatment

11
Another approach: t-test
Note that if the interaction is the only thing of interest, in this situation we could have provided those results with a simpler analysis Essentially the question regards the differences among treatment groups regarding the change from time 1 to time 2. t-test on the gain (difference) scores from pre to post
 scores from pre to post.")
12
T-test vs. Mixed output t2 = F

13
Another approach: ANCOVA
We could analyze this situation in yet another way Analysis of covariance would provide a description of differences among treatment groups at post while controlling for individual differences at pre* Note how our research question now shifts to one in which our emphasis is in differences at time 2, rather than describing differences in the change from time1 to time 2 *If the ‘controlling for’ recalls the language of regression for you, note that is the best way to think about it, specifically a sequential regression in which the covariate (here the pre-test scores) goes in the model first, followed by the grouping variable, with the post-test as the outcome. This is not an analogy, they are equivalent.
 goes in the model first, followed by the grouping variable, with the post-test as the outcome. This is not an analogy, they are equivalent.")
14
Special problems of before-after studies
Instrumentation change Variables are not measured in the same way in the before and after studies. A common way for this to occur is when the observer/raters, through experience, become more adept at measurement. History (intervening events) Events not part of the study intervene between the before and after studies and have an effect Maturation Invalid inferences may be made when the maturation of the subjects between the before and after studies has an effect (ex., the effect of experience), but maturation has not been included as an explicit variable in the study. Regression toward the mean If subjects are chosen because they are above or below the mean, one would expect they will be closer to the mean on re-measurement, regardless of the intervention. For instance, if subjects are sorted by skill and then administered a skill test, the high and low skill groups will probably be closer to the mean than expected. Test experience The before study impacts the after study in its own right, or multiple measurement of a concept leads to familiarity with the items and hence a history or fatigue effect.
 Events not part of the study intervene between the before and after studies and have an effect. Maturation. Invalid inferences may be made when the maturation of the subjects between the before and after studies has an effect (ex., the effect of experience), but maturation has not been included as an explicit variable in the study. Regression toward the mean. If subjects are chosen because they are above or below the mean, one would expect they will be closer to the mean on re-measurement, regardless of the intervention. For instance, if subjects are sorted by skill and then administered a skill test, the high and low skill groups will probably be closer to the mean than expected. Test experience. The before study impacts the after study in its own right, or multiple measurement of a concept leads to familiarity with the items and hence a history or fatigue effect.")
15
Pre-test sensitization
So what if exposure to the pretest automatically influences posttest results in terms of how well the treatment will have its effect? Example: Attitudes about human rights violations after exposure to a documentary on the plight of Tibet Pretests: questions about attitudes human rights violations Initial Awareness State More empathic response to the film Scores on post-test that might reflect a greater treatment effect

16
Solomon 4-group design A different design can allow us to look at the effects of a pretest

17
Solomon 4-group design R X O R O R O X O R O O
Including a pretest can sensitize participants and create a threat to construct validity. Combining the two basic designs creates the Solomon 4-group design, which can determine if pretest sensitization is a problem: R X O R O R O X O R O O If these two groups are different, pretest sensitization is an issue. Pre X Treatment interaction If these two groups are different, there is a testing effect in general.

18
Solomon 4-group design Why not used so much? Requires more groups
However, it has been show that this does not mean more subjects necessarily Even if overall N maintained with switch to S4, may have more power than a posttest only situation Not too many interested in pretest sensitization Regardless one should control for it when possible, just like we’d control for other unwanted effects Complexity of design and interpretation Although understandable, as usual this is not a good reason for not doing a particular type of analysis Lack of understanding of how to analyze How do we analyze it?

19
Solomon 4-group design We could analyze the data in different ways
For example: One-way ANOVA on the four post-test results Treat all four groups as part of a 4 level factor Contrast treatment groups vs. non This would not however allow for us to get a sense of change/gain

20
Alternative approach (Braver & Braver)
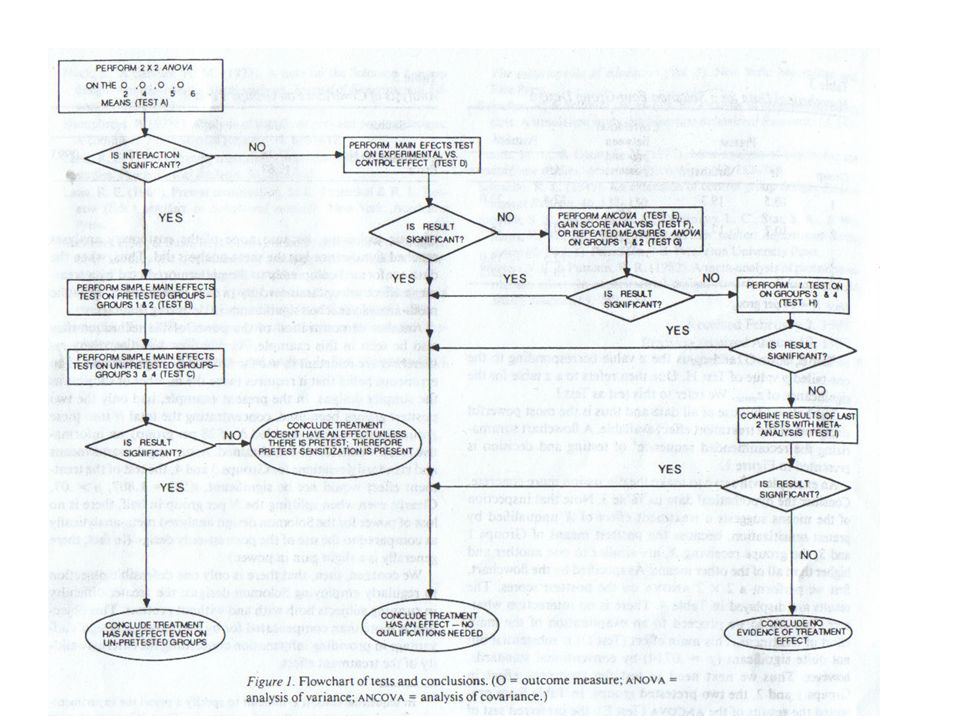
2 x 2 Factorial design with control/treat, pre/not as two between subjects factors Test A: Is there an interaction? Significant interaction would suggest pretest effect Effect of treatment changes depending on whether there is pretest exposure or not

21
Simple effects Test B & C: simple effects
B: Treatment vs Control at Prepresent C: Treatment vs Control at Preabsent In other words, do we find that the treatment works but only if pretest? O2 > O4, O5 = O6 If so, terminate analysis The treatment effects are due to pretest

22
Simple effects However, could there be a treatment effect in spite of the pretest effect? In other words, could the pretest merely be provide an enhancement of the treatment Ex. Kaplan/Princeton Review class helps in addition to the effect of having taken the GRE before If the other simple effect test C is significant also (still assuming sig interaction) we could conclude that was the case
 we could conclude that was the case.")
23
Non-significant interaction
If there is no interaction to begin with, check the main effect of treatment (test D) If sig, then treatment effect w/o pretest effect However this is not the most powerful course of action, and if not sig may not be indicative of no treatment effect because we would be disregarding the pre data (less power)
 If sig, then treatment effect w/o pretest effect. However this is not the most powerful course of action, and if not sig may not be indicative of no treatment effect because we would be disregarding the pre data (less power)")
24
Non-significant interaction: alternatives to testing treatment main effect
Better would be to use analysis of covariance that takes into account differences among individuals at pretest (Test E) T-test on gain/difference scores (Test F) Or mixed design (Test G) Between groups factor of Treatment Within groups factor of Pre-Post As mentioned, F and the interaction in G are identical to one another However test E will more likely have additional power
 T-test on gain/difference scores (Test F) Or mixed design (Test G) Between groups factor of Treatment. Within groups factor of Pre-Post. As mentioned, F and the interaction in G are identical to one another. However test E will more likely have additional power.")
25
Ancova We can interpret the ANCOVA as allowing for a test of the treatment after posttest scores have been adjusted for the pretest scores Basically boils down to: What difference at post would we see if the participants had scored the same at pre? We are partialling out the effects of pre to determine the effect of the treatment on posttest scores

26
In SPSS The ancova (or other tests) will only concern groups one and two as they are the only ones w/ pre-tests to serve as a covariate or produce difference scores for the mixed design/t-test approach
 will only concern groups one and two as they are the only ones w/ pre-tests to serve as a covariate or produce difference scores for the mixed design/t-test approach.")
27
If the Ancova results (or test F or G) show the treatment to still have an effect, we can conclude that the treatment has some utility beyond whatever effects the pre-test has on the post-test If that test is not significant however, we may perform yet another test

28
Test H t-test comparing groups 3 and 4 (O5 vs.O6) Less power compared to others (only half the data and no pre info) but if it is significant despite the lack of power we can assume some treatment effect
 but if it is significant despite the lack of power we can assume some treatment effect.")
29
Meta-analysis Even if this test is not significant, Braver & Braver (1988) suggest a meta-analytic technique that combines the results of the previous two tests (test E, F or G and that of H) Note how each is done only with a portion of the data More power from a consideration of all the data Take the observed p-value from each test, convert to a one-tailed z-score, add the two z-scores and divide by √2 (i.e. the number of z-scores involved) to give zmeta If that shows significance* then we can conclude a treatment effect Nowadays might want to use effect size r or d for the meta-analysis (see Hunter and Schmidt) as there are obvious issues in using p-values One might also just examine the Cohen’s d for each (without analysis) and draw a conclusion from that *A two-tailed probability is given for zmeta
 suggest a meta-analytic technique that combines the results of the previous two tests (test E, F or G and that of H) Note how each is done only with a portion of the data. More power from a consideration of all the data. Take the observed p-value from each test, convert to a one-tailed z-score, add the two z-scores and divide by √2 (i.e. the number of z-scores involved) to give zmeta. If that shows significance* then we can conclude a treatment effect. Nowadays might want to use effect size r or d for the meta-analysis (see Hunter and Schmidt) as there are obvious issues in using p-values. One might also just examine the Cohen’s d for each (without analysis) and draw a conclusion from that. *A two-tailed probability is given for zmeta.")
31
Problems with the meta-analytic technique for Solomon 4 group design
Note that the meta-analytic approach may not always be the more powerful test depending on the data situation Sawilosky and Markman (1990) show a case where the other tests are sig meta not Also, by only doing the meta in the face of non significance we are forcing an inclusion criterion for the meta (selection bias)
 show a case where the other tests are sig meta not. Also, by only doing the meta in the face of non significance we are forcing an inclusion criterion for the meta (selection bias)")
32
Problems Braver and Braver acknowledge that the meta-analytic technique should be conducted regardless of the outcomes of the previous tests If test A & D nonsig, do all steps on the right side However they note that the example Sawilosky used had a slightly negative correlation b/t pre and post for one setup, and an almost negligible positive corr in the other, and only one mean was significantly different from the others Probably not a likely scenario Since their discussion the Braver and Braver approach has been shown to be useful in the applied setting, but there still may be concerns regarding type I error rate Gist: be cautious in interpretation, but feel free to use if suspect pre-test effects

33
MC’s summary/take 1. Do all the tests on the right side if test A and D nonsig If there is a treatment effect but not a pretest effect, the meta- analysis is more powerful for moderate and large sample sizes With small sample sizes the classical ANCOVA is slightly more powerful As the ANCOVA makes use of pretest scores, it is noticeably more powerful than the meta-analysis, whereas the t test is only slightly more powerful than the meta-analysis. When a pretest either augments or diminishes the effectiveness of the treatment, the ANCOVA or t test is typically more powerful than the meta-analysis. 2. Perhaps apply an FDR correction to the analyses conducted on the right side to control for type I error rate 3. Focus on effect size to aid your interpretation

34
More things to think about in experimental design
The relationship of reliability and power Treatment effect not the same for everyone Some benefit more than others Sounds like no big deal (or even obvious), but all of these designs discussed assume equal effect of treatment for individuals
, but all of these designs discussed assume equal effect of treatment for individuals.")
35
Reliability What is reliability?
Often thought of as consistency, but this is more of a by-product of reliability Not to mention that you could have perfectly consistent scores lacking variability (i.e. constants) for which one could not obtain measures of reliability Reliability really refers to a measure’s ability to capture an individual’s true score, to distinguish accurately one person from another on some measure It is the correlation of scores on some measure with their true scores regarding that construct
 for which one could not obtain measures of reliability. Reliability really refers to a measure’s ability to capture an individual’s true score, to distinguish accurately one person from another on some measure. It is the correlation of scores on some measure with their true scores regarding that construct.")
36
Classical True Score Theory
Each subject’s score is true score + error of measurement Obsvar = Truevar + Errorvar Reliability = Truevar/ Obsvar = 1 – Errorvar/ Obsvar

37
Reliability and power Reliability = Truevar/ Obsvar = 1 – Errorvar/ Obsvar If observed variance goes up, power will decrease However if observed variance goes up, we don’t know automatically what happens to reliability Obsvar = Truevar + Errorvar If it is error variance that is causing the increase in observed variance, reliability will decrease* Reliability goes down, Power goes down If it is true variance that is causing the increase in observed variance, reliability will increase Reliability goes up, Power goes down The point is that psychometric properties of the variables play an important, and not altogether obvious role in how we will interpret results, and not having a reliable measure is a recipe for disaster. *This is what one can typically assume to be the case in most research situations as we are not in an ‘all else being equal’ type of situation.

38
Error in Anova Typical breakdown in a between groups design
SStot = SSb/t + SSe Variation due to treatment and random variation (error) The F statistic is a ratio of these variances F = MSb/MSe
 The F statistic is a ratio of these variances. F = MSb/MSe.")
39
Error in Anova Classical True Score Theory
Each subject’s score = true score + error of measurement MSe can thus be further partitioned Variation due to true differences on scores between subjects and error of measurement (unreliability) MSe = MSer + MSes MSer regards measurement error MSes systematic differences between individuals MSes comes has two sources Individual differences Treatment differences Subject by treatment interaction
 MSe = MSer + MSes. MSer regards measurement error. MSes systematic differences between individuals. MSes comes has two sources. Individual differences. Treatment differences. Subject by treatment interaction.")
40
Error in Anova The reliability of the measure will determine the extent to which the two sources of variability (MSer or MSes) contribute to the overall MSe If Reliability = 1.00, MSer = 0 Error term is a reflection only of systematic individual differences If Reliability = 0.00, MSes = 0 Error term is a reflection of measurement error only MSer = (1-Rel)MSe MSes = (Rel)MSe
 contribute to the overall MSe. If Reliability = 1.00, MSer = 0. Error term is a reflection only of systematic individual differences. If Reliability = 0.00, MSes = 0. Error term is a reflection of measurement error only. MSer = (1-Rel)MSe. MSes = (Rel)MSe.")
41
We can test to see if systematic variation is significantly larger than variation due to error of measurement

42
Calculate an effect size (eta-squared)
With a reliable measure, the bulk of MSe will be attributable to systematic individual differences However with strong main effects/interactions, we might see sig F for this test even though the contribution to model is not very much Calculate an effect size (eta-squared) SSes/SStotal Lyons and Howard suggest (based on Cohen’s rules of thumb) that < .33 would suggest that further investigation may not be necessary How much of the variability seen in our data is due to systematic variation outside of the main effects? Subjects responding differently to the treatment
 SSes/SStotal. Lyons and Howard suggest (based on Cohen’s rules of thumb) that < .33 would suggest that further investigation may not be necessary. How much of the variability seen in our data is due to systematic variation outside of the main effects Subjects responding differently to the treatment.")
43
Summary Gist: discerning the true nature of treatment effects, e.g. for clinical outcomes, is not easy, and not accomplished just because one has done an experiment and seen a statistically significant effect Small though significant effects with not so reliable measures would not be reason to go with any particular treatment as most of the variance is due poor measures and subjects that do not respond similarly to that treatment One reason to perhaps suspect individual differences due to the treatment would be heterogeneity of variance For example, lots of variability in treatment group, not so much in control Even with larger effects and reliable measures, a noticeable amount of the unaccounted for variance may be due to subjects responding differently to the treatment Methods for dealing with the problem are outlined in Bryk and Raudenbush (hierarchical linear modeling), but one strategy may be to single out suspected covariates and control for them (ANCOVA or Blocking)
, but one strategy may be to single out suspected covariates and control for them (ANCOVA or Blocking)")
44
Resources Zimmerman & Williams (1986) Bryk & Raudenbush (1988)
Lyons & Howard (1991)
")
Similar presentations










-the General Linear Model (GLM)>")








